A €189M Series B backs “quantum‑inspired” model shrinking that pushes powerful AI out of the cloud and onto everyday devices.
TL;DR
- Funding: Multiverse Computing raised €189 million (≈$215–217M) in June 2025, led by Bullhound Capital with strategic investors including HP Tech Ventures, Forgepoint Capital, Toshiba, and Santander Climate VC; total funding is now ~$250M. ReutersMultiverse ComputingTechCrunch
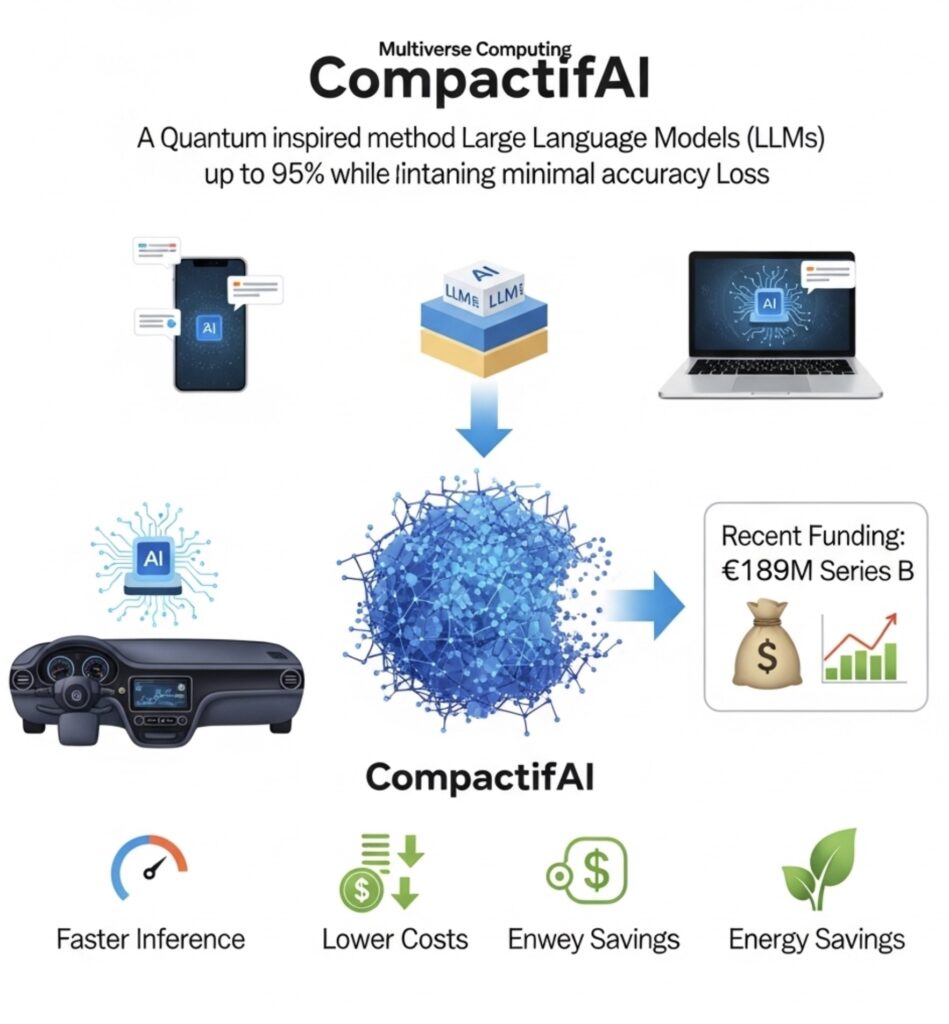
- The tech (CompactifAI): A quantum‑inspired tensor‑network method that shrinks leading open‑source LLMs (e.g., Llama, DeepSeek, Mistral) by up to ~93–95% while reporting only ~2–3% accuracy loss in benchmarks. arXivReuters
- Performance & cost: Vendor metrics claim 4×–12× faster inference and 50–80% lower inference costs; some model releases also cite up to 84% energy savings. Multiverse Computing+1The Quantum Insider
- Where it runs: Compressed models are built to run in the cloud, on‑prem, and on devices—from PCs and phones to cars, drones, and even Raspberry Pi—with offline demos shown. Multiverse ComputingTechCrunch
- Availability: Tools and models are accessible via AWS (Marketplace/API), making integration straightforward. ReutersTechCrunch
Why this matters
For a decade, AI deployment has trended toward ever‑larger models running on specialized, cloud‑based infrastructure—a choice that drives costs, energy use, and latency. Multiverse Computing’s CompactifAI challenges the assumption that you must trade accuracy for size: by using tensor networks (a technique borrowed from quantum physics) to compress a model’s correlation structure rather than just trim weights or lower precision, the company says it can keep accuracy high while drastically cutting memory and compute. If the results hold at scale, this could rebalance the economics of AI and expand where—and how—AI can run. ar5iv

Top picks for "multiverse comput compression"
Open Amazon search results for this keyword.
As an affiliate, we earn on qualifying purchases.
