
Thorsten Meyer | ThorstenMeyerAI.com | March 2026
Executive Summary
Multi-agent execution is no longer experimental. The autonomous AI agent market will reach $8.5 billion by 2026 and $35 billion by 2030 — potentially $45 billion if enterprises orchestrate agents effectively (Deloitte). Gartner reports a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025. 40% of enterprise applications will embed AI agents by 2026. But only 28% of enterprises believe they have mature capabilities for agent orchestration (Deloitte, n=550), and 40%+ of agentic projects will be canceled by 2027.
The value is not in deploying more agents. It is in orchestrating parallel execution — multiple agents working concurrently across research, drafting, validation, and execution — with the governance architecture that makes the output trustworthy.
Parallel web execution cuts processing time by 60–80% through concurrent task decomposition (coordinator pattern benchmarks). But without verifier gates, evidence citations, and human checkpoints, parallel execution amplifies failure modes as fast as it amplifies throughput: correlated hallucinations, context poisoning, duplicated work, and uncontrolled side effects.
The playbook is not “run more agents.” It is “run the right agents, in the right pattern, with the right controls.”
| Metric | Value |
|---|---|
| Autonomous agent market (2026) | $8.5B (Deloitte) |
| Autonomous agent market (2030) | $35–45B (Deloitte) |
| Multi-agent inquiry surge | 1,445% (Gartner, Q1 2024–Q2 2025) |
| Enterprise apps with agents (2026) | 40% (Gartner) |
| Mature orchestration capability | 28% (Deloitte, n=550) |
| Basic automation maturity | 80% (Deloitte) |
| 3-year ROI: basic automation | 45% expect returns (Deloitte) |
| 3-year ROI: automation + agents | 12% expect returns (Deloitte) |
| Agentic projects canceled by 2027 | 40%+ (Gartner) |
| Process time reduction | 30–50% (enterprise benchmarks) |
| Coordinator pattern time savings | 60–80% (architecture benchmarks) |
| Task time recovered per person | 40–60% on automated tasks |
| Operational efficiency gains | 72% (industry benchmarks) |
| Error rate reduction | 7% to 3% (claims processing) |
| Rework request decline | 15% (compliance) |
| Productivity improvements | 66% report measurable gains |
| CHROs: digital labor integration | 86% see as central role |
| OECD unemployment | 5.0% (stable) |
| OECD youth unemployment | 11.2% |
Top picks for "parallel playbook capture"
Open Amazon search results for this keyword.
