

Interactive Slide Deck Included
Abstract
Artificial Intelligence has evolved from a theoretical concept to a transformative force reshaping industries, societies, and human interaction with technology. This comprehensive guide explores twelve critical aspects of modern AI, from fundamental concepts like foundation models and data privacy to emerging challenges such as environmental impact and emergent behavior. Drawing from extensive research and practical applications, this article serves as both an educational resource and a practical guide for understanding the current state and future trajectory of AI technology.
The accompanying interactive slide deck provides visual learning materials that complement the detailed analysis presented in this article, making complex AI concepts accessible to both technical and non-technical audiences. Together, these resources offer a complete educational framework for understanding the opportunities and challenges that define contemporary artificial intelligence.

AI and Data Privacy: Protect Your Data, Work GDPR-Compliantly, and Use Artificial Intelligence Securely: Anonymization, Local Models, and Data Deletion … series on Artificial Intelligence Literacy)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Introduction: The AI Revolution in Context
The artificial intelligence landscape of 2025 represents a remarkable convergence of theoretical breakthroughs, computational advances, and practical applications that have fundamentally altered how we approach problem-solving across virtually every domain of human endeavor. From the early days of rule-based systems and expert systems in the 1980s to today’s sophisticated large language models and multimodal AI systems, the journey has been marked by periods of rapid advancement punctuated by moments of reflection on the broader implications of these technologies.
What distinguishes the current era of AI development is not merely the scale of computational resources or the sophistication of algorithms, but rather the emergence of capabilities that appear to transcend the sum of their programmed parts. Modern AI systems demonstrate behaviors and competencies that their creators did not explicitly design, leading to both unprecedented opportunities and novel challenges that require careful consideration from technical, ethical, and societal perspectives.
The twelve key concepts explored in this article represent the most critical areas of understanding for anyone seeking to comprehend the current state of AI technology. These topics were selected based on their fundamental importance to AI development, their practical implications for users and developers, and their significance in shaping the future trajectory of artificial intelligence research and application.
Each section of this article corresponds to detailed visual materials in the accompanying slide deck, which provides interactive charts, diagrams, and visual explanations that enhance understanding of complex technical concepts. This multimedia approach recognizes that different learners benefit from different presentation formats, and that the complexity of modern AI requires multiple perspectives to achieve comprehensive understanding.

Fine-Tuning Large Language Models: From Custom Datasets to High-Performance AI Models Using Modern Toolchains
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Training Deck – Understanding Modern AI: Key Concepts and Challenges

AI for Therapists: The Practical Guide to HIPAA-Compliant AI Tools, Prompt Engineering, and Ethical Workflows for Mental Health Professionals (AI for Professionals)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Chapter 1: The Foundation of Trust – Understanding AI Data Privacy
The relationship between artificial intelligence and data privacy represents one of the most critical challenges facing the technology industry today. As AI systems become increasingly sophisticated and pervasive, their appetite for data grows exponentially, creating unprecedented opportunities for both innovation and privacy violations. Understanding the nuances of AI data privacy is essential for developers, users, and policymakers alike, as the decisions made today will shape the privacy landscape for generations to come.

The Nature of AI Data Consumption
Modern AI systems, particularly large language models and deep learning networks, require vast quantities of data to achieve their remarkable capabilities. This data hunger stems from the fundamental nature of machine learning, which relies on pattern recognition across large datasets to develop predictive capabilities. Unlike traditional software applications that process data according to predetermined rules, AI systems learn from data, making the quality, quantity, and diversity of training data crucial determinants of system performance.
The scale of data consumption in modern AI is staggering. Training datasets for large language models often contain hundreds of billions of tokens, representing text from millions of web pages, books, articles, and other sources. Image recognition systems may train on millions of photographs, while recommendation systems analyze billions of user interactions. This massive data consumption creates multiple privacy challenges that extend far beyond traditional data protection concerns.
Personal information embedded within training datasets can be inadvertently memorized by AI models, leading to potential privacy breaches when the model generates outputs that reveal sensitive information about individuals who never consented to their data being used for AI training. This phenomenon, known as training data extraction, has been demonstrated in various AI systems, highlighting the need for robust privacy protection mechanisms throughout the AI development lifecycle.
Regulatory Frameworks and Compliance Challenges
The regulatory landscape surrounding AI and data privacy is rapidly evolving, with frameworks like the European Union’s General Data Protection Regulation (GDPR) setting important precedents for how AI systems must handle personal data. Under GDPR, AI systems that process personal data must comply with principles of lawfulness, fairness, transparency, purpose limitation, data minimization, accuracy, storage limitation, integrity, confidentiality, and accountability.
These principles create significant challenges for AI developers, particularly in areas such as data minimization and purpose limitation. Traditional AI development practices often involve collecting as much data as possible to improve model performance, directly conflicting with the GDPR principle of data minimization, which requires that only data necessary for specific purposes be collected and processed.
The principle of transparency presents another significant challenge, as many AI systems, particularly deep learning models, operate as “black boxes” where the decision-making process is not easily interpretable or explainable. This opacity conflicts with GDPR requirements for individuals to understand how their data is being processed and to receive meaningful information about the logic involved in automated decision-making.
Compliance with these regulations requires AI developers to implement privacy-by-design principles, incorporating privacy considerations into every stage of the AI development process. This includes conducting privacy impact assessments, implementing data protection measures such as encryption and access controls, and developing mechanisms for individuals to exercise their rights under data protection laws, including the right to access, rectify, erase, and port their personal data.
Technical Approaches to Privacy Protection
The technical AI community has developed several innovative approaches to address privacy concerns while maintaining the effectiveness of AI systems. Differential privacy, a mathematical framework for quantifying and limiting privacy loss, has emerged as one of the most promising approaches for protecting individual privacy in AI training datasets.
Differential privacy works by adding carefully calibrated noise to datasets or model outputs, ensuring that the presence or absence of any individual’s data in the training set cannot be reliably determined from the model’s behavior. This approach allows organizations to gain insights from data while providing formal privacy guarantees to individuals whose data is included in the analysis.
Federated learning represents another significant advancement in privacy-preserving AI. This approach allows AI models to be trained across multiple devices or organizations without centralizing the underlying data. Instead of sending data to a central server, federated learning sends model updates, allowing the benefits of collaborative learning while keeping sensitive data localized.
Homomorphic encryption, while still in early stages of practical application, offers the theoretical possibility of performing computations on encrypted data without decrypting it. This could enable AI training and inference on sensitive data while maintaining cryptographic protection throughout the process.
Synthetic data generation has also emerged as a valuable tool for privacy protection. By training generative models to create artificial datasets that maintain the statistical properties of real data while removing direct links to individual records, organizations can develop and test AI systems without exposing sensitive personal information.
Emerging Privacy Challenges
As AI systems become more sophisticated, new privacy challenges continue to emerge. The development of multimodal AI systems that can process text, images, audio, and video simultaneously creates new opportunities for privacy violations through cross-modal inference, where information from one modality can be used to infer sensitive information about another.
The increasing use of AI in sensitive domains such as healthcare, finance, and criminal justice amplifies privacy concerns, as errors or breaches in these areas can have severe consequences for individuals. The development of AI systems that can generate realistic synthetic content, including deepfakes and synthetic text, creates new challenges for consent and authenticity in data collection and use.
The global nature of AI development and deployment also creates challenges for privacy protection, as data may be processed across multiple jurisdictions with different privacy laws and standards. This complexity requires organizations to navigate a patchwork of regulatory requirements while maintaining consistent privacy protections for users worldwide.
[Reference to Training Slide: The accompanying slide deck includes detailed visualizations of privacy protection mechanisms and regulatory frameworks that complement this analysis.]
As an affiliate, we earn on qualifying purchases. As an affiliate, we earn on qualifying purchases.
AI and Machine Learning for Coders: A Programmer's Guide to Artificial Intelligence
Chapter 2: Democratizing AI – The Open Source Revolution
The open source movement in artificial intelligence represents a fundamental shift in how AI technology is developed, distributed, and democratized. Unlike the early days of AI research, when cutting-edge capabilities were largely confined to well-funded research institutions and technology giants, the open source AI ecosystem has created unprecedented opportunities for innovation, collaboration, and access to state-of-the-art AI capabilities.

The Philosophy and Practice of Open Source AI
Open source AI development is grounded in principles of transparency, collaboration, and shared benefit that extend far beyond simple code sharing. At its core, open source AI represents a belief that the transformative potential of artificial intelligence should be accessible to the broadest possible community of developers, researchers, and users, rather than being concentrated in the hands of a few powerful organizations.
This philosophy manifests in multiple dimensions of AI development. Open source AI projects typically provide not only the source code for AI models and training frameworks, but also detailed documentation, training datasets, model weights, and comprehensive guides for reproduction and modification. This level of transparency enables researchers and developers to understand exactly how AI systems work, identify potential biases or limitations, and build upon existing work to create new innovations.
The collaborative nature of open source AI development has led to rapid advancement in AI capabilities through distributed innovation. When researchers publish their models and code openly, other researchers can quickly build upon their work, leading to faster iteration cycles and more robust solutions than would be possible through isolated development efforts. This collaborative approach has been particularly evident in the development of transformer architectures, where innovations from multiple research groups have been rapidly integrated and improved upon by the broader community.
The economic implications of open source AI are profound. By providing free access to sophisticated AI capabilities, open source projects dramatically lower the barriers to entry for AI development and deployment. Small startups, academic researchers, and developers in resource-constrained environments can access the same fundamental AI technologies used by major technology companies, enabling innovation and competition that would otherwise be impossible.
Major Open Source AI Ecosystems
The open source AI landscape is dominated by several major ecosystems, each with its own strengths, focus areas, and community characteristics. Understanding these ecosystems is crucial for anyone seeking to leverage open source AI effectively.
Hugging Face has emerged as perhaps the most significant platform for open source AI, particularly in the domain of natural language processing and multimodal AI. The platform hosts thousands of pre-trained models, datasets, and applications, providing a comprehensive ecosystem for AI development and deployment. Hugging Face’s transformers library has become the de facto standard for working with transformer-based models, offering easy-to-use interfaces for a wide range of AI tasks including text generation, translation, summarization, and question answering.
The platform’s model hub contains contributions from major research institutions, technology companies, and individual researchers, creating a diverse ecosystem of AI capabilities. Models range from small, efficient architectures suitable for edge deployment to large, powerful models that rival proprietary alternatives. The platform also provides tools for model evaluation, comparison, and deployment, making it easier for developers to find and use appropriate models for their specific needs.
PyTorch and TensorFlow represent the foundational frameworks upon which much of the open source AI ecosystem is built. PyTorch, developed by Meta (formerly Facebook), has gained particular popularity in the research community due to its dynamic computation graphs and intuitive Python-first design. TensorFlow, developed by Google, offers robust production deployment capabilities and has been widely adopted in enterprise environments.
Both frameworks provide comprehensive ecosystems including high-level APIs for common AI tasks, distributed training capabilities, model optimization tools, and deployment solutions for various platforms including mobile devices, web browsers, and cloud environments. The competition and collaboration between these frameworks has driven rapid innovation in AI development tools and practices.
Benefits and Advantages of Open Source AI
The advantages of open source AI extend across multiple dimensions, creating value for individual developers, organizations, and society as a whole. From a technical perspective, open source AI provides unparalleled transparency and auditability. Developers can examine the complete implementation of AI models, understand their limitations and biases, and modify them to suit specific requirements.
This transparency is particularly valuable for applications in sensitive domains such as healthcare, finance, and criminal justice, where understanding and validating AI behavior is crucial for ethical and effective deployment. Open source models can be thoroughly tested, audited, and validated by independent researchers, providing greater confidence in their reliability and fairness than proprietary alternatives.
The customization capabilities offered by open source AI are another significant advantage. Organizations can modify open source models to incorporate domain-specific knowledge, adapt to particular data distributions, or optimize for specific performance requirements. This level of customization is often impossible with proprietary AI services, which typically offer limited configuration options and no access to underlying model architectures.
From an economic perspective, open source AI can provide substantial cost savings compared to proprietary alternatives. Organizations can deploy open source models on their own infrastructure, avoiding ongoing licensing fees and usage-based pricing that can become prohibitively expensive at scale. This cost advantage is particularly significant for applications that require processing large volumes of data or serving many users.
The educational value of open source AI cannot be overstated. Students, researchers, and practitioners can learn from real-world implementations of cutting-edge AI techniques, accelerating their understanding and skill development. This educational benefit creates a positive feedback loop, as more knowledgeable practitioners contribute back to the open source community, further advancing the state of the art.
