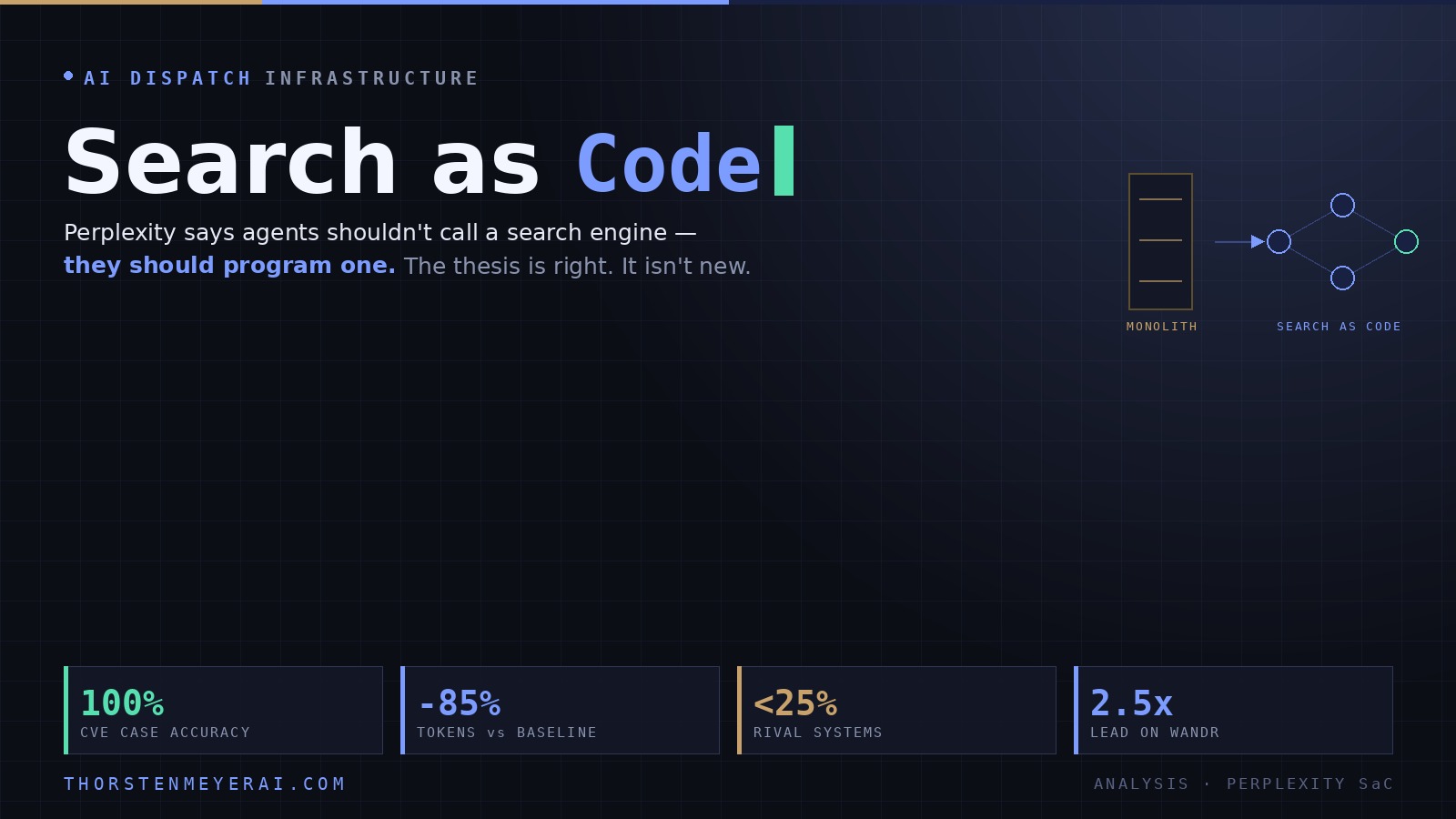

On June 1, 2026, Perplexity’s research team published a piece arguing that the way AI systems use search is fundamentally broken for the agent era, and proposed a fix it calls Search as Code (SaC). The short version: stop treating search as a vending machine that takes a query and returns a page of results, and start treating it as a library of primitives that an AI agent assembles into a custom retrieval program, on the fly, in code.
I think the core thesis is correct. I also think the framing quietly oversells how novel it is. Both things can be true, and the gap between them is the interesting part.
Search as Code
Perplexity says agents shouldn’t call a search engine — they should program one, composing atomic primitives into a bespoke pipeline in a sandbox. The thesis is right. It’s also the search-shaped version of an idea the field has been converging on since 2024.
Monolithic search
As an affiliate, we earn on qualifying purchases.
Programmable primitives
Directionally right, genuinely engineered — the rebuilt-from-atoms search stack is the part rivals can’t cheaply copy. But it’s a strong execution of an industry-wide idea, validated mostly on benchmarks Perplexity ran itself. The moat is the infrastructure and the tuning loops, not the architecture.

