

What the next seven years could look like—and how to use it today
TL;DR. A clear way to track real‑world AI utility is its time horizon: the length of tasks (measured in human time) that an AI can finish with a given reliability. Recent measurements show that this horizon has doubled about every seven months since 2019. Today’s best generalist systems reliably handle tasks a human completes in ~50–60 minutes; they’re near‑certain on tasks under ~4 minutes and falter above ~4 hours. If the long‑running trend holds, day‑, week‑, and even month‑scale projects become automatable—with the right guardrails—over the next few years. metr.orgarXiv
METR-Horizon-v1: Long-Task Time Horizons by Model Release (log scale)
Why “time horizon” matters more than leaderboard scores
Traditional tests (quizzes, benchmarks) tell us whether a model knows things. They don’t tell us whether it can carry a multi‑step project from start to finish.
The time‑horizon metric fixes this by asking: How long a task—timed on real experts—can this AI reliably complete? On METR’s diverse, multi‑step software and reasoning suite, success is ~100% for “human‑under‑4‑minute” tasks and <10% for “human‑over‑4‑hour” tasks; the leading models cluster around a ~1‑hour 50% horizon. metr.org
Key point: METR finds the 50% horizon has risen exponentially with a ~7‑month doubling. A stricter 80% reliability horizon is shorter—roughly 5× shorter—but rises in parallel. metr.orgarXiv
AI Model Progress on METR-Horizon-v1 Benchmark
This graph shows the p50 horizon length of various AI models over time, using a logarithmic scale on the y-axis to highlight exponential growth. Hover over a point to see model details.
Top picks for "minut month ability"
Open Amazon search results for this keyword.
As an affiliate, we earn on qualifying purchases.
Diagram: The long‑task horizon, illustrated
- Horizon curve (log scale): shows a simple projection anchored to the March 19, 2025 baseline (~1‑hour 50% horizon) with a 7‑month doubling.
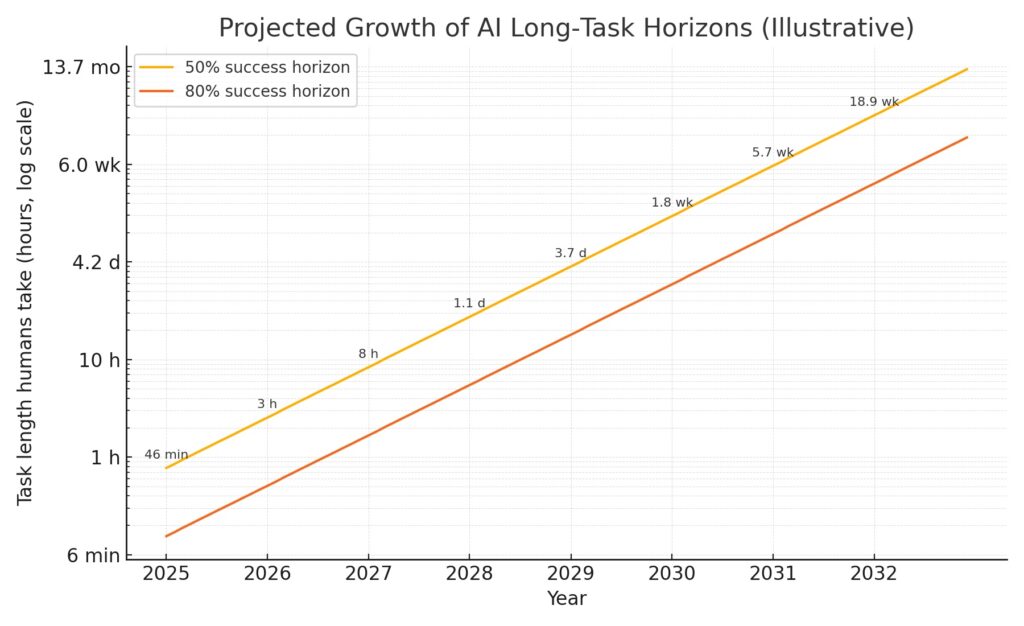
- Year‑by‑year bars: sample the 50% horizon on each “anniversary” (Mar 19).