As an affiliate, we earn on qualifying purchases.
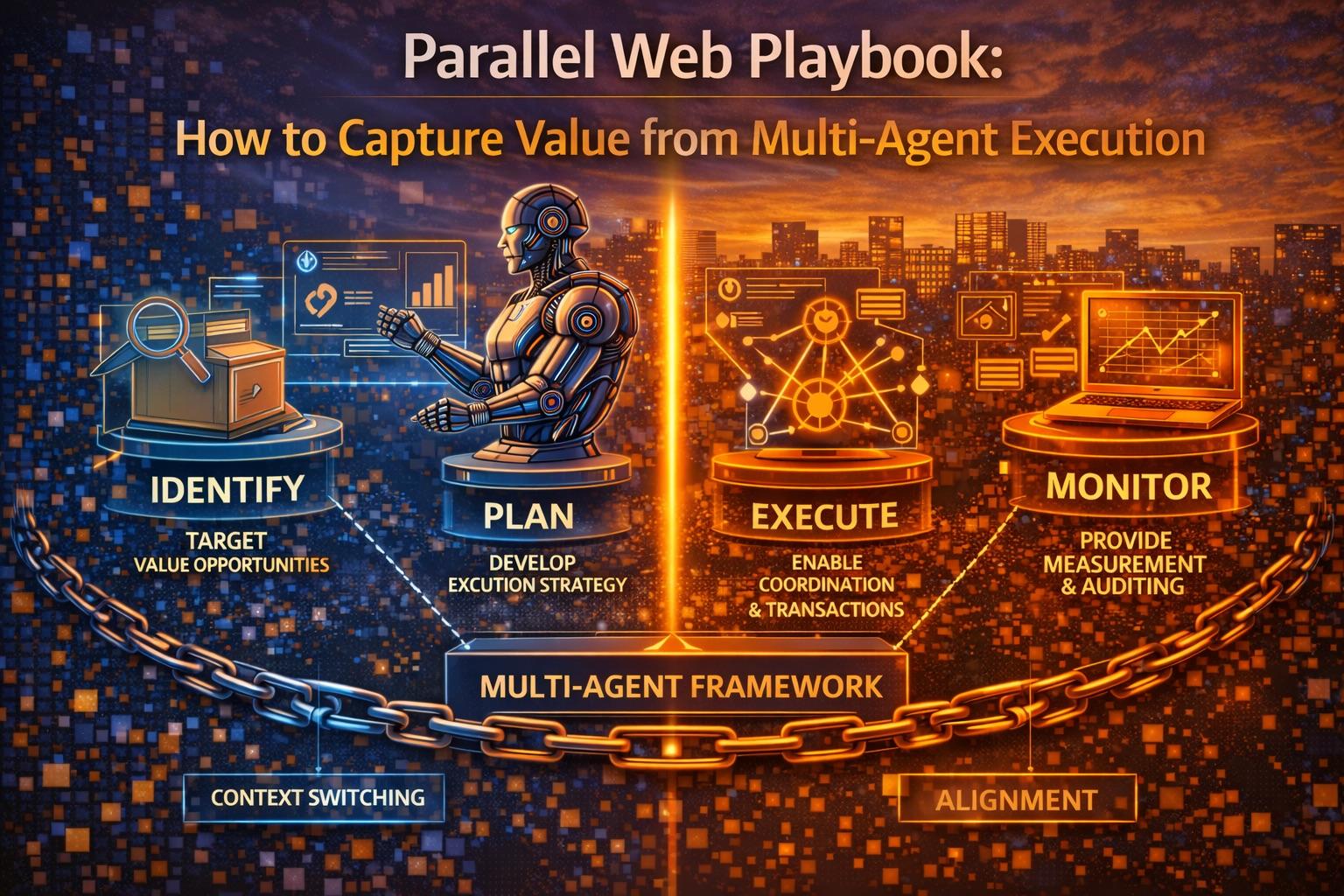
1. The Operating Model: Four Roles, Not Four Hundred Agents
A high-performing parallel execution setup does not require dozens of agents. It requires four well-defined roles with clear authority boundaries.
The Four-Role Architecture
| Role | Function | Authority | Failure If Missing |
|---|---|---|---|
| Coordinator | Task decomposition, dependency graph, resource allocation | Assigns tasks; sets deadlines; resolves conflicts | No parallelism — sequential bottleneck |
| Specialist agents | Domain/tool-specific execution (research, drafting, data, code) | Executes within assigned scope; no cross-boundary actions | No depth — generalist outputs at specialist cost |
| Verifier | Cross-checks outputs, scores evidence quality, flags contradictions | Blocks promotion of unverified outputs | Correlated hallucinations propagate unchecked |
| Human checkpoint | Final authority on consequential actions (spend, publish, deploy) | Approves or rejects; escalates; overrides | Uncontrolled autonomy — liability gap |
Why Four Roles, Not One
Single-agent architectures create a “token bottleneck”: one context window processing everything sequentially. Multi-agent parallel execution distributes cognitive load across specialized contexts, each optimized for a specific task type.
The coordinator pattern specifically eliminates the back-and-forth overhead that makes single-agent execution slow and expensive. Plan-and-execute designs reduce costs by up to 90% compared to routing everything through frontier models (architecture benchmarks).
The Dependency Graph
The coordinator’s primary output is a dependency graph (DAG) — a directed acyclic graph that maps which tasks can run in parallel, which must wait for upstream outputs, and which require human checkpoints before proceeding.
| DAG Element | Purpose | Example |
|---|---|---|
| Parallel branches | Independent tasks that can execute concurrently | Market research + competitor analysis + regulatory scan |
| Sequential gates | Tasks that require upstream output | Draft report → verifier review → human approval |
| Merge points | Where parallel outputs are synthesized | Three research streams → unified briefing |
| Checkpoint nodes | Human approval required before continuation | Spend authorization, publication, deployment |
“The value of parallel execution is not running more agents. It is knowing which tasks can run simultaneously and which must wait — and enforcing that distinction automatically.”
