Part 9 of a five-day series on the 2026 memory crunch. The earlier chapters diagnosed the squeeze across every front; this one is the decision chapter — what to actually do with your money.
Eight chapters in, the diagnosis is complete and uncomfortable: memory got expensive everywhere. It’s dear to buy, dear to rent, and the relief isn’t coming on the old schedule. Faced with that, most people frame the choice as a fork in the road — build your own hardware, or rent it from the cloud — and argue about which is cheaper.
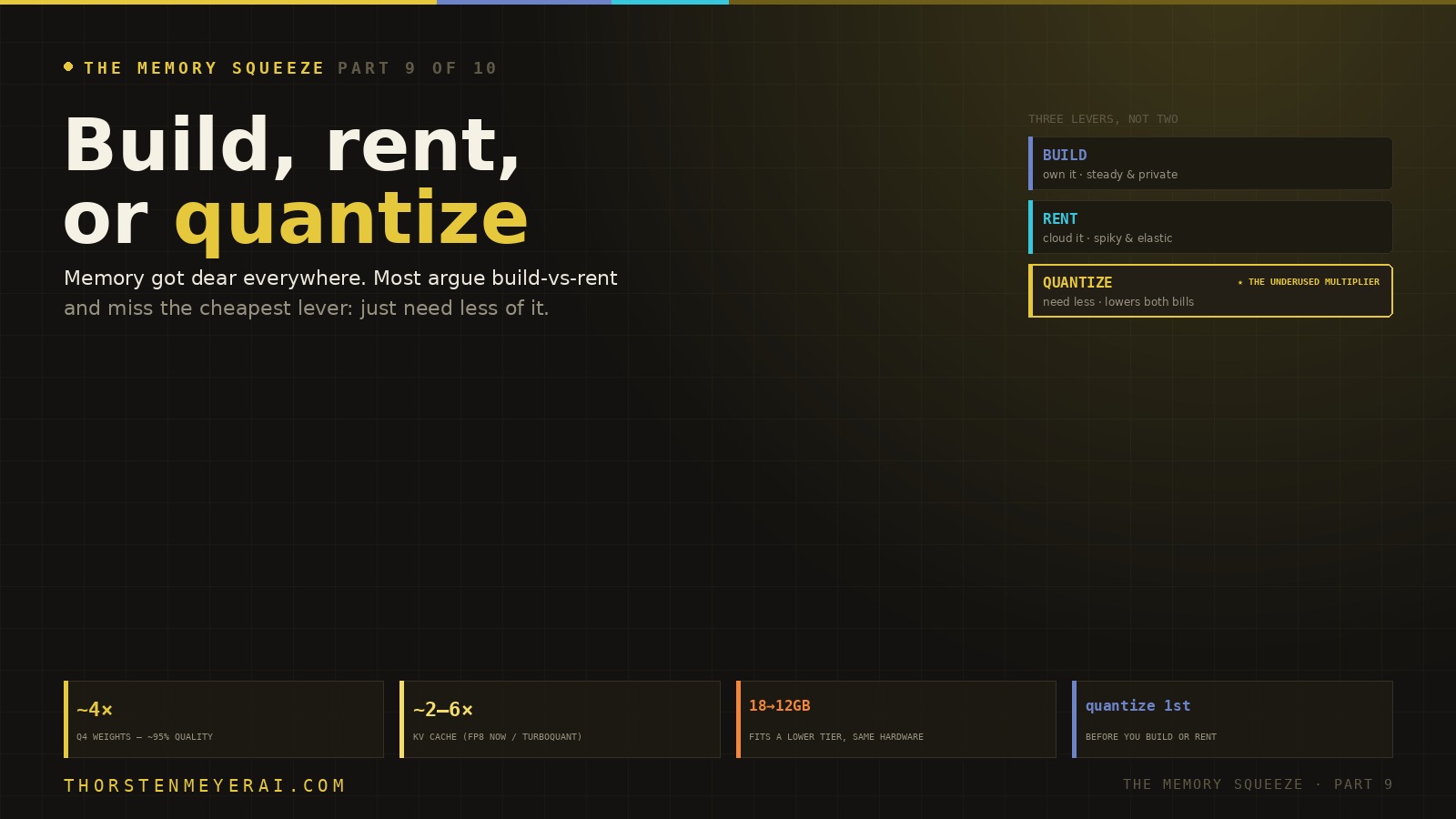
That framing misses the most powerful move available, because it treats your memory requirement as fixed. It isn’t. There’s a third lever, and it’s the cheapest of the three: quantize — shrink how much memory the work needs in the first place. Build and rent are the venue question. Quantize is the question that lowers the bill in either venue. Here’s how all three fit together.
Build, rent, or quantize
Memory got expensive everywhere — to buy and to rent. Most people argue build-vs-rent and miss the cheapest lever: shrink how much memory the work needs in the first place. Cut the bill without cutting capability.
For steady, high-utilization, private work. ~½ the lifetime cost of cloud. Right-size, used 3090s, or Apple unified memory. Capital up front.