Note: These visuals are illustrative (not METR’s original plots). They use METR’s reported doubling time and baseline to communicate the practical magnitude of change. metr.org
The next seven years (illustrative base case)
Assuming the ~7‑month doubling persists and using March 19, 2025 as time zero:
| Year (anniversary) | ~50% horizon (human‑time) | What becomes feasible (with tests & oversight) |
|---|---|---|
| 2025 | 1.0 hr | Short, well‑scoped tasks with strong checkers. |
| 2026 | 3.3 hr | “Day‑part” tickets; multi‑doc synthesis; small feature PRs with tests. |
| 2027 | 10.8 hr (~1 day) | End‑to‑end one‑day work packages and multi‑app tool use. |
| 2028 | 35.3 hr (~1.5 days) | Mini‑sprints: prototype features; full‑pipeline research → draft → figures. |
| 2029 | 116 hr (~4.8 days) | Week‑long projects: bug bash + triage across repos; AB test setup. |
| 2030 | 380 hr (~2.3 weeks) | Multi‑team integration, procurement cycles, compliance evidence collection. |
| 2031 | 1,248 hr (~7.4 weeks) | Month‑scale initiatives become hit‑and‑miss but tractable with scaffolding. |
| 2032 | 4,096 hr (~5.6 months) | Cross‑functional projects possible under strict guardrails & staged rollout. |

Independent coverage has drawn similar conclusions—while warning that any long‑range extrapolation deserves caution. Domain‑by‑domain analyses also suggest some areas may move faster or slower, but broadly continue on exponential tracks. Naturemetr.org
What this means for teams right now
You can’t wish a 6‑hour task into 6 minutes. But you can compress end‑to‑end time by (1) atomicizing work, (2) writing checkers before doers, and (3) shrinking the human loop to review/approval. This is where today’s systems shine—and where tomorrow’s will scale.
High‑leverage patterns
- Test‑oriented automation: Convert deliverables into code‑checkable artifacts (validators, linters, schema checks, golden examples).
- Self‑verification loops: The agent must explain its plan, run the checks, repair failures, then seek sign‑off.
- Parallelism by default: Fan‑out retrieval, candidate solutions, or data pulls; auto‑rank with your checkers.
- Policy & permissions: Least‑privilege keys, explicit “allowed actions,” auditable logs.
- Budgets & SLAs: Token/runtime/cost ceilings; auto‑stop on runaway jobs.
Reality check: A July 2025 study with experienced OSS developers found that naïve use of coding AIs could slow work; the fix was better scaffolding, tests, and workflow design—not abandoning AI. Build the runbook around the tool, not the other way around. metr.orgTIME
Drop‑in SOP checklist (copy‑paste)
Use this to convert recurring workflows into reliable, agent‑driven runbooks.
Download as Markdown:
1) Scope & safety
- Define the task boundary (inputs/outputs, success criteria, non‑goals)
- Assign a risk tier and required approvals
- Provide least‑privilege credentials
- List allowed tools and disallowed actions
2) Tests before tasks
- Create unit checks (validators, schema checks, linters)
- Add golden examples + edge cases
- Build an end‑to‑end test the agent must pass before “done”
3) Plan → Do → Verify loop
- Agent proposes a step‑by‑step plan and confirms assumptions
- Structured action logs (who/what/when/why)
- Self‑repair on failure with explanations and retries
- Human gate after tests and diffs pass
4) Parallelism & reuse
- Fan‑out long steps; rank results
- Save artifacts (plans, drafts, datasets, diffs) in an artifact store
- Have the agent search prior playbooks first
5) Budgets & SLA
- Set token/runtime/cost budgets + timeout
- Track success rate, retries, lead time per task type
- Auto‑escalate on stalling, policy violations, or low confidence
6) Deployment hygiene
- Staging‑first; promote via canaries & automated diffs
- Maintain audit trails (PII, data residency)
- Run blameless post‑mortems; update tests and playbooks
Sources & further reading
- METR, “Measuring AI Ability to Complete Long Tasks” (blog + figures, Mar 19, 2025) — time‑horizon method; ~7‑month doubling; success vs. task length. metr.org
- METR (arXiv), paper preprint — ~50‑minute 50% horizon for top models; 80% horizons ~5× shorter. arXiv
- Nature news, “AI could soon tackle projects that take humans weeks” — contextualizes forecasts, cautions on extrapolation. Nature
- METR, “How Does Time Horizon Vary Across Domains?” (Jul 14, 2025) — domain‑specific growth rates and possible acceleration. metr.org
- METR, developer productivity study and coverage — why workflow design matters for real‑world gains. metr.orgTIME