2. Throughput Gains: What the Data Shows
Measurable Improvements
| Gain Type | Data | Source |
|---|---|---|
| Processing time reduction | 60–80% (coordinator pattern) | Architecture benchmarks |
| Process time savings | 30–50% | Enterprise benchmarks |
| Task time recovered | 40–60% per person on automated tasks | Industry data |
| Operational efficiency | 72% gains reported | Industry benchmarks |
| Cost reduction | Up to 90% vs. frontier-only routing | Plan-and-execute patterns |
| Error rate improvement | 7% → 3% (claims processing) | Enterprise deployment |
| Rework decline | 15% | Compliance department data |
| Accuracy improvement | 53% higher | Industry benchmarks |
| ROI in customer experience | 128% | Industry benchmarks |
Where Gains Are Real
Parallel execution delivers strongest returns in workflows with these characteristics:
| Characteristic | Why Parallel Wins | Example |
|---|---|---|
| Multiple independent inputs | No sequential dependency | Research from 5+ sources simultaneously |
| Time-sensitive synthesis | Faster than serial processing | Market intelligence briefing |
| High option coverage | More perspectives explored | Strategy options analysis |
| Verification-heavy | Parallel cross-checking | Financial data validation |
| Multi-format output | Simultaneous generation | Report + slides + data model |
Where Gains Are Illusory
Not every workflow benefits from parallelism. Workflows with tight sequential dependencies, single-source data, or high coordination overhead can be slower and more expensive with parallel execution than with a well-designed single agent.
| Anti-Pattern | What Goes Wrong | Better Approach |
|---|---|---|
| Forced parallelism on sequential tasks | Coordination overhead exceeds time saved | Single specialist agent |
| Too many agents, too little work | Idle agents consuming tokens | Right-size the swarm |
| Parallel without verification | Speed amplifies errors | Add verifier gate |
| Agent sprawl | Uncoordinated proliferation | Strict role boundaries |
“The coordinator pattern cuts processing time by 60–80%. The anti-coordinator pattern — running agents without a dependency graph — cuts quality by the same margin.”
3. Failure Modes: What Breaks When Agents Run in Parallel
The failure modes of parallel execution are qualitatively different from single-agent failures. They are systemic, correlated, and harder to detect.
The Five Failure Modes
| Failure Mode | What Happens | Why It Is Worse in Parallel | Mitigation |
|---|---|---|---|
| Correlated hallucination | Multiple agents hallucinate the same false information from shared training data | Convergent agreement creates false confidence | Independent model diversity; verifier with different knowledge base |
| Context poisoning | One agent’s hallucinated output enters another’s context as trusted input | Errors compound across the execution graph | Context isolation; evidence provenance tracking |
| Duplicated work | Agents duplicate effort without coordination | Wasted tokens and contradictory outputs | Coordinator deconfliction; task assignment registry |
| Context fragmentation | No agent has the full picture; synthesis is lossy | Critical connections missed between partial outputs | Merge-point architecture; shared evidence store |
| Uncontrolled side effects | Agents execute external actions (API calls, emails, purchases) without coordination | Multiple agents may trigger conflicting or redundant actions | Action registry; human checkpoint for external effects |
The Monoculture Risk
When multiple agents use the same underlying model, training data, and prompting patterns, their errors correlate. This is the multi-agent equivalent of a systemic risk: diversification provides no protection when all agents fail in the same way.
The mitigation is architectural: use different models for different roles, require independent evidence sources, and design the verifier to challenge rather than confirm.
Context Poisoning: The Compound Error
Context poisoning is the most dangerous parallel failure mode because it is self-reinforcing. Once incorrect information enters the execution graph as a trusted input, downstream agents build on it without question. The result: a coherent but false output that passes surface-level review because every agent agrees.
Detection requires the verifier to maintain independent context — separate from the execution graph — and cross-reference outputs against primary sources, not against each other.
“The most dangerous output from a parallel system is the one where all agents agree — because agreement from correlated sources is not evidence. It is an echo chamber.”
4. OECD Context: Connectivity Is Not the Constraint
OECD regional broadband data shows household penetration exceeding 98% in advanced economies (e.g., German TL3 regions at 98.9%). Infrastructure connectivity is not the bottleneck for parallel AI-enabled workflows.