Orion Motor Tech Turbo Engine Timing Tool Kit Engine Camshaft Alignment Tool Set Compatible with 2009 to 2020 1.0 1.2 1.4L Chevrolet Chevy Aveo Cruze Orlando Vauxhall Opel Adam Ampera Astra J Cascada
- Engine Locking and Alignment: Holds engine at TDC for precise timing
- All-in-One Timing Kit: Includes camshaft, sensor, adjustment tools, and pins
- Universal Compatibility: Fits Chevrolet, Vauxhall, Opel models 2009-2020
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What Perplexity is actually claiming
The argument runs like this. Traditional search — even the AI-optimized kind Perplexity itself pioneered with its 2022 answer engine — inherited a human-era contract: accept a query, run a fixed pipeline, return a finished result set. That was fine when an AI made one query and read the answer. It breaks when an agent needs to complete a multi-hour task that fires off hundreds or thousands of retrieval operations per minute.
The bottleneck, they argue, is control. Models are already good at reasoning over context they’re handed. What they lack is the ability to steer how that context gets retrieved, filtered, ranked, and assembled. A monolithic search endpoint hides all of that behind query parameters. Everything downstream is rigid.
SaC’s answer is to expose the guts of the search stack — retrieval, ranking, filtering, fan-out, rendering — as atomic building blocks inside a Python SDK, then let the model write and execute code in a secure sandbox to wire those blocks into a pipeline tailored to each task. Crucially, Perplexity stresses this is not a search API stuffed into a shell. They rebuilt the stack into composable parts so the model can reach into it, not just consume its output.
Three layers make it work: the model as the control plane (deciding strategy and generating code), a sandbox for deterministic execution and cross-turn state, and the Agentic Search SDK as the primitive set. There’s a nice secondary insight here too — code isn’t only an orchestrator, it’s a gap-filler. Need a regex the search syntax can’t express? Don’t bloat the SDK; have the model fetch a superset in parallel and narrow it with a few lines of generated code.

The Android Developer's Cookbook: Building Applications with the Android SDK (Developer's Library)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The numbers they put forward
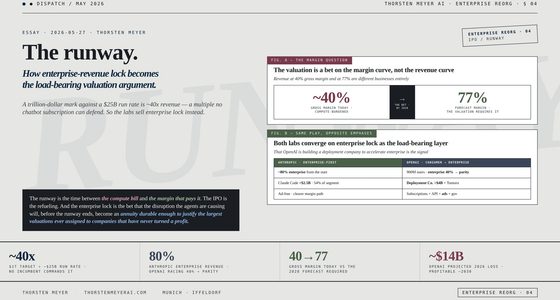
The persuasive centerpiece is a CVE case study: identify and characterize 200-plus high-severity vulnerabilities, each cited to the vendor’s own advisory and bound to a specific fix version. SaC’s run scored 100% accuracy while cutting token usage 85% — from 288.7K tokens down to 42.9K. The non-Perplexity systems they tested all scored under 25%.
The model’s strategy, reconstructed in their walkthrough, is a clean three-stage pattern: fan out over vendor-specific advisory query templates; use an LLM mid-pipeline to propose targeted refinements for thin spots; then run a schema-bound verifier that keeps only advisories tying one CVE to one product and one fix version. The point isn’t the CVEs — it’s that a model wrote a bespoke, multi-stage retrieval program instead of hammering one endpoint repeatedly.
On the broader benchmark suite, Perplexity reports SaC leading on four of five tests (DSQA, BrowseComp, WideSearch, and their new WANDR), tying OpenAI on the fifth (HLE), and beating the next-best system on WANDR by 2.5×. Against its own non-SaC baseline on the same infrastructure, SaC adds up to 20 points. The cost-performance plots show even the low-reasoning setting beating most rivals at lower cost.

How To Scale Without Spam: Build an AI-Native Marketing Team, Redesign Your Operations, and Deploy Custom Agents Using n8n, Claude, and ChatGPT
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Where my skepticism kicks in
This is a vendor research post about a product Perplexity is shipping today. To their credit, they flag the honest bits — single runs rather than best-of-N, an unsaturated benchmark, a tentative finding on state management. But three things deserve a raised eyebrow.
First, the benchmark where SaC wins biggest is one Perplexity built and hasn’t published yet. WANDR is described as inspired by the company’s own Computer product, and it’s the 2.5× headline. New, self-authored benchmarks where the author wins by the largest margin are exactly the results that need independent replication before anyone treats them as settled. The four pre-existing benchmarks are the more credible signal.
Second, the model lineup isn’t clean. SaC and the OpenAI comparison both run on GPT-5.5 (high reasoning), per the piece, while the Anthropic system runs on Opus 4.7. When you’re isolating an architecture, holding the model constant matters, and it isn’t fully held constant here. The comparison is suggestive, not airtight.