Challenges and Considerations
Despite its many advantages, open source AI also presents certain challenges and considerations that users must carefully evaluate. One of the primary challenges is the technical expertise required to effectively deploy and maintain open source AI systems. Unlike proprietary AI services that provide managed infrastructure and support, open source AI typically requires users to handle their own deployment, scaling, monitoring, and maintenance.
This technical complexity can be particularly challenging for organizations without dedicated AI expertise or infrastructure teams. Deploying large language models, for example, requires significant computational resources, specialized hardware knowledge, and expertise in distributed systems and model optimization. The learning curve for effectively using open source AI tools can be steep, particularly for complex applications.
Quality and reliability considerations also present challenges in the open source AI ecosystem. While many open source models are developed by reputable research institutions and companies, the decentralized nature of open source development means that quality can vary significantly across different projects. Users must carefully evaluate the provenance, testing, and validation of open source models before deploying them in production environments.
Security considerations are another important factor in open source AI deployment. While the transparency of open source code enables security auditing, it also means that potential vulnerabilities are visible to malicious actors. Organizations must implement appropriate security measures and stay current with security updates and patches for their open source AI dependencies.
The support and maintenance model for open source AI projects can also present challenges. While many projects have active communities and commercial support options, some projects may have limited ongoing maintenance or may become abandoned over time. Organizations must carefully evaluate the long-term viability and support ecosystem of open source AI projects before making significant investments in them.
[Reference to Training Slide: The slide deck provides visual comparisons of major open source AI platforms and their respective strengths and use cases.]
Chapter 3: The Reality of Local AI Deployment
The deployment of artificial intelligence models on local infrastructure represents both a significant opportunity and a substantial challenge in the current AI landscape. As organizations and individuals seek greater control over their AI capabilities, reduced dependence on cloud services, and enhanced privacy protection, the appeal of local AI deployment has grown considerably. However, the technical, economic, and operational challenges associated with running sophisticated AI models locally require careful consideration and planning.

Understanding the Local Deployment Landscape
Local AI deployment encompasses a broad spectrum of scenarios, from running small, specialized models on edge devices to deploying large language models on enterprise data center infrastructure. The motivations for local deployment vary significantly across these scenarios, but common drivers include privacy and data sovereignty concerns, latency requirements, cost optimization, and the desire for greater control over AI capabilities.
The technical requirements for local AI deployment have evolved dramatically as AI models have grown in size and complexity. Early AI applications, such as simple image classification or basic natural language processing tasks, could be effectively deployed on modest hardware configurations. However, modern large language models with billions or trillions of parameters require substantial computational resources that challenge even well-equipped data centers.
The hardware landscape for local AI deployment is dominated by graphics processing units (GPUs), which provide the parallel processing capabilities essential for efficient AI inference and training. However, the specific GPU requirements vary dramatically based on the size and type of AI model being deployed. Small models suitable for mobile applications may run effectively on integrated GPUs or specialized AI accelerators, while large language models may require multiple high-end GPUs with substantial memory capacity.
Central processing unit (CPU) requirements for AI deployment are often underestimated but remain crucial for overall system performance. AI workloads typically require substantial memory bandwidth and capacity, fast storage systems, and robust networking infrastructure to support distributed deployment scenarios. The balance between these different hardware components significantly impacts both performance and cost-effectiveness of local AI deployments.
Hardware Requirements and Constraints
The hardware requirements for local AI deployment present one of the most significant barriers to widespread adoption. Large language models, which have become increasingly popular for a wide range of applications, typically require substantial GPU memory to store model parameters during inference. A model with 70 billion parameters, for example, requires approximately 140 GB of memory when loaded in 16-bit precision, necessitating multiple high-end GPUs or specialized high-memory configurations.
Memory requirements extend beyond simple parameter storage to include activation memory for processing inputs, memory for attention mechanisms in transformer models, and additional overhead for the inference framework itself. These requirements can easily double or triple the baseline memory needs, making even modest-sized models challenging to deploy on consumer-grade hardware.
The computational requirements for AI inference vary significantly based on the specific model architecture and the desired throughput. Transformer-based models, which dominate current AI applications, require substantial computational resources for attention calculations, particularly for long input sequences. The quadratic scaling of attention mechanisms with sequence length means that processing long documents or conversations can quickly overwhelm available computational resources.
Specialized hardware accelerators, including tensor processing units (TPUs), field-programmable gate arrays (FPGAs), and dedicated AI chips, offer potential solutions to some of these hardware challenges. These accelerators are designed specifically for AI workloads and can provide significant performance and efficiency advantages over general-purpose GPUs. However, they often require specialized software stacks and may have limited compatibility with existing AI frameworks and models.
The networking requirements for distributed AI deployment add another layer of complexity to local deployment scenarios. Large models that cannot fit on a single device must be distributed across multiple devices, requiring high-bandwidth, low-latency networking to coordinate inference across the distributed system. This networking overhead can significantly impact overall system performance and adds complexity to deployment and management.
Performance and Efficiency Considerations
The performance characteristics of locally deployed AI systems differ significantly from cloud-based alternatives in ways that extend beyond simple throughput metrics. Latency, which is often a primary motivation for local deployment, can be dramatically improved by eliminating network round-trips to remote servers. However, achieving optimal latency requires careful optimization of the entire inference pipeline, from input preprocessing to output generation.
Model optimization techniques play a crucial role in making local AI deployment practical and efficient. Quantization, which reduces the precision of model parameters from 32-bit or 16-bit floating-point numbers to 8-bit or even lower precision integers, can significantly reduce memory requirements and improve inference speed with minimal impact on model accuracy. Advanced quantization techniques, such as dynamic quantization and quantization-aware training, can achieve even better trade-offs between efficiency and accuracy.
Pruning techniques, which remove unnecessary connections or entire neurons from neural networks, offer another approach to reducing model size and computational requirements. Structured pruning, which removes entire channels or layers, can be particularly effective for deployment on hardware with limited parallel processing capabilities. Unstructured pruning, which removes individual connections, can achieve higher compression ratios but may require specialized hardware or software support to realize performance benefits.
Knowledge distillation represents a more fundamental approach to model optimization, involving training smaller “student” models to mimic the behavior of larger “teacher” models. This technique can produce models that are orders of magnitude smaller than their teachers while retaining much of their capability. However, the distillation process requires access to the original training data or carefully constructed synthetic datasets, which may not always be available.
The energy efficiency of local AI deployment has become an increasingly important consideration as organizations seek to minimize operational costs and environmental impact. AI inference can be extremely energy-intensive, particularly for large models running on power-hungry GPUs. Optimizing energy efficiency requires balancing performance requirements with power consumption, often involving trade-offs between inference speed and energy usage.
Economic Implications and Cost Analysis
The economic analysis of local AI deployment involves complex trade-offs between upfront capital expenditures, ongoing operational costs, and the value derived from AI capabilities. The initial hardware investment for local AI deployment can be substantial, particularly for organizations seeking to deploy large, state-of-the-art models. High-end GPUs suitable for AI workloads can cost tens of thousands of dollars each, and complete systems capable of running large language models may require investments of hundreds of thousands or millions of dollars.
However, these upfront costs must be evaluated against the ongoing costs of cloud-based AI services, which typically charge based on usage volume. For organizations with consistent, high-volume AI workloads, local deployment can provide significant cost savings over time. The break-even point depends on factors including the specific models being used, the volume of inference requests, the cost of local infrastructure, and the pricing of alternative cloud services.
The total cost of ownership for local AI deployment extends beyond hardware acquisition to include ongoing operational expenses such as electricity, cooling, maintenance, and personnel costs. Data center-grade AI hardware typically requires substantial power and cooling infrastructure, which can represent a significant portion of ongoing operational costs. Additionally, maintaining and optimizing AI infrastructure requires specialized expertise that may necessitate hiring additional personnel or investing in training for existing staff.
The opportunity costs associated with local AI deployment also merit consideration. Organizations that invest heavily in local AI infrastructure may have fewer resources available for other technology investments or business initiatives. Additionally, the rapid pace of AI hardware and software development means that local infrastructure may become obsolete more quickly than traditional IT investments, requiring more frequent refresh cycles.
Security and Compliance Considerations
Local AI deployment offers significant advantages for organizations with strict security and compliance requirements. By keeping AI processing on-premises, organizations can maintain complete control over their data and ensure that sensitive information never leaves their secure environment. This level of control is particularly important for organizations in regulated industries such as healthcare, finance, and government, where data protection requirements may prohibit the use of external AI services.
However, local AI deployment also introduces new security challenges that organizations must address. AI models themselves can be valuable intellectual property that requires protection from theft or unauthorized access. Additionally, AI systems may be vulnerable to adversarial attacks that attempt to manipulate model behavior or extract sensitive information from training data.
The complexity of AI software stacks, which typically include multiple frameworks, libraries, and dependencies, creates a large attack surface that requires ongoing security monitoring and maintenance. Organizations must implement robust security practices including regular security updates, vulnerability scanning, and access controls to protect their AI infrastructure.
Compliance with data protection regulations such as GDPR or HIPAA may actually be simplified by local AI deployment, as organizations can implement comprehensive data governance and audit trails without relying on external service providers. However, organizations must still ensure that their local AI systems comply with all relevant regulations and industry standards.
[Reference to Training Slide: The slide deck includes detailed charts comparing hardware requirements and cost analysis for different scales of local AI deployment.]
Chapter 4: Foundation Models – The Bedrock of Modern AI
Foundation models represent a paradigm shift in artificial intelligence development, moving away from task-specific models toward large-scale, general-purpose systems that can be adapted for a wide variety of applications. These models, trained on vast datasets using self-supervised learning techniques, have become the cornerstone of modern AI applications and have fundamentally changed how researchers and practitioners approach AI development.

The Conceptual Framework of Foundation Models
The term “foundation model” was coined by researchers at Stanford University to describe a new class of AI models that are trained on broad data at scale and can be adapted to a wide range of downstream tasks. Unlike traditional machine learning approaches that require training separate models for each specific task, foundation models provide a single, powerful base that can be fine-tuned or prompted to perform diverse functions.
The conceptual foundation of these models rests on the principle of transfer learning, where knowledge gained from training on one task can be applied to related tasks. However, foundation models take this concept to an unprecedented scale, learning general representations of language, images, or other modalities that capture fundamental patterns and relationships that are useful across many different applications.
The self-supervised learning paradigm that underlies most foundation models represents a significant departure from traditional supervised learning approaches. Instead of requiring labeled training data, self-supervised learning creates learning objectives from the structure of the data itself. For language models, this might involve predicting the next word in a sequence or filling in masked words in a sentence. For image models, it might involve predicting missing parts of an image or learning to associate images with their captions.
This self-supervised approach enables foundation models to learn from vast quantities of unlabeled data that would be prohibitively expensive to manually annotate. The scale of training data for modern foundation models is unprecedented, with some language models trained on datasets containing trillions of tokens representing a significant fraction of all text available on the internet.
Architectural Innovations and Technical Foundations
The transformer architecture, introduced in the seminal paper “Attention Is All You Need” by Vaswani et al., has become the dominant architectural paradigm for foundation models. The transformer’s key innovation is the attention mechanism, which allows the model to dynamically focus on different parts of the input when processing each element, enabling more effective modeling of long-range dependencies and complex relationships.
The attention mechanism works by computing weighted combinations of input representations, where the weights are determined by learned compatibility functions between different elements of the input. This approach allows the model to capture relationships between distant elements in a sequence more effectively than previous architectures such as recurrent neural networks or convolutional neural networks.
The scalability of the transformer architecture has been crucial to the success of foundation models. Unlike recurrent architectures that must process sequences sequentially, transformers can process all elements of a sequence in parallel, making them much more efficient to train on modern parallel computing hardware. This parallelizability has enabled the training of increasingly large models with billions or trillions of parameters.
The multi-head attention mechanism used in transformers allows the model to attend to different types of relationships simultaneously. Each attention head can learn to focus on different aspects of the input, such as syntactic relationships, semantic similarities, or long-range dependencies. The combination of multiple attention heads provides a rich representation that captures diverse aspects of the input data.
Layer normalization and residual connections are additional architectural components that have proven crucial for training very deep transformer models. Layer normalization helps stabilize training by normalizing the inputs to each layer, while residual connections allow gradients to flow more effectively through deep networks, enabling the training of models with hundreds of layers.
Training Methodologies and Scale
The training of foundation models requires unprecedented computational resources and sophisticated distributed training techniques. Modern foundation models are trained on clusters of thousands of GPUs or specialized AI accelerators, with training runs that can last for months and consume millions of dollars worth of computational resources.