Where the Bottleneck Actually Is
| Bottleneck | Data | Implication |
|---|---|---|
| Orchestration maturity | 28% (Deloitte) | 72% cannot orchestrate effectively |
| ROI from agents | 12% expect 3-year returns (Deloitte) | 88% not seeing agent-specific ROI |
| Basic automation maturity | 80% (Deloitte) | Automation mature; agent orchestration is not |
| Project cancellation rate | 40%+ by 2027 (Gartner) | Majority of projects fail scaling |
| Governance maturity | 21% (Deloitte) | 79% without mature governance |
| Internal data quality | Primary constraint | Agents are only as good as input data |
| Process architecture | Primary constraint | Parallel execution requires redesigned workflows |
The gap between automation maturity (80%) and agent orchestration maturity (28%) is the single most important signal. Enterprises can automate — they cannot yet orchestrate. The bottleneck is process architecture and governance, not infrastructure or model capability.
Labour Market Context
| OECD Signal | Value | Parallel Web Implication |
|---|---|---|
| Unemployment | 5.0% (stable) | Tight labour → parallel execution augments, not replaces |
| Youth unemployment | 11.2% | Entry-level orchestration roles emerging |
| High automation risk | 27% | Task reallocation through parallel workflows |
| Broadband | 98.9% (advanced) | Infrastructure ready for parallel AI |
Transparency note: OECD does not directly measure multi-agent orchestration maturity or parallel execution readiness. The indicators above are infrastructure and labour market proxies. Enterprise-specific orchestration benchmarks remain limited to vendor surveys and case studies.
5. Implementation Pattern: The Bounded Process Start
Step-by-Step Implementation
| Step | Action | Why It Matters |
|---|---|---|
| 1 | Select one bounded process (e.g., market intelligence briefing) | Limits blast radius; generates measurable baseline |
| 2 | Decompose into parallelizable subtasks | Identifies true independence vs. false parallelism |
| 3 | Assign specialist agents per subtask | Scoped context; no cross-contamination |
| 4 | Force evidence citations per subtask | Every claim traceable to source; hallucination detectable |
| 5 | Introduce verifier gates before external action | Blocks unverified outputs from reaching customers, markets, or production |
| 6 | Add human checkpoint for consequential decisions | Legal defensibility; regulatory compliance |
| 7 | Measure rework rate and confidence calibration | Continuous improvement signal |
What to Measure
| Metric | What It Tells You | Target |
|---|---|---|
| Rework rate | How often outputs need human correction | <10% for Tier 1 workflows |
| Confidence calibration | Do agent confidence scores predict actual accuracy? | Correlation >0.7 |
| Evidence citation rate | Percentage of claims with traceable sources | >90% for published outputs |
| Verifier catch rate | How often the verifier blocks bad output | Track trend, not absolute |
| Human override rate | How often humans override agent recommendations | 5–15% (healthy range) |
| Time to first output | Parallel execution speed vs. sequential baseline | 60–80% reduction target |
| Cost per output | Total token + compute + human review cost | Below sequential baseline |
The Market Intelligence Briefing Example
A practical first deployment: the weekly market intelligence briefing.
| Agent | Task | Parallel? | Output |
|---|---|---|---|
| Coordinator | Decompose briefing into subtasks | Sequential (first) | Task graph with dependencies |
| Research Agent 1 | Competitor news + filings | Parallel | Sourced competitor summary |
| Research Agent 2 | Market data + analyst reports | Parallel | Market trends with citations |
| Research Agent 3 | Regulatory + policy updates | Parallel | Regulatory scan with sources |
| Synthesizer | Merge research into unified briefing | Sequential (after parallel) | Draft briefing |
| Verifier | Cross-check citations, flag contradictions | Sequential (after synthesis) | Verified briefing + confidence scores |
| Human reviewer | Approve for distribution | Sequential (final) | Published briefing |
“Start with one bounded process. Get the orchestration right. Then expand. The organizations that try to parallelize everything at once are the 40% that cancel by 2027.”
6. Practical Actions for Leaders
1. Fund orchestration engineering, not only model licenses. The bottleneck is not model capability — 80% have mature automation. The bottleneck is orchestration: dependency graphs, verifier architecture, checkpoint design, and evidence management. Hire orchestration engineers, not just prompt engineers.
2. Set hard caps on autonomous external actions. No agent should send emails, execute purchases, call external APIs, or publish content without human approval or verifier gate. Uncontrolled side effects are the highest-liability failure mode in parallel execution.
3. Use “confidence + evidence quality” as promotion criteria. Agent outputs should not advance based on completion alone. Promotion criteria: confidence score above threshold, evidence citations verified, no verifier flags. This is the quality gate that prevents correlated hallucination from reaching production.