Third, and most importantly: this is a convergent idea, not a Perplexity invention — and the post’s “introducing Perplexity’s new reference architecture” framing soft-pedals that. The notion that agents should act by writing executable code rather than emitting JSON tool calls was formalized two years ago in the CodeAct paper (Wang et al., ICML 2024), which showed up to 20% higher success rates across 17 models for one simple reason: LLMs are trained on oceans of real code, while tool-call formats are synthetic and sparsely represented in training data. Hugging Face’s smolagents turned that into a ~1,000-line framework. Cloudflare shipped Code Mode. And in November 2025, Anthropic published “code execution with MCP,” making essentially the same argument Perplexity makes — that loading tool definitions and routing every intermediate result through the context window is the thing killing agents at scale — and reporting context reductions in the high-90s percent by turning tools into code APIs the model composes in a sandbox.
SaC is the search-specific instantiation of that pattern. The genuinely new and hard part is that Perplexity re-architected its own search stack down to atomic primitives, which is real engineering most others can’t replicate by wrapping an external API. But the conceptual ground — code as the action space, keep intermediate state out of the token stream, progressive disclosure of capabilities, sandboxed execution — was well trodden before June 2026.
The costs nobody’s eager to dwell on
Programmable search trades one set of problems for another, and the post is light on the second set.
You’re now executing model-generated code at scale, which is a meaningfully larger security and reliability surface than a fixed endpoint. Perplexity acknowledges sandboxing is hard enough to deserve its own article; that’s a tell. A model that writes a subtly wrong filter can silently drop the very results that mattered — “coarse context” gets replaced by “code that’s confidently incorrect,” and the second failure is harder to notice. Observability of a pipeline that fans out into thousands of opaque operations is a genuine open problem. Reproducibility suffers when every run synthesizes a different program. And codegen adds latency and output tokens even as it slashes input tokens — the net win is real but task-dependent.
Then there’s the strategic tension. Perplexity’s SDK is, by their own admission, not represented in pretraining data, so it needs bespoke Agent Skills (kept under 2,000 tokens) to teach models to use it. That’s a proprietary surface that cuts directly against the open, universal direction MCP was pushing. The more powerful and idiosyncratic your SDK, the more lock-in you create — which is good for Perplexity and worth a builder’s caution.
So what’s the actual moat?
If code-as-action is convergent, the architecture itself won’t stay differentiating; it’ll be table stakes within a year. The durable advantages are the things underneath it: the atomized search infrastructure (hard to build, harder to retrofit), the proprietary index and crawl, and the autoresearch loops Perplexity uses to continuously tune both the SDK and the Skills against real metrics. That last one — treating SDK ergonomics and agent skills as things you optimize with a closed feedback loop, possibly even co-evolving them with model training — is the most forward-looking idea in the piece and the one I’d watch most closely.
What it means if you build with this stuff
Strip away the vendor packaging and there’s a clean, portable lesson for anyone wiring up agents.
Expose your own internal capabilities — your scrapers, your databases, your enrichment steps, your house tooling — as atomic, composable primitives a coding agent can orchestrate in a sandbox, rather than as fat end-to-end endpoints. Keep bulky intermediate data out of the model’s context and let code shuttle it around. Invest in the skills-and-evals loop that teaches models to use your primitives well, because a custom SDK the model has never seen is useless without it. And weigh the lock-in: the more your agents depend on one provider’s non-standard SDK, the less portable your stack becomes — a real consideration if sovereignty or vendor independence matters to you.
The biggest-picture framing in the post is the one I’d keep. We’re moving toward a hybrid form of computing that fuses three things: token-space reasoning (models deciding what evidence is needed and how to resolve uncertainty), deterministic runtimes (the batching, parallelism, filtering, and aggregation that code does far better than a language model), and search infrastructure as a universal I/O layer into the world’s information. Search is just the first domain where the seams between those three are being engineered away. It won’t be the last.
The verdict
Perplexity is directionally right, and SaC is a serious piece of engineering rather than a blog-post stunt — the rebuilt-from-atoms search stack is the part competitors can’t cheaply copy. But the post reads as a strong execution of an industry-wide idea dressed as a singular breakthrough, validated largely by benchmarks the company ran itself, including the one it’s still finishing. Read it as a high-quality progress report from a leader in a fast-converging race — not as the moment search changed forever. That moment started two years ago, in a paper about JSON.
The headline isn’t “Perplexity reinvented search.” It’s “search is becoming a programmable library, every serious lab now agrees, and the winners will be decided by infrastructure and feedback loops — not by who published the cleverest blog post.”
Sources: Perplexity Research, “Rethinking Search as Code Generation” (June 1, 2026); Wang et al., “Executable Code Actions Elicit Better LLM Agents” (CodeAct, ICML 2024); Hugging Face smolagents; Cloudflare Code Mode; Anthropic, “Code execution with MCP” (Nov 2025). Benchmark figures and model configurations as reported by Perplexity. Analysis and opinions are the author’s.