The distributed training of foundation models involves complex coordination across multiple devices and machines. Data parallelism, where different devices process different batches of training data, is combined with model parallelism, where different parts of the model are distributed across different devices. Advanced techniques such as pipeline parallelism and tensor parallelism are used to further optimize training efficiency and enable the training of models that are too large to fit on any single device.
The optimization of foundation model training involves careful tuning of numerous hyperparameters, including learning rates, batch sizes, and regularization techniques. The scale of these models makes hyperparameter optimization particularly challenging, as the cost of training experiments is extremely high. Researchers have developed various techniques for efficient hyperparameter search, including early stopping based on smaller-scale experiments and transfer of hyperparameters from smaller models.
The data preprocessing and curation for foundation model training is a complex undertaking that significantly impacts model performance and behavior. Training datasets must be carefully filtered to remove low-quality content, deduplicated to prevent overfitting, and balanced to ensure diverse representation across different domains and perspectives. The quality and composition of training data has profound implications for model capabilities, biases, and potential harmful behaviors.
Adaptation and Fine-tuning Strategies
One of the key advantages of foundation models is their ability to be adapted for specific tasks and domains through various fine-tuning and adaptation techniques. Traditional fine-tuning involves continuing the training process on task-specific data, adjusting the model’s parameters to optimize performance for the target application. This approach can be highly effective but requires substantial computational resources and task-specific training data.
Parameter-efficient fine-tuning techniques have emerged as important alternatives to full fine-tuning, enabling adaptation of foundation models with minimal computational overhead. Low-rank adaptation (LoRA) is one such technique that adds small, trainable matrices to the model while keeping the original parameters frozen. This approach can achieve performance comparable to full fine-tuning while requiring orders of magnitude fewer trainable parameters.
Prompt engineering and in-context learning represent another paradigm for adapting foundation models without modifying their parameters. By carefully crafting input prompts that provide examples or instructions, users can guide foundation models to perform specific tasks without any additional training. This approach is particularly powerful for large language models, which can often perform complex tasks based solely on well-designed prompts.
Instruction tuning is a specialized form of fine-tuning that trains foundation models to follow human instructions more effectively. Models trained with instruction tuning can understand and execute a wide variety of tasks based on natural language descriptions, making them more useful for general-purpose applications. This approach has been crucial for developing AI assistants and other interactive AI systems.
Applications and Impact Across Domains
Foundation models have found applications across virtually every domain where AI is applied, demonstrating their versatility and power. In natural language processing, foundation models power applications ranging from chatbots and virtual assistants to content generation, translation, and summarization systems. The ability of these models to understand and generate human-like text has revolutionized how we interact with AI systems.
In computer vision, foundation models trained on large-scale image datasets have achieved remarkable performance on tasks such as image classification, object detection, and image generation. Vision transformers, which apply the transformer architecture to image data, have achieved state-of-the-art results on many computer vision benchmarks and have enabled new applications such as high-quality image synthesis and editing.
The application of foundation models to scientific domains has shown particular promise, with models trained on scientific literature and data achieving breakthrough results in areas such as protein structure prediction, drug discovery, and materials science. These applications demonstrate the potential for foundation models to accelerate scientific discovery and enable new research methodologies.
Multimodal foundation models that can process and generate content across multiple modalities (text, images, audio, video) represent the current frontier of foundation model development. These models can understand relationships between different types of content and perform tasks that require reasoning across modalities, such as generating images from text descriptions or answering questions about visual content.
Challenges and Limitations
Despite their remarkable capabilities, foundation models face significant challenges and limitations that constrain their applicability and raise important concerns about their deployment. The computational requirements for training and deploying foundation models create barriers to access and contribute to environmental concerns about the energy consumption of AI systems.
The black-box nature of foundation models makes it difficult to understand how they make decisions or to predict their behavior in novel situations. This lack of interpretability is particularly concerning for applications in high-stakes domains such as healthcare, finance, or criminal justice, where understanding the reasoning behind AI decisions is crucial for trust and accountability.
Bias and fairness issues in foundation models reflect the biases present in their training data and can be amplified by the scale and generality of these models. Foundation models may exhibit biases related to gender, race, religion, or other protected characteristics, and these biases can propagate to downstream applications in ways that are difficult to detect and mitigate.
The tendency of foundation models to generate plausible but factually incorrect information, known as hallucination, poses significant challenges for applications that require factual accuracy. While these models can generate coherent and convincing text, they may confidently assert false information or make up facts that sound plausible but are entirely fabricated.
[Reference to Training Slide: The slide deck provides detailed architectural diagrams and visual comparisons of different foundation model approaches.]
Chapter 5: Economic Optimization Through Specialized AI Models
The economic landscape of artificial intelligence deployment has been fundamentally shaped by the tension between capability and cost-effectiveness. While large, general-purpose foundation models offer impressive versatility and performance, their computational requirements and associated costs have driven significant interest in specialized AI models that can deliver targeted capabilities at a fraction of the resource requirements. This economic optimization through specialization represents a crucial strategy for making AI accessible and sustainable across diverse applications and organizations.

The Economics of AI Model Specialization
The economic rationale for specialized AI models stems from the fundamental principle that not all applications require the full capabilities of large, general-purpose models. Many real-world AI applications have specific, well-defined requirements that can be met by smaller, more focused models that are optimized for particular tasks or domains. By trading generality for efficiency, specialized models can deliver the necessary performance while dramatically reducing computational costs, energy consumption, and infrastructure requirements.
The cost structure of AI deployment includes several key components: computational resources for inference, memory requirements for model storage and execution, energy consumption for powering hardware, and infrastructure costs for deployment and scaling. Large foundation models typically require substantial resources across all these dimensions, making them expensive to deploy and operate at scale. Specialized models can optimize each of these cost components by focusing on specific requirements rather than general capabilities.
The development of specialized models often involves starting with a pre-trained foundation model and then applying various optimization techniques to reduce its size and computational requirements while maintaining performance on specific tasks. This approach leverages the knowledge captured in large models while creating deployable systems that are practical for resource-constrained environments.
The return on investment for specialized AI models can be substantially higher than for general-purpose alternatives, particularly for organizations with well-defined use cases and performance requirements. By avoiding the overhead associated with unused capabilities, specialized models can deliver better cost-performance ratios and enable AI deployment in scenarios where general-purpose models would be economically unfeasible.
Technical Approaches to Model Specialization
Knowledge distillation represents one of the most effective techniques for creating specialized AI models. This process involves training a smaller “student” model to mimic the behavior of a larger “teacher” model on specific tasks or domains. The student model learns to approximate the teacher’s outputs while using significantly fewer parameters and computational resources.
The distillation process typically involves training the student model on a combination of the original training data and the outputs generated by the teacher model. The student learns not only from the correct answers but also from the teacher’s confidence levels and the distribution of its predictions across different possible outputs. This rich training signal enables the student model to capture much of the teacher’s knowledge while being orders of magnitude smaller.
Advanced distillation techniques include progressive distillation, where intermediate-sized models are used as stepping stones between the teacher and student, and task-specific distillation, where the distillation process is focused on particular tasks or domains of interest. These techniques can achieve even better trade-offs between model size and performance for specific applications.
Model pruning offers another approach to creating specialized models by removing unnecessary components from existing models. Structured pruning removes entire neurons, layers, or attention heads, while unstructured pruning removes individual connections or parameters. The choice between these approaches depends on the target deployment environment and the available optimization tools.
Magnitude-based pruning removes parameters with the smallest absolute values, based on the assumption that these parameters contribute least to model performance. More sophisticated pruning techniques consider the impact of removing specific parameters on model performance and use iterative approaches to gradually reduce model size while monitoring performance degradation.
Quantization techniques reduce the precision of model parameters and activations, typically from 32-bit floating-point numbers to 8-bit integers or even lower precision representations. This reduction in precision can significantly decrease memory requirements and computational costs while maintaining acceptable performance for many applications.
Post-training quantization can be applied to existing models without retraining, making it a practical approach for optimizing pre-trained models. Quantization-aware training incorporates quantization effects into the training process, typically achieving better performance than post-training approaches but requiring access to training data and computational resources.
Domain-Specific Optimization Strategies
Different application domains present unique opportunities for model specialization and optimization. Natural language processing applications can benefit from domain-specific vocabulary optimization, where models are fine-tuned on domain-specific text and optimized for particular linguistic patterns and terminology. Medical AI applications, for example, can use specialized models trained on medical literature and optimized for medical terminology and reasoning patterns.
Computer vision applications can leverage domain-specific optimizations such as specialized architectures for particular types of images or visual tasks. Autonomous vehicle applications might use models optimized for road scene understanding, while medical imaging applications might use models specialized for particular types of medical scans or diagnostic tasks.
The optimization of models for specific hardware platforms represents another important dimension of specialization. Models can be optimized for particular types of processors, memory configurations, or deployment environments. Edge AI applications, for example, require models that can run efficiently on mobile processors with limited memory and power budgets.
Temporal optimization involves adapting models for specific time-sensitive requirements. Real-time applications may require models that can provide predictions within strict latency constraints, while batch processing applications may prioritize throughput over individual prediction latency. These different requirements lead to different optimization strategies and trade-offs.
Deployment and Scaling Considerations
The deployment of specialized AI models requires careful consideration of the trade-offs between specialization and flexibility. While specialized models can be highly efficient for their intended applications, they may be less adaptable to changing requirements or new use cases. Organizations must balance the benefits of optimization against the potential costs of reduced flexibility.
The scaling characteristics of specialized models differ significantly from those of general-purpose models. Specialized models typically scale more efficiently in terms of computational resources and costs, but they may require more complex deployment architectures to handle diverse use cases. Organizations may need to deploy multiple specialized models rather than a single general-purpose model, creating additional complexity in model management and orchestration.
The maintenance and updating of specialized models presents unique challenges. While general-purpose models can be updated centrally and applied across many use cases, specialized models may require individual attention and optimization for each specific application. This can increase the operational overhead associated with maintaining AI systems over time.
Version control and model lifecycle management become more complex with specialized models, as organizations may need to track and manage many different model variants optimized for different tasks, domains, or deployment environments. Effective tooling and processes for model management are crucial for successfully deploying specialized AI at scale.
Measuring and Optimizing Cost-Effectiveness
The measurement of cost-effectiveness for specialized AI models requires comprehensive metrics that capture both performance and resource utilization. Traditional accuracy metrics must be balanced against computational costs, energy consumption, and infrastructure requirements to provide a complete picture of model efficiency.
Performance per dollar metrics provide a useful framework for comparing different model optimization strategies. These metrics consider both the absolute performance of models on relevant tasks and the total cost of deployment and operation. The optimal choice of model depends on the specific requirements and constraints of each application.
Energy efficiency has become an increasingly important consideration in AI model optimization, both for cost reasons and environmental concerns. Specialized models can achieve dramatic improvements in energy efficiency compared to general-purpose alternatives, making them attractive for both economic and sustainability reasons.
The total cost of ownership for specialized AI models includes not only computational costs but also development, deployment, and maintenance costs. While specialized models may require additional upfront investment in optimization and customization, they can provide significant long-term cost savings for organizations with stable, well-defined AI requirements.
[Reference to Training Slide: The slide deck includes detailed cost comparison charts and optimization strategy visualizations that complement this analysis.]
Chapter 6: Mixture of Experts – Scaling Intelligence Through Specialization
The Mixture of Experts (MoE) architecture represents one of the most significant innovations in modern AI system design, offering a sophisticated approach to scaling model capabilities while maintaining computational efficiency. By combining multiple specialized neural networks with intelligent routing mechanisms, MoE models can achieve the performance of much larger dense models while activating only a small fraction of their parameters for any given input. This architectural innovation has become crucial for developing large-scale AI systems that can handle diverse tasks efficiently.

Theoretical Foundations and Architectural Principles
The conceptual foundation of Mixture of Experts models draws from the principle of divide-and-conquer problem solving, where complex tasks are decomposed into simpler subtasks that can be handled by specialized components. In the context of neural networks, this translates to having multiple “expert” networks, each specialized for different types of inputs or tasks, combined with a “gating” network that determines which experts should be activated for each input.
The theoretical appeal of MoE architectures lies in their ability to increase model capacity without proportionally increasing computational costs. Traditional dense neural networks activate all parameters for every input, leading to a linear relationship between model size and computational requirements. MoE models break this relationship by activating only a subset of experts for each input, enabling much larger total parameter counts while maintaining manageable computational costs.
The gating mechanism is the critical component that determines the effectiveness of MoE models. The gating network learns to route inputs to the most appropriate experts based on the characteristics of the input and the specializations of different experts. This routing decision is typically made using a learned function that computes compatibility scores between inputs and experts, with only the top-k experts being activated for each input.