4. Build incident playbooks for parallel-run divergence. When agents produce contradictory outputs from the same inputs, the organization needs a defined response: which output wins, who arbitrates, how the divergence is logged, and what it signals about the underlying data or model.
5. Track the orchestration maturity gap. The 80% automation vs. 28% orchestration gap is your benchmark. Measure where your organization falls on both scales. Close the orchestration gap before deploying more agents.
| Action | Owner | Timeline |
|---|---|---|
| Orchestration engineering investment | CTO + CIO | Q2 2026 |
| External action caps | CISO + CTO | Q2 2026 |
| Confidence + evidence promotion criteria | CIO + Operations | Q2 2026 |
| Parallel-run divergence playbook | CISO + Operations | Q3 2026 |
| Orchestration maturity assessment | CIO + Risk | Q2 2026 |
What to Watch
Platform-native DAG orchestration. Temporal, LangGraph, and enterprise workflow platforms are adding native support for directed acyclic graph orchestration of agent tasks. When DAG orchestration becomes a platform feature rather than custom engineering, the 28% orchestration maturity figure will accelerate. Watch for GA announcements from major cloud providers within 12 months.
Cross-agent memory controls. The context poisoning problem requires architectural solutions: shared evidence stores with provenance tracking, context isolation between agents, and memory access controls that prevent one agent’s hallucination from contaminating another’s context. This is the next security frontier after identity and policy.
Verifier tooling as competitive moat. The verifier role — independent cross-checking, evidence scoring, contradiction detection — is currently custom-built. The vendor that ships production-ready verifier tooling (not just guardrails, but active evidence verification) captures the trust layer of the multi-agent stack.
The Bottom Line
$8.5B market in 2026. 1,445% inquiry surge. 80% automation maturity vs. 28% orchestration maturity. 60–80% processing time reduction. 40%+ projects canceled. 12% expect agent ROI. 72% cannot orchestrate effectively.
The parallel web is not an efficiency story. It is an orchestration story. The throughput gains are real — 60–80% faster, 30–50% process time savings, measurable error reduction. But the gains accrue only to organizations that solve the orchestration problem: dependency graphs, verifier gates, evidence management, and human checkpoints.
The 52-point gap between automation maturity (80%) and orchestration maturity (28%) is where enterprise value either gets captured or gets destroyed. The organizations that close this gap will run multi-agent execution as a production operating model. The organizations that deploy agents without orchestration will join the 40% that cancel by 2027.
The parallel web playbook is three words: orchestrate, verify, checkpoint. Everything else is an expensive way to hallucinate faster.
Thorsten Meyer is an AI strategy advisor who notes that the phrase “just add more agents” is the 2026 version of “just add more servers” — and will age about as well. More at ThorstenMeyerAI.com.
Sources
- Deloitte — Autonomous Agent Market: $8.5B (2026), $35–45B (2030)
- Deloitte Tech Value Survey (n=550) — 80% Automation Maturity, 28% Orchestration, 12% Agent ROI
- Deloitte — 86% CHROs: Digital Labor Integration Central
- Gartner — 1,445% Multi-Agent Inquiry Surge (Q1 2024–Q2 2025)
- Gartner — 40% Enterprise Apps with Agents (2026)
- Gartner — 40%+ Agentic Projects Canceled by 2027
- Architecture Benchmarks — Coordinator Pattern 60–80% Time Reduction
- Enterprise Benchmarks — 30–50% Process Time Reduction
- Industry Data — 40–60% Task Time Recovered, 72% Efficiency Gains
- Enterprise Deployment — Error Rate 7% → 3%, Rework Decline 15%
- Industry Benchmarks — 53% Accuracy, 128% CX ROI, 52% Cost Reduction
- Plan-and-Execute Pattern — Up to 90% Cost Reduction vs. Frontier-Only
- Multi-Agent Architecture Research — Correlated Hallucination, Context Poisoning, Monoculture Risk
- Deloitte State of AI 2026 — 21% Mature Governance
- OECD — 5.0% Unemployment, 11.2% Youth (Feb 2026)
- OECD — 27% Jobs at High Automation Risk
- OECD — Regional Broadband Data (98.9% German TL3)
© 2026 Thorsten Meyer. All rights reserved. ThorstenMeyerAI.com