The funding: a European deeptech signal
On June 12, 2025, Multiverse announced a €189M Series B. The round was led by Bullhound Capital with participation from HP Tech Ventures, Forgepoint Capital International, CDP Venture Capital, Santander Climate VC, Quantonation, Toshiba, and Spanish public entities such as SETT and Grupo SPRI. Reuters reported the deal and noted that the raise positions Multiverse among Europe’s top AI players; the company itself says it has now raised about $250M since 2019. ReutersMultiverse Computing
Why that list matters: beyond capital, these investors bring distribution and hardware relationships (HP), industrial reach (Toshiba), and public‑sector momentum (SETT), all relevant to on‑device and edge deployments. Multiverse Computing
Rethinking model size: what CompactifAI does differently
Most compression today relies on quantization (fewer bits per weight) and pruning/distillation (fewer parameters), which often degrade accuracy at moderate compression ratios. CompactifAI instead tensorizes core layers—self‑attention and MLP—into matrix product operators and related tensor‑network forms. That lets engineers truncate only the least‑useful correlations and then briefly retrain to recover performance. In Multiverse’s paper and technical notes, a Llama‑2 7B example shows ~93% memory reduction with ~2–3% accuracy drop, while improving training speed (~50%) and inference speed (~25%) in that benchmark. ar5ivarXiv
Plain English: Instead of chopping neurons or only lowering numeric precision, CompactifAI re‑factorizes the weight tensors so the model remembers what matters most and forgets the rest—then fine‑tunes to clean up any errors. ar5iv
The numbers (so far)
- Compression: Up to ~93–95% size reduction on well‑known open models (e.g., Llama, DeepSeek, Mistral) according to the company. ReutersarXiv
- Accuracy: ~2–3% loss reported on internal/academic benchmarks after short retraining. arXiv
- Speed & cost: 4×–12× faster and 50–80% lower inference costs (company claims and press coverage). Multiverse ComputingThe Quantum Insider
- Energy: In April releases for Llama 3.x variants, Multiverse cited up to 84% better energy efficiency on those models. Multiverse Computing
Important caveat: these are vendor‑reported results. Independent assessments are still sparse, and recent research cautions that compression can alter uncertainty/variability if not carefully controlled—something buyers should test in their own pipelines. Frontiers
Where it runs—and why that’s a big deal
CompactifAI models are designed to run anywhere: cloud, on‑prem, and on device—including PCs, smartphones, cars, drones, and Raspberry Pi. TechCrunch’s reporting highlights offline demos (even voice interfaces on microcontroller‑class hardware), pointing to latency, resilience, and data‑locality benefits for factories, vehicles, and home appliances. Multiverse ComputingTechCrunch
Distribution is also practical: Reuters notes the technology is available in the AWS experience (Marketplace/AI marketplace), and TechCrunch mentions an AWS‑hosted API that developers can call. That lowers switching friction for teams already in the AWS ecosystem. ReutersTechCrunch
Adoption: from enterprise pilots to device makers
Multiverse says it is focusing on compressing the most‑used open models (e.g., the Llama family) to meet enterprise demand. Its public client roster skews industrial/financial—Bosch, BASF, Moody’s, Bank of Canada, Iberdrola, among others—and the company told TechCrunch it’s in talks with major device brands (Apple, Samsung, Sony, HP) to bring on‑device AI to consumer hardware. Note: “in talks” is not the same as signed partnerships. ReutersMultiverse ComputingTechCrunch
How it compares to the status quo
| Dimension | Typical quantization/pruning | CompactifAI (reported) |
|---|---|---|
| Compression | 50–60% with notable accuracy hit | Up to ~93–95% with ~2–3% accuracy drop |
| Speed/Cost | Mixed; may help throughput | 4×–12× faster; 50–80% cheaper inference |
| Energy | Varies by stack | Up to 84% savings (select models) |
Sources: Multiverse’s paper and releases; independent verification pending. arXivMultiverse Computing+1
What to watch next
- Independent benchmarks. Expect third‑party tests comparing CompactifAI against leading quantization/distillation toolchains across reasoning, safety, and hallucination metrics. Frontiers
- The edge AI land‑grab. If AWS distribution and device‑maker talks convert, Multiverse could help push offline AI into appliances, cars, and industrial equipment at scale. ReutersTechCrunch
- Model roadmap. The company continues to roll out compressed versions of popular open models; recent TechCrunch coverage also highlights ultra‑small “Model Zoo” releases (e.g., “SuperFly” and “ChickBrain”) aimed squarely at IoT and laptops. TechCrunch
Bottom line
Multiverse Computing’s CompactifAI blends quantum‑inspired math with practical engineering to shrink today’s widely used LLMs without the usual accuracy cliff—at least according to early results. The €189M war chest, AWS distribution, and traction with industrial/financial customers give the startup a credible path to production. If rigorous, third‑party benchmarks confirm these gains, 2025–2026 could mark a pivot from cloud‑first AI toward intelligent, ubiquitous, and cost‑efficient on‑device deployments. ReutersMultiverse Computing
Sources & further reading
- Reuters: funding, investor list, AWS availability, and focus on Llama/DeepSeek/Mistral. Reuters
- Multiverse press release: investor syndicate; 4×–12× speed, 50–80% cost claims; device/edge targets; ~$250M raised to date. Multiverse Computing
- Multiverse technical paper & notes (arXiv): tensor‑network method and benchmarked compression/accuracy. ar5ivarXiv
- TechCrunch (Aug 14, 2025): on‑device demos, “Model Zoo,” and talks with Apple/Samsung/Sony/HP; ~$250M total funding. TechCrunch
- Quantum Insider coverage: summary of speed/cost/edge claims. The Quantum Insider
- April 2025 model release: energy efficiency and model‑specific metrics for Llama 3.x variants. Multiverse Computing
Editor’s note: Performance and cost figures above are vendor‑reported unless otherwise indicated. Enterprises should benchmark on their own workloads—especially for safety, reliability, and uncertainty calibration—before scaling deployments.