The training of MoE models presents unique challenges compared to dense models. The discrete routing decisions made by the gating network create non-differentiable operations that complicate gradient-based optimization. Various techniques have been developed to address this challenge, including soft routing mechanisms that use continuous weights instead of discrete selections, and auxiliary losses that encourage balanced expert utilization.
Expert Specialization and Load Balancing
One of the key challenges in MoE model design is ensuring that different experts develop meaningful specializations rather than redundant capabilities. Without proper mechanisms to encourage specialization, experts may converge to similar functions, negating the benefits of the MoE architecture. Various techniques have been developed to promote expert diversity and specialization.
Load balancing represents another crucial challenge in MoE systems. If the gating network consistently routes most inputs to a small subset of experts, the model effectively becomes a smaller dense model, losing the capacity benefits of the MoE architecture. Additionally, unbalanced expert utilization can lead to training instabilities and poor convergence.
Auxiliary losses are commonly used to encourage balanced expert utilization. These losses penalize the gating network when expert usage becomes too imbalanced, encouraging more uniform distribution of inputs across experts. However, these auxiliary losses must be carefully tuned to balance the competing objectives of expert specialization and load balancing.
The capacity factor, which determines how many experts are activated for each input, represents a key hyperparameter in MoE model design. Higher capacity factors increase computational costs but may improve model performance by allowing more experts to contribute to each prediction. The optimal capacity factor depends on the specific task, model size, and computational constraints.
Expert dropout is another technique used to improve MoE model training and generalization. By randomly dropping experts during training, the model learns to be robust to expert failures and develops more diverse expert specializations. This technique can also help prevent overfitting to particular expert combinations.
Scaling Laws and Performance Characteristics
The scaling behavior of MoE models differs significantly from dense models, offering unique advantages for large-scale AI development. While dense models exhibit predictable scaling laws where performance improves with model size following power-law relationships, MoE models can achieve similar performance improvements with much smaller increases in computational costs.
The effective parameter count of MoE models is much larger than their active parameter count, enabling them to store and utilize more knowledge while maintaining efficient inference. This characteristic makes MoE models particularly attractive for applications that require broad knowledge coverage, such as large language models that must handle diverse topics and domains.
The memory requirements for MoE models present both advantages and challenges. While the total memory required to store all experts can be substantial, the memory required for active computation is much smaller since only a subset of experts are used for each input. This characteristic enables the deployment of very large MoE models on distributed systems where the total model cannot fit on any single device.
The communication overhead in distributed MoE deployments can be significant, as inputs must be routed to the appropriate experts, which may be located on different devices. Efficient communication strategies and expert placement algorithms are crucial for achieving good performance in distributed MoE systems.
Implementation Strategies and Optimization Techniques
The implementation of efficient MoE systems requires careful consideration of both algorithmic and systems-level optimizations. The routing computation must be fast enough to avoid becoming a bottleneck, while the expert networks must be efficiently scheduled and executed on available hardware.
Dynamic expert selection strategies can adapt the number and identity of activated experts based on input characteristics. Simple inputs might require fewer experts, while complex inputs might benefit from activating more experts. This adaptive approach can improve both efficiency and performance compared to fixed expert selection strategies.
Expert caching and prefetching techniques can reduce the latency associated with expert activation by predicting which experts are likely to be needed and preloading them into fast memory. These techniques are particularly important for deployment scenarios where expert switching costs are high.
The design of expert networks themselves offers opportunities for optimization. Experts can use different architectures optimized for their specific specializations, rather than being constrained to identical architectures. This flexibility enables more effective specialization and can improve overall model efficiency.
Hierarchical MoE architectures use multiple levels of expert routing, with coarse-grained routing at higher levels and fine-grained routing at lower levels. This approach can improve both efficiency and specialization by creating a hierarchy of expertise that matches the structure of the problem domain.
Applications and Use Cases
MoE architectures have found successful applications across a wide range of AI domains, with particularly notable success in large language models. The Switch Transformer, developed by Google, demonstrated that MoE architectures could achieve state-of-the-art performance on language modeling tasks while being much more efficient than equivalent dense models.
In machine translation, MoE models can develop experts specialized for different language pairs or linguistic phenomena, leading to improved translation quality and efficiency. The ability to activate only relevant experts for each translation task makes MoE models particularly well-suited for multilingual applications.
Computer vision applications of MoE architectures include models with experts specialized for different types of visual content, such as natural images, medical images, or satellite imagery. This specialization can improve both accuracy and efficiency compared to general-purpose vision models.
Multimodal AI systems can benefit from MoE architectures by having experts specialized for different modalities or cross-modal interactions. This approach enables more efficient processing of multimodal inputs while maintaining the ability to handle diverse types of content.
Recommendation systems represent another promising application area for MoE models, where experts can specialize for different user segments, item categories, or interaction types. This specialization can improve recommendation quality while enabling more efficient processing of large-scale recommendation tasks.
Future Directions and Research Challenges
The development of more sophisticated gating mechanisms remains an active area of research. Current gating networks are relatively simple, but more advanced approaches could consider factors such as computational budgets, expert load, and task-specific requirements when making routing decisions.
The integration of MoE architectures with other advanced AI techniques, such as attention mechanisms, memory networks, and reinforcement learning, offers opportunities for developing even more capable and efficient AI systems. These hybrid approaches could combine the benefits of different architectural innovations.
The development of automated expert design and optimization techniques could reduce the manual effort required to design effective MoE systems. Machine learning approaches could be used to automatically determine optimal expert architectures, specializations, and routing strategies.
The application of MoE principles to other aspects of AI systems, such as data processing pipelines, optimization algorithms, and deployment strategies, could extend the benefits of expert specialization beyond neural network architectures.
[Reference to Training Slide: The slide deck provides detailed architectural diagrams and performance comparisons that illustrate the key concepts and benefits of MoE models.]
Chapter 7: Context Length – The Memory Horizon of AI Systems
Context length represents one of the most fundamental limitations and design considerations in modern AI systems, particularly for language models and other sequence-processing architectures. The context length defines the maximum amount of information that an AI model can consider when making predictions or generating responses, effectively serving as the model’s “memory window” or attention span. Understanding the implications, limitations, and ongoing developments in context length is crucial for both AI developers and users seeking to maximize the effectiveness of AI systems.

The Fundamental Nature of Context in AI Systems
Context length in AI systems refers to the maximum number of tokens that a model can process simultaneously when making predictions. For language models, tokens typically represent words, subwords, or characters, while for other modalities, tokens might represent image patches, audio segments, or other discrete units of information. The context length determines how much historical information the model can consider when generating each new token in a sequence.
The importance of context length becomes apparent when considering tasks that require understanding of long-range dependencies or extensive background information. Document summarization, for example, requires the model to consider the entire document when generating a summary. Similarly, long-form conversation requires the model to remember earlier parts of the conversation to maintain coherence and consistency.
The evolution of context length in AI models has been dramatic, reflecting both technological advances and growing understanding of the importance of long-range context. Early transformer models, such as the original BERT, had context lengths of 512 tokens, which was sufficient for many sentence-level tasks but inadequate for document-level understanding. Modern large language models have context lengths ranging from thousands to millions of tokens, enabling entirely new categories of applications.
The relationship between context length and model capability is complex and multifaceted. Longer context lengths enable models to handle more complex tasks and maintain coherence over longer sequences, but they also increase computational requirements and can introduce new challenges such as the “lost in the middle” problem, where models struggle to effectively utilize information in the middle of very long contexts.
Technical Challenges and Computational Constraints
The primary technical challenge associated with extending context length lies in the quadratic scaling of attention mechanisms with sequence length. In standard transformer architectures, the attention mechanism computes relationships between all pairs of tokens in the input sequence, leading to computational and memory requirements that scale as O(n²) where n is the sequence length. This quadratic scaling makes very long contexts computationally prohibitive for standard architectures.
Memory requirements for long-context models extend beyond the attention computation to include storage of intermediate activations, key-value caches for efficient generation, and gradient information during training. These memory requirements can quickly exceed the capacity of even high-end hardware, necessitating careful optimization and sometimes fundamental architectural changes.
The attention computation itself becomes increasingly expensive as context length grows. For a sequence of length 32,768 tokens, the attention mechanism must compute over one billion pairwise relationships, requiring substantial computational resources and time. This computational burden affects both training and inference, making long-context models expensive to develop and deploy.
Gradient computation and backpropagation through very long sequences present additional challenges during training. The memory required to store intermediate activations for gradient computation scales linearly with sequence length, and the computation of gradients through long sequences can be numerically unstable and computationally expensive.
Architectural Innovations for Long Context
Researchers have developed numerous architectural innovations to address the challenges of long-context processing while maintaining the benefits of attention-based models. Linear attention mechanisms replace the quadratic attention computation with linear alternatives that scale as O(n) with sequence length, enabling much longer contexts at the cost of some expressiveness.
Sparse attention patterns reduce computational requirements by limiting attention to subsets of tokens rather than computing full pairwise attention. Local attention focuses on nearby tokens, while global attention mechanisms allow certain tokens to attend to all other tokens. These sparse patterns can significantly reduce computational costs while maintaining much of the effectiveness of full attention.
Hierarchical attention mechanisms process sequences at multiple levels of granularity, first attending to local regions and then attending between regions. This approach can capture both local and global dependencies while reducing computational requirements compared to full attention over the entire sequence.
Sliding window attention processes long sequences by maintaining a fixed-size window of recent context and sliding this window over the sequence. This approach provides a constant computational cost regardless of sequence length but may lose important long-range dependencies that fall outside the window.
Memory-augmented architectures extend the effective context length by incorporating external memory mechanisms that can store and retrieve relevant information from much longer sequences. These approaches separate the storage of information from the attention computation, enabling models to access relevant information from very long contexts without the computational overhead of full attention.
The Lost in the Middle Problem
One of the most significant challenges with very long context lengths is the “lost in the middle” phenomenon, where models struggle to effectively utilize information that appears in the middle of long contexts. Research has shown that models tend to pay more attention to information at the beginning and end of contexts, with information in the middle being less likely to influence model outputs.
This problem appears to be fundamental to how attention mechanisms work and is not simply a matter of insufficient training. Even models specifically trained on long contexts exhibit this behavior, suggesting that it may be an inherent limitation of current architectures rather than a training issue.
The implications of the lost in the middle problem are significant for applications that require processing of long documents or conversations. Important information that appears in the middle of long contexts may be effectively ignored by the model, leading to incomplete or inaccurate responses.
Various mitigation strategies have been proposed for the lost in the middle problem, including attention reweighting schemes that explicitly encourage attention to middle portions of contexts, and training procedures that specifically focus on utilizing information from different positions within long contexts.
Practical Implications and Use Cases
The practical implications of context length limitations affect virtually every application of AI systems that process sequential data. Document analysis tasks, such as legal document review or scientific literature analysis, require models to consider entire documents that may contain tens of thousands of tokens. Current context length limitations often force these applications to use chunking strategies that may miss important cross-chunk dependencies.
Conversational AI systems face particular challenges with context length limitations. Long conversations quickly exceed the context limits of many models, forcing systems to either truncate conversation history or use sophisticated context management strategies to maintain relevant information while staying within context limits.
Code generation and analysis tasks often require understanding of large codebases that exceed typical context lengths. This limitation affects the ability of AI systems to understand complex software projects and generate code that properly integrates with existing systems.
Creative writing applications, such as novel generation or screenplay writing, require maintaining consistency and coherence over very long texts. Context length limitations can force these applications to use external memory systems or other workarounds to maintain narrative coherence.
Context Management Strategies
Given the current limitations of context length, various strategies have been developed to manage context effectively within existing constraints. Chunking strategies divide long texts into smaller segments that fit within context limits, but must carefully handle the boundaries between chunks to avoid losing important information.
Retrieval-augmented generation (RAG) systems address context limitations by retrieving relevant information from large knowledge bases and including only the most relevant information in the model’s context. This approach can effectively extend the model’s access to information while staying within context limits.
Summarization-based context management involves periodically summarizing older parts of the context to make room for new information. This approach can maintain important information from long contexts while staying within length limits, but may lose important details in the summarization process.
Hierarchical context management uses different levels of detail for different parts of the context, maintaining full detail for recent information while using compressed representations for older information. This approach can balance the need for detailed recent context with the desire to maintain some access to older information.
Future Directions and Emerging Solutions
The development of more efficient attention mechanisms remains an active area of research, with approaches such as Flash Attention and other optimized implementations reducing the computational overhead of attention while maintaining its effectiveness. These optimizations make longer contexts more practical without requiring fundamental architectural changes.
Alternative architectures that move beyond attention mechanisms entirely, such as state space models and other sequence modeling approaches, offer the potential for much longer contexts with linear computational scaling. These approaches sacrifice some of the flexibility of attention mechanisms but may enable context lengths that are orders of magnitude longer than current transformer-based models.
The integration of external memory systems with language models offers another path toward effectively unlimited context lengths. These systems can store and retrieve information from vast external databases while maintaining the benefits of attention-based processing for the active context window.
Hardware innovations, including specialized AI accelerators designed for long-context processing, may enable more efficient processing of long sequences. These hardware advances could make current architectures practical for much longer contexts or enable new architectures that are currently computationally prohibitive.
[Reference to Training Slide: The slide deck includes visualizations of context length evolution and comparative analysis of different context management strategies.]
Chapter 8: The Boundaries of AI – Internet Access Limitations and Implications
The relationship between artificial intelligence systems and internet access represents one of the most significant architectural and philosophical decisions in modern AI development. While the internet contains vast repositories of real-time information that could theoretically enhance AI capabilities, most AI systems operate with limited or no direct internet access by design. Understanding the reasons for these limitations, their implications, and the emerging solutions to address them is crucial for comprehending the current boundaries and future potential of AI systems.
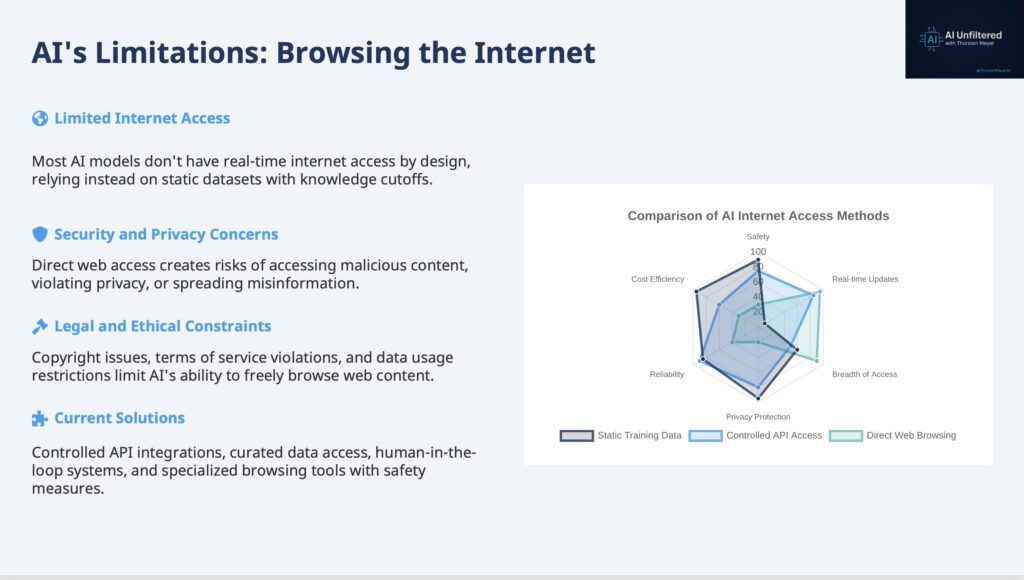
The Architecture of Isolation
The decision to limit AI systems’ internet access stems from fundamental concerns about safety, security, and reliability that go to the heart of responsible AI development. Unlike traditional software applications that routinely access network resources, AI systems present unique risks when given unrestricted internet access that have led most developers to adopt conservative approaches to connectivity.
The primary architectural approach used by most AI systems involves training on static datasets that are carefully curated and validated before being used for model development. This approach ensures that the training data is of known quality and provenance, but it also means that AI systems have knowledge cutoffs beyond which they cannot access new information. The trade-off between data quality and recency is a fundamental tension in AI system design.
The isolation of AI systems from real-time internet access also reflects concerns about the unpredictable nature of web content. The internet contains vast amounts of misinformation, malicious content, and low-quality information that could negatively impact AI system behavior if accessed indiscriminately. By using curated training datasets, AI developers can exercise greater control over the information that influences their systems.
The computational and economic considerations of real-time internet access also play a role in architectural decisions. Continuously accessing and processing internet content would require substantial computational resources and would introduce latency and reliability concerns that could affect system performance. The batch processing approach used for training on static datasets is much more efficient and predictable.
Security and Safety Considerations
The security implications of providing AI systems with internet access are multifaceted and significant. AI systems with unrestricted internet access could potentially be exploited by malicious actors who craft specific web content designed to manipulate AI behavior. This vulnerability, sometimes called “prompt injection” or “data poisoning,” could be used to cause AI systems to generate harmful or misleading content.
The potential for AI systems to inadvertently access and process sensitive or private information from the internet raises significant privacy concerns. Even if AI systems are designed to avoid accessing private information, the dynamic and complex nature of web content makes it difficult to ensure that sensitive information is never encountered or processed.
The risk of AI systems being used to conduct large-scale automated attacks on internet infrastructure is another security consideration. AI systems with internet access could potentially be used to conduct distributed denial-of-service attacks, automated spam campaigns, or other malicious activities that could harm internet infrastructure and services.
The challenge of content verification and fact-checking becomes particularly acute when AI systems access real-time internet content. Unlike curated training datasets that can be validated before use, real-time web content cannot be pre-verified, creating risks that AI systems may access and propagate false or misleading information.
Legal and Ethical Constraints
The legal landscape surrounding AI access to internet content is complex and evolving, with significant implications for how AI systems can be designed and deployed. Copyright law presents one of the most significant legal challenges, as many websites and online content sources have terms of service that restrict automated access or require explicit permission for content use.
The robots.txt protocol and other web standards provide mechanisms for website owners to specify how automated systems should interact with their content, but these standards were not designed with AI systems in mind and may not adequately address the unique characteristics of AI content processing.
Data protection regulations such as GDPR create additional legal constraints on AI systems’ ability to access and process internet content that may contain personal information. These regulations require explicit consent for processing personal data and impose strict requirements for data handling that are difficult to satisfy when accessing dynamic web content.
The ethical implications of AI systems accessing internet content without explicit consent from content creators raise important questions about fair use, attribution, and compensation. Many content creators and publishers have expressed concerns about AI systems using their content for training or inference without permission or compensation.
Current Solutions and Workarounds
Despite the limitations on direct internet access, several approaches have been developed to provide AI systems with access to current information while maintaining safety and security. Retrieval-augmented generation (RAG) systems represent one of the most successful approaches, using separate retrieval systems to access relevant information from curated knowledge bases or search engines and then providing this information to AI systems through controlled interfaces.
API-based access to specific information sources provides another approach to giving AI systems access to current information while maintaining control over the sources and types of information accessed. Weather APIs, news APIs, and other structured data sources can provide AI systems with current information without the risks associated with unrestricted web access.
Human-in-the-loop systems address internet access limitations by involving human operators who can access current information and provide it to AI systems as needed. This approach maintains human oversight and control while enabling AI systems to benefit from current information when necessary.
Curated real-time data feeds provide a middle ground between static training datasets and unrestricted internet access. These feeds involve human curation and validation of current information sources, providing AI systems with access to recent information while maintaining quality and safety standards.
The Search Integration Challenge
The integration of AI systems with search engines represents one of the most promising approaches to addressing internet access limitations while maintaining safety and control. Search engines already have sophisticated systems for crawling, indexing, and ranking web content, making them natural intermediaries for AI systems seeking access to current information.
However, the integration of AI with search systems presents its own challenges. Search engines are optimized for human users who can evaluate and filter search results, while AI systems may need different types of information organization and presentation. The ranking algorithms used by search engines may not align with the information needs of AI systems.
The computational overhead of search integration can also be significant. Each query to a search engine introduces latency and computational costs that can affect the performance and scalability of AI systems. Balancing the benefits of current information access with the costs of search integration requires careful optimization.
The quality and reliability of search results present ongoing challenges for AI systems. Search engines may return outdated, inaccurate, or biased information, and AI systems must be designed to handle these quality issues appropriately. The development of AI-specific search and information retrieval systems may be necessary to fully address these challenges.
Emerging Approaches and Future Directions
The development of specialized AI-safe browsing systems represents an emerging approach to providing AI systems with controlled internet access. These systems would implement sophisticated filtering, validation, and safety mechanisms specifically designed for AI use cases, potentially enabling broader internet access while maintaining safety and security.
Blockchain and distributed ledger technologies offer potential solutions for creating verifiable and tamper-resistant information sources that AI systems could access with greater confidence. These approaches could provide mechanisms for ensuring information provenance and integrity that are currently lacking in traditional web content.
The development of AI-specific internet protocols and standards could address many of the current limitations by providing mechanisms for content creators to specify how their content should be used by AI systems, and for AI systems to access content in ways that respect creator intentions and legal requirements.
Federated learning approaches could enable AI systems to benefit from distributed information sources without directly accessing internet content. These approaches would allow AI systems to learn from information distributed across multiple sources while maintaining privacy and security constraints.
[Reference to Training Slide: The slide deck provides comparative analysis of different approaches to AI internet access and their respective trade-offs.]
Chapter 9: The Challenge of AI Hallucinations
AI hallucinations represent one of the most significant and perplexing challenges in modern artificial intelligence, fundamentally questioning the reliability and trustworthiness of AI-generated content. These phenomena, where AI systems generate plausible but factually incorrect or entirely fabricated information, highlight the gap between statistical pattern matching and genuine understanding. The study and mitigation of AI hallucinations has become a critical area of research with profound implications for the deployment of AI systems in high-stakes applications.

Understanding the Nature of Hallucinations
AI hallucinations occur when models generate content that appears coherent and plausible but contains factual errors, fabricated information, or logical inconsistencies. Unlike simple errors or mistakes, hallucinations often involve the confident presentation of false information in ways that can be convincing to human users. This confidence makes hallucinations particularly dangerous, as users may trust AI-generated content that appears authoritative but is fundamentally incorrect.
The terminology of “hallucination” in AI draws an analogy to human perceptual hallucinations, where individuals perceive things that are not actually present. In AI systems, hallucinations represent a form of “perceptual” error where the model perceives patterns or relationships in data that do not actually exist or generates content based on spurious correlations rather than genuine understanding.
The prevalence of hallucinations varies significantly across different types of AI models and applications. Large language models are particularly susceptible to hallucinations when asked about factual information, especially regarding recent events, specific statistics, or detailed technical information. Image generation models may hallucinate visual elements that were not present in training data, while code generation models may hallucinate functions or libraries that do not exist.
The distinction between hallucinations and other types of AI errors is important for understanding and addressing these phenomena. While traditional AI errors might involve misclassification or incorrect predictions, hallucinations specifically involve the generation of content that has no basis in the training data or real-world facts. This distinction has important implications for detection and mitigation strategies.
Root Causes and Mechanisms
The fundamental cause of AI hallucinations lies in the statistical nature of modern AI models, which learn to predict likely continuations of input sequences based on patterns observed in training data. These models do not have access to external knowledge bases or fact-checking mechanisms during generation, relying instead on the statistical associations learned during training.
The training process for large language models involves learning to predict the next token in a sequence based on the preceding context. This objective encourages models to generate text that is statistically similar to their training data, but it does not explicitly encourage factual accuracy or consistency with external knowledge sources. The model learns to generate plausible-sounding text rather than necessarily true text.
The compression hypothesis suggests that hallucinations may arise from the model’s attempt to compress vast amounts of training data into a much smaller parameter space. During this compression process, the model may create spurious associations or fill in gaps in its knowledge with plausible but incorrect information. The model essentially “confabulates” information to maintain coherent output when its actual knowledge is insufficient.
Overfitting to training data patterns can also contribute to hallucinations. Models may learn to associate certain prompts or contexts with specific types of responses based on patterns in the training data, even when those associations are not logically justified. This can lead to the generation of stereotypical or formulaic responses that may not be appropriate for the specific context.
The lack of grounding in external reality is another fundamental factor contributing to hallucinations. Unlike humans, who can verify information against their sensory experience or external sources, AI models operate in a purely linguistic or symbolic space without direct access to the real world. This isolation from reality makes it difficult for models to distinguish between plausible fiction and actual facts.
Types and Categories of Hallucinations
Factual hallucinations represent the most commonly recognized type of AI hallucination, involving the generation of specific false claims about real-world entities, events, or relationships. These might include incorrect dates, false biographical information, or fabricated statistics that sound plausible but are entirely incorrect.
Fabricated citations and references represent a particularly problematic type of hallucination, where AI models generate realistic-looking academic citations, book titles, or web URLs that do not actually exist. These fabricated references can be particularly misleading because they appear to provide authoritative support for claims while actually being entirely fictional.
Logical hallucinations involve the generation of content that contains internal contradictions or logical inconsistencies. The model might make claims that contradict each other within the same response or generate arguments that appear logical but are based on flawed reasoning.
Temporal hallucinations occur when models generate information about events that could not have occurred given the model’s training cutoff date or that involve impossible temporal relationships. For example, a model might claim that a historical figure commented on recent events or that future events have already occurred.
Entity hallucinations involve the creation of fictional people, places, organizations, or other entities that do not exist in reality. These hallucinations can be particularly convincing because the model may generate consistent details about these fictional entities across multiple interactions.
Detection and Measurement Challenges
Detecting AI hallucinations presents significant technical and methodological challenges. Unlike other types of AI errors that can be measured against ground truth labels, hallucinations often involve claims about real-world facts that require external verification. This verification process can be time-consuming and may require domain expertise to evaluate properly.
Automated hallucination detection systems have been developed using various approaches, including fact-checking against knowledge bases, consistency checking across multiple model outputs, and confidence estimation techniques. However, these automated systems have limitations and may miss subtle hallucinations or flag correct information as potentially false.
The measurement of hallucination rates is complicated by the subjective nature of what constitutes a hallucination. Different evaluators may disagree about whether specific model outputs contain hallucinations, particularly for complex or nuanced claims. Developing reliable evaluation metrics and benchmarks for hallucination detection remains an active area of research.
The context-dependence of hallucinations also complicates detection efforts. Information that would be considered a hallucination in one context might be appropriate in another. For example, fictional details in a creative writing context would not be considered hallucinations, while the same details in a factual report would be problematic.
Mitigation Strategies and Approaches
Retrieval-augmented generation (RAG) represents one of the most promising approaches to reducing hallucinations by providing models with access to external knowledge sources during generation. RAG systems retrieve relevant information from knowledge bases or search engines and incorporate this information into the generation process, reducing the model’s reliance on potentially inaccurate memorized information.
Fact-checking and verification systems can be integrated into AI pipelines to identify and flag potential hallucinations before content is presented to users. These systems may use external knowledge bases, multiple model consensus, or human verification to assess the accuracy of AI-generated content.
Training techniques such as constitutional AI and reinforcement learning from human feedback (RLHF) can be used to reduce hallucination rates by explicitly training models to avoid generating false information. These approaches involve training models to recognize and avoid hallucinations through feedback mechanisms.
Confidence estimation and uncertainty quantification techniques can help identify when models are likely to hallucinate by measuring the model’s confidence in its outputs. Low-confidence outputs can be flagged for additional verification or presented to users with appropriate caveats about their reliability.
Prompt engineering techniques can be used to reduce hallucination rates by carefully crafting input prompts that encourage accurate and honest responses. These techniques might include explicit instructions to avoid speculation or to indicate when information is uncertain.
Implications for AI Deployment
The prevalence of hallucinations has significant implications for the deployment of AI systems in high-stakes applications. In domains such as healthcare, finance, or legal services, hallucinations could have serious consequences for decision-making and could potentially cause harm to individuals or organizations.
The need for human oversight and verification becomes particularly important in applications where hallucinations could be problematic. AI systems may need to be deployed with explicit human-in-the-loop mechanisms to verify important claims or decisions before they are acted upon.
The development of AI literacy among users becomes crucial for safe AI deployment. Users need to understand the limitations of AI systems and the potential for hallucinations so that they can appropriately evaluate and verify AI-generated content.
The legal and ethical implications of AI hallucinations are still being explored, with questions about liability and responsibility when AI systems generate false information. Organizations deploying AI systems may need to implement appropriate disclaimers and verification processes to manage these risks.
[Reference to Training Slide: The slide deck includes detailed visualizations of different types of hallucinations and comparative analysis of mitigation strategies.]
Chapter 10: The Mechanics of AI Question Processing
Understanding how artificial intelligence systems process and respond to human questions reveals the sophisticated yet fundamentally statistical nature of modern AI architectures. The journey from human language input to AI-generated response involves multiple complex stages of computation, each with its own challenges and limitations. This process, while appearing seamless to users, represents one of the most remarkable achievements in computational linguistics and provides insight into both the capabilities and constraints of current AI systems.

The Tokenization Foundation
The first step in AI question processing involves tokenization, the process of converting human language into discrete units that can be processed by neural networks. This seemingly simple step is actually quite complex and has profound implications for how AI systems understand and process language. Tokenization must handle the enormous diversity of human language, including different scripts, languages, punctuation, and formatting conventions.
Modern tokenization approaches typically use subword tokenization methods such as Byte Pair Encoding (BPE) or SentencePiece, which break words into smaller components that can be more efficiently processed by AI models. These methods balance the competing objectives of vocabulary size, representation efficiency, and semantic coherence. The choice of tokenization strategy affects how well models can handle rare words, different languages, and out-of-vocabulary terms.
The tokenization process also involves handling special tokens that provide structural information to the model, such as beginning-of-sequence tokens, end-of-sequence tokens, and padding tokens. These special tokens help the model understand the boundaries and structure of inputs, which is crucial for proper processing of questions and generation of appropriate responses.
The numerical encoding of tokens converts discrete symbols into continuous vector representations that can be processed by neural networks. This encoding process, typically implemented through learned embedding layers, maps each token to a high-dimensional vector that captures semantic and syntactic information about the token. The quality of these embeddings significantly affects the model’s ability to understand and process language.
Attention Mechanisms and Context Understanding
Once tokenized and encoded, the question processing moves into the attention mechanisms that form the core of modern transformer-based AI systems. The attention mechanism allows the model to dynamically focus on different parts of the input when processing each element, enabling sophisticated understanding of relationships and dependencies within the question.
The multi-head attention mechanism used in transformers computes multiple different types of attention simultaneously, allowing the model to capture various aspects of linguistic relationships. Different attention heads may focus on syntactic relationships, semantic similarities, or long-range dependencies, providing a rich representation of the input question’s structure and meaning.
The self-attention computation involves calculating compatibility scores between all pairs of tokens in the input sequence, determining how much each token should influence the processing of every other token. This computation enables the model to understand complex linguistic phenomena such as coreference resolution, where pronouns must be linked to their antecedents, and long-range dependencies that span multiple clauses or sentences.
The positional encoding component of attention mechanisms provides the model with information about the order and position of tokens in the sequence. Since attention mechanisms are inherently permutation-invariant, positional encodings are crucial for understanding the sequential nature of language and the importance of word order in determining meaning.
Pattern Recognition and Knowledge Retrieval
The pattern recognition phase of question processing involves the model identifying relevant patterns and knowledge from its training data that can be used to answer the question. This process is fundamentally statistical, relying on the model’s learned associations between input patterns and appropriate responses rather than explicit logical reasoning or knowledge retrieval.
The model’s internal representations, built up through multiple layers of attention and feed-forward computations, capture increasingly abstract patterns and relationships. Lower layers typically focus on local linguistic patterns such as phrase structure and word relationships, while higher layers capture more abstract semantic and conceptual relationships.
The knowledge encoded in the model’s parameters represents a compressed and distributed form of the information present in the training data. Unlike traditional knowledge bases with explicit facts and relationships, this knowledge is implicit in the statistical associations learned during training. The model must reconstruct relevant knowledge through pattern matching rather than explicit lookup operations.
The context integration process combines information from the current question with the model’s learned knowledge to form a comprehensive understanding of what is being asked and what type of response is appropriate. This integration involves balancing the specific details of the current question with general knowledge and patterns learned from training data.
Response Generation and Decoding
The response generation phase involves the model predicting a sequence of output tokens that form an appropriate answer to the input question. This process typically uses autoregressive generation, where each token is predicted based on the input question and all previously generated tokens in the response.
The prediction of each output token involves computing probability distributions over the entire vocabulary, with the model assigning higher probabilities to tokens that are more likely to be appropriate continuations of the response. These probability distributions are computed using the model’s learned parameters and the current context, including both the input question and the partial response generated so far.
Decoding strategies determine how the model selects specific tokens from the probability distributions computed during generation. Greedy decoding selects the highest-probability token at each step, while sampling-based approaches introduce randomness to generate more diverse responses. Advanced decoding strategies such as beam search explore multiple possible continuations simultaneously to find high-quality complete responses.
The generation process must balance multiple competing objectives, including factual accuracy, coherence, relevance to the question, and appropriate style and tone. The model learns to balance these objectives through its training process, but the relative importance of different objectives may vary depending on the specific question and context.
Quality Control and Consistency Mechanisms
Modern AI systems incorporate various mechanisms to improve the quality and consistency of their responses. These mechanisms operate at different stages of the processing pipeline and help ensure that generated responses are appropriate, coherent, and helpful.
Attention visualization and analysis techniques can provide insights into how the model is processing questions and generating responses. By examining attention patterns, researchers and developers can understand which parts of the input the model is focusing on and identify potential issues with the processing pipeline.
Consistency checking mechanisms compare generated responses with the model’s other outputs and training data to identify potential contradictions or inconsistencies. These mechanisms can help detect when the model is generating responses that conflict with its other knowledge or previous statements.
Output filtering and safety mechanisms screen generated responses for potentially harmful, inappropriate, or low-quality content. These mechanisms may use separate classifier models, rule-based filters, or human review processes to ensure that responses meet quality and safety standards.
Limitations and Failure Modes
Despite their sophistication, AI question processing systems have several fundamental limitations that affect their reliability and applicability. The statistical nature of these systems means that they may generate plausible-sounding responses that are factually incorrect or logically inconsistent, particularly for questions that require precise factual knowledge or complex reasoning.
The training data limitations affect the model’s ability to answer questions about recent events, specialized domains, or topics that were underrepresented in the training data. The model’s knowledge is essentially frozen at the time of training, and it cannot access new information or update its knowledge based on recent developments.
The lack of explicit reasoning capabilities means that AI systems may struggle with questions that require multi-step logical reasoning, mathematical computation, or causal analysis. While these systems can often generate responses that appear to demonstrate reasoning, they are actually relying on pattern matching rather than genuine logical inference.
The context limitations discussed in previous chapters also affect question processing, as models may struggle to maintain coherence and consistency across very long conversations or when processing questions that require understanding of extensive background information.
[Reference to Training Slide: The slide deck provides detailed flowcharts and visualizations of the question processing pipeline and its various components.]
Chapter 11: Environmental Impact and the Sustainability Challenge
The environmental implications of artificial intelligence development and deployment have emerged as one of the most pressing concerns in the field, challenging the technology industry to balance the transformative potential of AI with responsible stewardship of planetary resources. The energy consumption, carbon emissions, and resource utilization associated with AI systems have grown exponentially alongside their capabilities, creating an urgent need for sustainable approaches to AI development and deployment.
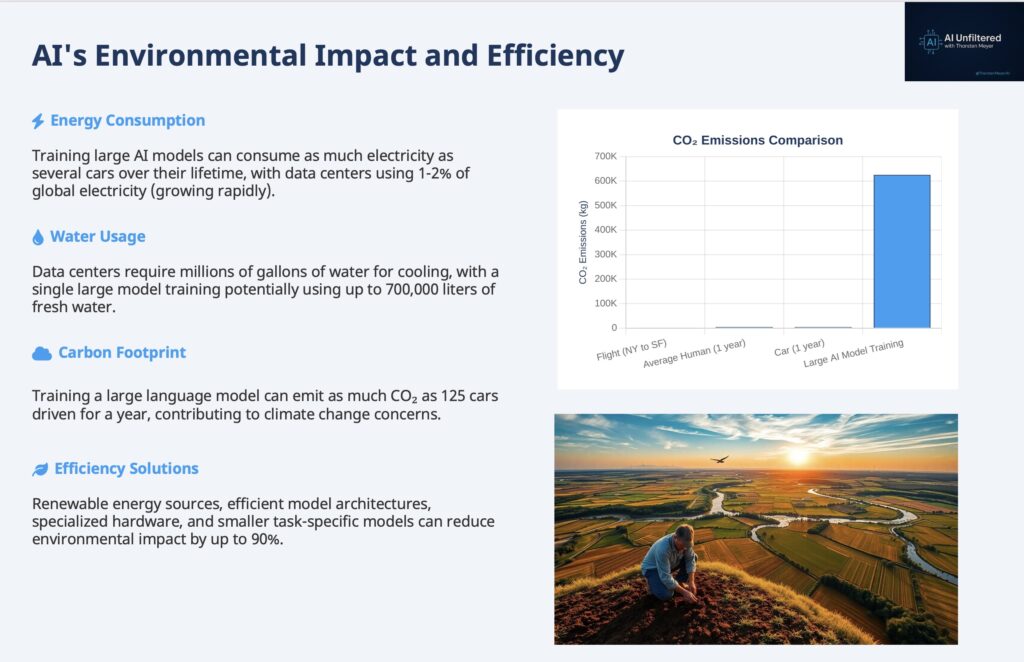
The Scale of AI’s Environmental Footprint
The environmental impact of AI systems spans multiple dimensions, from the energy consumed during model training and inference to the manufacturing of specialized hardware and the cooling requirements of data centers. Understanding the full scope of this impact requires examining the entire lifecycle of AI systems, from initial research and development through deployment and eventual decommissioning.
The training phase of large AI models represents the most energy-intensive component of the AI lifecycle. Training a single large language model can consume as much electricity as hundreds of homes use in a year, with some estimates suggesting that training the largest models requires energy equivalent to the lifetime emissions of several automobiles. These figures become even more concerning when considering that many models are trained multiple times with different hyperparameters or architectural variations.
The inference phase, while less energy-intensive per operation than training, can have enormous cumulative environmental impact due to the scale of deployment. Popular AI services may process billions of queries per day, and even small improvements in inference efficiency can translate to significant environmental benefits when multiplied across such large scales.
The manufacturing of AI hardware, particularly specialized accelerators such as GPUs and TPUs, involves energy-intensive processes and the use of rare earth materials. The rapid pace of AI hardware development means that equipment may become obsolete relatively quickly, contributing to electronic waste and requiring frequent replacement cycles that amplify the environmental impact of hardware manufacturing.
Energy Consumption Patterns and Drivers
The energy consumption of AI systems is driven by several key factors, with computational complexity being the primary determinant. The quadratic scaling of attention mechanisms in transformer models means that energy consumption can grow rapidly with model size and input length. This scaling relationship has important implications for the environmental sustainability of increasingly large AI models.
The efficiency of hardware platforms significantly affects the energy consumption of AI workloads. Modern GPUs and specialized AI accelerators are much more energy-efficient for AI computations than general-purpose CPUs, but they still consume substantial amounts of power. The choice of hardware platform can affect energy consumption by orders of magnitude for the same computational workload.
Data center efficiency plays a crucial role in determining the overall environmental impact of AI systems. Modern data centers achieve power usage effectiveness (PUE) ratios as low as 1.1, meaning that only 10% of energy is used for cooling and other overhead, while older or less efficient facilities may have PUE ratios of 2.0 or higher. The location of data centers also affects their environmental impact, with facilities powered by renewable energy sources having much lower carbon footprints than those relying on fossil fuels.
The utilization patterns of AI systems affect their energy efficiency. Systems that maintain high utilization rates make more efficient use of their energy consumption, while systems with low utilization waste energy on idle hardware. The batch processing of AI workloads can improve utilization and energy efficiency compared to processing individual requests as they arrive.
Carbon Footprint and Climate Impact
The carbon footprint of AI systems depends not only on their energy consumption but also on the carbon intensity of the electricity used to power them. Data centers powered by renewable energy sources such as solar, wind, or hydroelectric power have much lower carbon footprints than those powered by fossil fuels, even for identical computational workloads.
The geographic distribution of AI training and inference affects the overall carbon footprint of AI systems. Regions with cleaner electricity grids can provide the same computational services with lower carbon emissions, creating incentives for AI companies to locate their operations in areas with abundant renewable energy.
The temporal patterns of AI workloads can also affect their carbon footprint. Running AI workloads during times when renewable energy generation is high and grid carbon intensity is low can reduce the climate impact of AI systems. Some organizations are beginning to implement carbon-aware scheduling systems that automatically shift AI workloads to times and locations with lower carbon intensity.
The lifecycle carbon emissions of AI hardware must also be considered when evaluating the climate impact of AI systems. The manufacturing of semiconductors and other electronic components involves energy-intensive processes that contribute to the overall carbon footprint of AI systems. The rapid obsolescence of AI hardware can amplify these lifecycle emissions if equipment is replaced frequently.
Water Usage and Resource Consumption
Data centers require substantial amounts of water for cooling, and the water consumption of AI systems has become an increasingly important environmental concern. Large-scale AI training runs can indirectly consume hundreds of thousands of gallons of water through data center cooling systems, raising concerns about water scarcity and competition with other uses.
The water consumption of data centers varies significantly based on their cooling technologies and local climate conditions. Evaporative cooling systems, which are common in hot climates, consume large amounts of water but are more energy-efficient than air-based cooling systems. The choice of cooling technology involves trade-offs between water consumption and energy consumption.
The quality of water required for data center cooling also affects the environmental impact of AI systems. Some cooling systems require treated or purified water, while others can use recycled or lower-quality water sources. The development of more efficient cooling technologies that reduce water consumption is an active area of research and development.
The broader resource consumption of AI systems extends beyond energy and water to include the materials used in hardware manufacturing. The production of semiconductors requires various rare earth elements and other materials that may have limited availability or significant environmental impacts associated with their extraction and processing.
Efficiency Improvements and Optimization Strategies
Significant opportunities exist for improving the energy efficiency of AI systems through algorithmic, architectural, and systems-level optimizations. Model compression techniques such as quantization, pruning, and knowledge distillation can reduce the computational requirements of AI models while maintaining much of their performance, leading to substantial energy savings.
Efficient model architectures that achieve better performance per unit of computation can reduce the environmental impact of AI systems. Research into more efficient attention mechanisms, activation functions, and network architectures continues to yield improvements in computational efficiency that translate directly to energy savings.
Hardware-software co-optimization approaches that design AI algorithms and hardware systems together can achieve better efficiency than optimizing each component independently. These approaches consider the specific characteristics of AI workloads when designing hardware and optimize algorithms to take advantage of hardware capabilities.
Dynamic scaling and adaptive computation techniques can reduce energy consumption by adjusting the computational resources used based on the complexity of each input. These approaches avoid wasting computation on simple inputs that can be processed with less sophisticated models or fewer computational resources.
Renewable Energy and Sustainable Infrastructure
The transition to renewable energy sources represents one of the most impactful strategies for reducing the environmental impact of AI systems. Many major technology companies have committed to powering their operations with 100% renewable energy, and some have achieved this goal for their data center operations.
The development of AI-specific sustainable infrastructure includes data centers designed specifically for AI workloads with optimized cooling systems, renewable energy integration, and efficient hardware configurations. These specialized facilities can achieve better energy efficiency and lower environmental impact than general-purpose data centers.
Energy storage systems that can store renewable energy for use during periods of low renewable generation are becoming increasingly important for sustainable AI operations. Battery storage, pumped hydro storage, and other energy storage technologies enable data centers to operate on renewable energy even when the sun isn’t shining or the wind isn’t blowing.
Grid integration and demand response programs allow AI systems to adjust their energy consumption based on grid conditions and renewable energy availability. These programs can help balance electricity supply and demand while reducing the carbon intensity of AI operations.
Measurement and Reporting Frameworks
The development of standardized frameworks for measuring and reporting the environmental impact of AI systems is crucial for enabling progress toward sustainability goals. These frameworks must account for the full lifecycle impact of AI systems, including training, inference, hardware manufacturing, and end-of-life disposal.
Carbon accounting methodologies for AI systems must address the challenges of attributing emissions to specific AI workloads when multiple workloads share the same infrastructure. Accurate carbon accounting requires detailed monitoring of energy consumption and knowledge of the carbon intensity of electricity sources.
Benchmarking and comparison frameworks enable organizations to evaluate the environmental efficiency of different AI approaches and make informed decisions about technology choices. These frameworks must balance the need for standardization with the diversity of AI applications and deployment scenarios.
Transparency and disclosure initiatives encourage organizations to publicly report the environmental impact of their AI systems, creating accountability and enabling stakeholders to make informed decisions. Some organizations have begun publishing detailed environmental impact reports for their AI operations.
Future Directions and Emerging Solutions
The development of more efficient AI algorithms and architectures continues to be a major focus of research, with approaches such as sparse models, efficient attention mechanisms, and novel training techniques showing promise for reducing computational requirements while maintaining or improving performance.
Neuromorphic computing and other alternative computing paradigms offer the potential for dramatic improvements in energy efficiency for AI workloads. These approaches attempt to mimic the energy efficiency of biological neural networks and could enable AI systems that consume orders of magnitude less energy than current approaches.
Edge computing and distributed AI deployment can reduce the energy consumption associated with data transmission and enable AI processing to occur closer to where data is generated. This approach can reduce both latency and energy consumption while enabling new applications that require real-time processing.
The integration of AI systems with smart grid technologies and renewable energy systems could enable more sophisticated optimization of energy consumption and carbon emissions. AI could be used to optimize its own energy consumption based on real-time grid conditions and renewable energy availability.
[Reference to Training Slide: The slide deck includes detailed charts comparing energy consumption across different AI approaches and visualizations of carbon footprint reduction strategies.]
Chapter 12: Emergent Behavior – The Unexpected Capabilities of Large-Scale AI
Emergent behavior in artificial intelligence represents one of the most fascinating and potentially concerning aspects of modern AI development. As AI models grow in scale and complexity, they begin to exhibit capabilities that were not explicitly programmed or anticipated by their creators. These emergent behaviors challenge our understanding of how AI systems work and raise important questions about predictability, control, and the future trajectory of AI development.
Defining and Understanding Emergence
Emergent behavior in AI systems refers to capabilities or behaviors that arise spontaneously from the complex interactions of simpler components, without being explicitly designed or programmed. These behaviors typically appear suddenly as models reach certain scales or complexity thresholds, rather than developing gradually as model size increases.
The concept of emergence has deep roots in complex systems theory, where it describes how simple rules and interactions can give rise to complex, unpredictable behaviors. In biological systems, consciousness and intelligence themselves are often considered emergent properties of neural networks. In AI systems, emergence manifests as new capabilities that appear when models reach sufficient scale or complexity.
The study of emergent behavior in AI is complicated by the difficulty of predicting when and how these behaviors will appear. Unlike engineered systems where capabilities are designed and implemented deliberately, emergent behaviors arise spontaneously and may not be apparent until models are tested on specific tasks or reach particular scales.
The distinction between emergent behavior and gradual capability improvement is important for understanding AI development. While many AI capabilities improve gradually with model scale, emergent behaviors appear to involve sharp transitions where capabilities suddenly become available at specific scale thresholds.
Scale-Dependent Emergence
One of the most striking aspects of emergent behavior in AI is its dependence on model scale. Many capabilities that are entirely absent in smaller models suddenly appear when models reach certain parameter counts, training data sizes, or computational scales. This scale dependence suggests that there may be fundamental thresholds or phase transitions in AI capability development.
The relationship between model scale and emergent behavior is not simply linear. Doubling the size of a model does not necessarily double its capabilities or make emergent behaviors twice as likely to appear. Instead, emergent behaviors often appear suddenly when models cross specific scale thresholds, suggesting that there may be critical points in the scaling process.
The measurement of emergent behavior is complicated by the choice of evaluation metrics and tasks. Some researchers argue that apparent emergent behavior may actually be gradual improvement that appears sudden due to the specific metrics used to measure performance. The development of better evaluation frameworks is crucial for understanding the true nature of emergence in AI systems.
The predictability of emergent behavior remains a major challenge for AI development. While researchers have identified some patterns in when emergent behaviors appear, it is still difficult to predict exactly what new capabilities will emerge as models continue to scale. This unpredictability has important implications for AI safety and control.
Examples of Emergent Capabilities
In-context learning represents one of the most significant examples of emergent behavior in large language models. This capability, where models can learn to perform new tasks based solely on examples provided in their input context, was not explicitly trained for but emerged spontaneously in sufficiently large models. Smaller models show little to no in-context learning ability, while larger models can perform complex tasks based on just a few examples.
Chain-of-thought reasoning is another emergent capability that appears in large language models. This involves the model’s ability to break down complex problems into step-by-step reasoning processes, showing its work and intermediate steps. This capability enables models to solve problems that require multi-step reasoning and appears to emerge suddenly at specific model scales.
Tool use and API calling capabilities have emerged in some large language models without explicit training for these tasks. Models have learned to generate properly formatted API calls, use calculators and other tools, and integrate information from multiple sources. These capabilities suggest that models are developing more sophisticated understanding of how to interact with external systems.
Code generation and programming capabilities represent another area where emergent behavior has been observed. Large language models can generate functional code in multiple programming languages, debug existing code, and even write complex programs based on natural language descriptions. These capabilities were not explicitly trained for but emerged from the models’ exposure to code in their training data.
Mathematical reasoning capabilities have emerged in large language models, enabling them to solve complex mathematical problems, prove theorems, and work with abstract mathematical concepts. These capabilities suggest that models are developing sophisticated understanding of mathematical relationships and logical reasoning.
Mechanisms and Theories of Emergence
Several theories have been proposed to explain how emergent behavior arises in large AI models. The scaling hypothesis suggests that many AI capabilities are simply a function of model scale, and that sufficient scale will eventually lead to human-level or superhuman performance across a wide range of tasks. This hypothesis implies that emergence is a natural consequence of scaling existing architectures.
The phase transition theory proposes that AI models undergo sudden transitions in their internal representations or processing capabilities as they reach certain scales. These transitions may be analogous to phase transitions in physics, where systems suddenly change their fundamental properties when certain conditions are met.
The compression theory suggests that emergent behavior arises from the model’s need to efficiently compress and represent the vast amounts of information in its training data. As models become larger and more capable of compression, they may discover more efficient representations that enable new capabilities.
The grokking phenomenon, where models suddenly achieve perfect performance on tasks after extended training, provides insights into how emergent behavior might arise. Grokking suggests that models may undergo sudden transitions in their internal representations that enable dramatically improved performance.
The lottery ticket hypothesis proposes that large models contain smaller subnetworks that are responsible for specific capabilities. Emergent behavior might arise when training successfully identifies and develops these subnetworks within the larger model architecture.
Implications for AI Safety and Control
The unpredictable nature of emergent behavior raises significant concerns for AI safety and control. If AI systems can develop unexpected capabilities without explicit programming, it becomes much more difficult to ensure that these systems will behave safely and as intended. This unpredictability challenges traditional approaches to AI safety that rely on understanding and controlling system behavior.
The potential for emergent capabilities to include harmful or dangerous behaviors is a particular concern. If models can spontaneously develop new capabilities, they might also develop the ability to deceive users, manipulate systems, or cause harm in ways that were not anticipated by their creators.
The alignment problem becomes more complex when emergent behavior is considered. Ensuring that AI systems pursue intended goals and avoid harmful behaviors is challenging enough when capabilities are explicitly programmed, but becomes much more difficult when systems can develop unexpected capabilities.
The need for robust monitoring and evaluation systems becomes crucial when dealing with emergent behavior. Organizations developing AI systems must implement comprehensive testing and monitoring to detect new capabilities as they emerge and assess their potential risks and benefits.
Research Directions and Open Questions
The study of emergent behavior in AI systems is still in its early stages, with many fundamental questions remaining unanswered. Understanding the mechanisms that drive emergence, predicting when and how emergent behaviors will appear, and developing methods to control or direct emergent behavior are all active areas of research.
The development of better evaluation frameworks for detecting and measuring emergent behavior is crucial for advancing our understanding of these phenomena. Current evaluation methods may miss subtle emergent behaviors or mischaracterize gradual improvements as sudden emergence.
The relationship between different types of emergent behavior and their underlying mechanisms is another important area of research. Understanding whether different emergent capabilities arise from similar or different mechanisms could provide insights into how to predict and control emergence.
The potential for emergent behavior in other AI architectures beyond large language models is an important area of investigation. Understanding whether emergence is specific to transformer architectures or is a more general property of large-scale AI systems has important implications for future AI development.
Philosophical and Conceptual Implications
The existence of emergent behavior in AI systems raises profound philosophical questions about the nature of intelligence, consciousness, and understanding. If AI systems can develop capabilities that were not explicitly programmed, what does this say about the relationship between computation and intelligence?
The question of whether emergent behavior in AI systems represents genuine understanding or sophisticated pattern matching remains hotly debated. The ability of AI systems to exhibit complex behaviors without explicit programming challenges traditional distinctions between programmed behavior and genuine intelligence.
The implications of emergent behavior for theories of mind and consciousness are significant. If complex behaviors can emerge from simple computational processes, this may provide insights into how consciousness and intelligence arise in biological systems.
The potential for AI systems to develop forms of intelligence that are fundamentally different from human intelligence is another important consideration. Emergent behavior suggests that AI systems may develop cognitive capabilities that operate according to different principles than human cognition.
[Reference to Training Slide: The slide deck provides visual representations of emergent behavior patterns and scaling relationships that illustrate these complex phenomena.]
Conclusion: Navigating the Future of AI
The comprehensive exploration of these twelve critical aspects of modern artificial intelligence reveals a technology landscape characterized by remarkable capabilities, significant limitations, and profound implications for society. From the foundational importance of data privacy and the democratizing potential of open source models to the emerging challenges of environmental sustainability and unpredictable emergent behaviors, the current state of AI presents both unprecedented opportunities and complex challenges that require careful navigation.
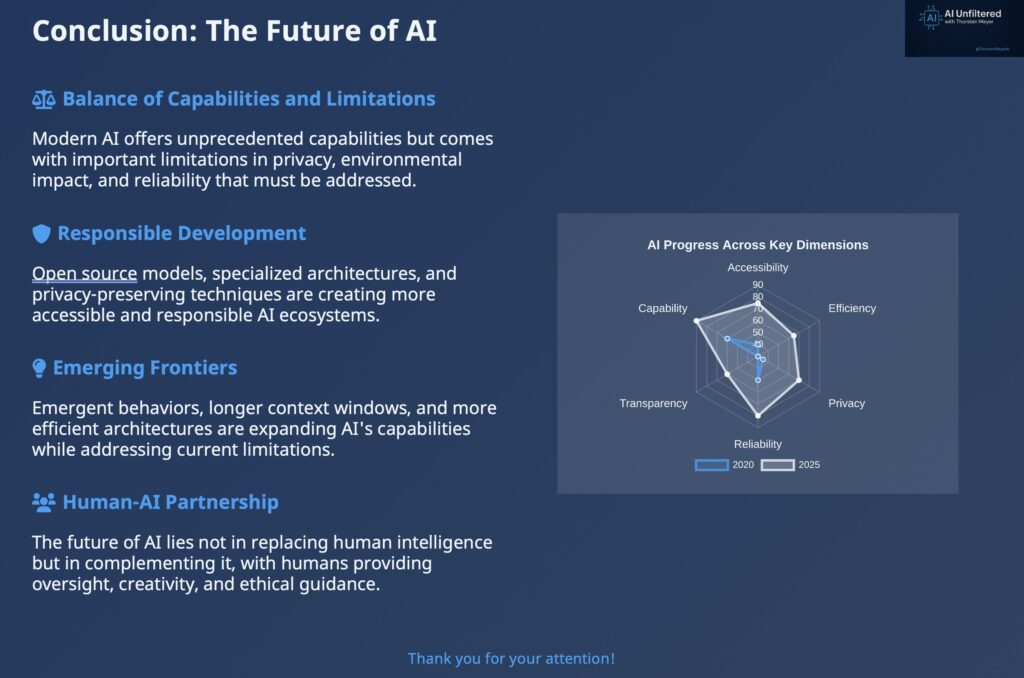
Synthesis of Key Insights
The interconnected nature of the challenges and opportunities in modern AI becomes clear when examining these topics collectively. The tension between capability and accessibility runs through many of these areas, from the computational requirements of local deployment to the economic trade-offs involved in model specialization. The balance between innovation and responsibility appears in discussions of data privacy, environmental impact, and the management of emergent behaviors.
The technical limitations of current AI systems, including context length constraints, hallucination tendencies, and internet access restrictions, highlight the gap between public perceptions of AI capabilities and the reality of current technology. Understanding these limitations is crucial for setting appropriate expectations and developing effective applications of AI technology.
The economic dimensions of AI development and deployment create important considerations for organizations seeking to leverage AI capabilities. The cost-effectiveness of specialized models, the infrastructure requirements for local deployment, and the environmental costs of large-scale AI operations all factor into strategic decisions about AI adoption and implementation.
The Path Forward
The future development of AI technology will likely be shaped by efforts to address the current limitations and challenges identified in this analysis. Advances in efficient architectures, improved training methodologies, and better integration with external knowledge sources may help address issues such as hallucinations, context limitations, and environmental impact.
The continued evolution of the open source AI ecosystem will play a crucial role in democratizing access to AI capabilities and fostering innovation across diverse communities. The balance between open development and responsible deployment will require ongoing attention to ensure that the benefits of AI are broadly shared while minimizing potential risks.
The development of sustainable AI practices will become increasingly important as the scale of AI deployment continues to grow. This includes not only environmental sustainability but also economic sustainability and the long-term viability of AI development approaches.
Implications for Stakeholders
For AI developers and researchers, this analysis highlights the importance of considering the full lifecycle and broader implications of AI systems, from initial development through deployment and eventual decommissioning. The technical challenges identified here represent important areas for continued research and development.
For organizations considering AI adoption, understanding these fundamental aspects of AI technology is crucial for making informed decisions about technology choices, deployment strategies, and risk management. The trade-offs between different approaches to AI implementation require careful consideration of organizational needs and constraints.
For policymakers and regulators, the challenges and limitations of current AI technology provide important context for developing appropriate governance frameworks. The rapid pace of AI development and the emergence of unexpected capabilities require adaptive and flexible approaches to regulation.
For the broader public, understanding these aspects of AI technology is important for developing realistic expectations about AI capabilities and limitations. AI literacy will become increasingly important as AI systems become more prevalent in daily life.
The Role of Education and Training Resources
The accompanying slide deck serves as a visual learning companion to this comprehensive analysis, providing interactive charts, diagrams, and visualizations that help illustrate complex concepts and relationships. The combination of detailed textual analysis with visual learning materials recognizes that different individuals learn most effectively through different modalities and that complex technical concepts often benefit from multiple forms of presentation.
The educational value of understanding these fundamental aspects of AI extends beyond technical knowledge to include broader literacy about how AI systems work, their limitations, and their implications for society. As AI becomes increasingly integrated into various aspects of life and work, this understanding becomes crucial for informed participation in discussions about AI development and deployment.
The rapid pace of change in AI technology means that education and training resources must be continuously updated to reflect new developments and emerging challenges. The framework provided by these twelve key areas offers a structured approach to understanding AI that can accommodate new developments while maintaining focus on fundamental principles and challenges.
Final Reflections
The current moment in AI development represents a critical juncture where the decisions made about technology development, deployment practices, and governance frameworks will have lasting implications for the future of AI and its impact on society. The challenges and opportunities identified in this analysis require thoughtful consideration and collaborative effort across technical, policy, and social domains.
The remarkable capabilities of modern AI systems, from their ability to understand and generate human language to their potential for solving complex problems across diverse domains, represent genuine achievements that have the potential to benefit humanity in profound ways. However, realizing this potential while managing the associated risks and challenges requires continued attention to the fundamental issues explored in this analysis.
The future of AI will be shaped not only by technical advances but also by how well we address the broader challenges of privacy, sustainability, fairness, and control. The comprehensive understanding of these issues provided by this analysis and its accompanying training materials offers a foundation for informed participation in shaping that future.
References and Further Reading
[1] Vaswani, A., et al. (2017). “Attention Is All You Need.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/1706.03762
[2] Brown, T., et al. (2020). “Language Models are Few-Shot Learners.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/2005.14165
[3] Bommasani, R., et al. (2021). “On the Opportunities and Risks of Foundation Models.” Stanford Institute for Human-Centered Artificial Intelligence. https://arxiv.org/abs/2108.07258
[4] Strubell, E., Ganesh, A., & McCallum, A. (2019). “Energy and Policy Considerations for Deep Learning in NLP.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. https://arxiv.org/abs/1906.02243
[5] Wei, J., et al. (2022). “Emergent Abilities of Large Language Models.” Transactions on Machine Learning Research. https://arxiv.org/abs/2206.07682
[6] Fedus, W., Zoph, B., & Shazeer, N. (2022). “Switch Transformer: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” Journal of Machine Learning Research. https://arxiv.org/abs/2101.03961
[7] Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” OpenAI. https://arxiv.org/abs/2001.08361
[8] Dwork, C., & Roth, A. (2014). “The Algorithmic Foundations of Differential Privacy.” Foundations and Trends in Theoretical Computer Science. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
[9] McMahan, B., et al. (2017). “Communication-Efficient Learning of Deep Networks from Decentralized Data.” Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. https://arxiv.org/abs/1602.05629
[10] Hinton, G., Vinyals, O., & Dean, J. (2015). “Distilling the Knowledge in a Neural Network.” NIPS Deep Learning and Representation Learning Workshop. https://arxiv.org/abs/1503.02531
About the Training Resource: This article is accompanied by an interactive slide deck that provides visual learning materials, charts, and diagrams to complement the detailed analysis presented here. The slide deck is designed to serve as a training resource for individuals and organizations seeking to understand the fundamental concepts and challenges in modern AI development and deployment.