For elastic, spiky, uncertain work. Can’t buy half a cluster for two weeks. But the bill creeps up — rent defensively: reserve, right-size, monitor.
Make the model need less memory — modern compression does it at little quality cost. The one move that lowers the bill in both venues.
★ the underused multiplierThe mistake the squeeze punishes hardest is solving a memory problem by buying more memory, when you could have needed less. Build when ownership pays, rent when flexibility pays — and quantize always, because shrinking the requirement is the only lever that makes both cheaper at once, and the only one that’s nearly free. The first question is never “build or rent” — it’s “how little memory can this take?” Next: when does cheap memory come back?
Lever one: Build
Owning the hardware wins when your workload is steady and high-utilization — a model you’ll run for hours a day, every day, for years. As Part 6 showed, an owned rig can cost roughly half what the equivalent cloud instance does over its life, and the gap widened when the squeeze pushed cloud prices up. Add privacy, offline operation, and no per-token meter, and for a always-on local-inference box the case is strong.
The discipline, from Parts 7 and 8, is to right-size and buy smart: target the model class you actually run, take the cheap high-value step to 24GB of VRAM, reach for used RTX 3090s on VRAM-per-dollar, or use Apple Silicon’s unified memory to get capacity without a multi-GPU rig. The cost is capital up front and a bet that your needs are stable. If they are, building is the cheapest long-run answer.

AI Systems Performance Engineering: Optimizing Model Training and Inference Workloads with GPUs, CUDA, and PyTorch
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Lever two: Rent
The cloud wins when your workload is elastic, spiky, or uncertain — bursts of experimentation, variable traffic, a model you’ll run hard for a month and then not at all. You can’t buy half a GPU cluster for two weeks, and providers hedge scarce hardware better than any individual buyer. The catch, from Part 6, is the hidden and rising bill: instance prices creeping up, memory-optimized SKUs leading the increases, discounts that stay fixed while absolute costs climb.
So renting well means renting defensively: right-size relentlessly (idle RAM is now the most expensive waste on the invoice), lock pricing with reserved terms and savings plans before the next adjustment, and treat cost as a continuous monitoring problem rather than a quarterly review. Rent for the flexibility; pay only for what you actually use.

The Burrows-Wheeler Transform:: Data Compression, Suffix Arrays, and Pattern Matching
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Lever three: Quantize — the lever everyone underuses
Here’s the move that changes the other two. Instead of paying for more memory, you make the model need less — and modern compression does this with surprisingly little quality cost. There are two distinct knobs, and conflating them is the most common mistake.
Weight quantization compresses the model’s parameters from 16-bit down to 4-bit. This is the single most impactful optimization for fitting a model on the hardware you have: Q4_K_M cuts memory by nearly 4× while retaining roughly 95% of full-precision quality — which is exactly why Q4 is what serious local users actually run. It shrinks the weights, the largest fixed cost of loading a model.
KV-cache compression is a separate knob, and it’s the one that matters at long context. The key-value cache grows with the length of your conversation, and it quietly becomes the bottleneck: at 128K tokens, a 70B model’s cache alone can consume ~40GB — on top of the weights. Today’s production-safe option is FP8 KV-cache quantization (built into runtimes like vLLM), which roughly halves that with negligible quality loss. The headline-grabber is Google’s TurboQuant, unveiled in March 2026: it compresses the cache to ~3 bits for a ~6× reduction with near-zero accuracy loss, validated to 100K-token contexts. The honest caveat — and it matters — is that as of mid-2026 TurboQuant is not yet built into the major inference frameworks; Google’s official implementation is targeted for later in the year, with community forks (including Apple Silicon builds) available for the adventurous. The pragmatic stack right now is Q4_K_M weights plus FP8 KV cache today, with TurboQuant as the upgrade you adopt the moment it lands in your runtime.
Stack these and the payoff is concrete: a model that needed, say, 18GB can be made to fit in ~12GB — which means the next hardware tier becomes reachable on the hardware you already own, or the same model runs on a cheaper card, or your cloud instance serves far more concurrent users at long context. You reached a higher capability without buying more memory. In a shortage, that is the highest-leverage move there is.
A related trick worth knowing: Mixture-of-Experts models activate only a fraction of their parameters per token, so they run fast for their size — but be precise about why. MoE saves compute and speed, not always footprint: all the expert weights still have to live in memory. It’s a capability-per-token win, not a free memory cut.
FP16 memory optimizer hardware
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The honest limits
Quantization is leverage, not magic, and overselling it is its own trap.
Push weights below Q4 and quality degrades visibly, especially on reasoning and code — the place not to economize. TurboQuant is real, peer-reviewed, and validated, but it isn’t yet a one-line setting in vLLM or Ollama; treat the 6× as a near-future upgrade, not a button you press today. MoE helps speed, not necessarily the memory footprint. And compression buys you roughly one tier, sometimes two — it does not make memory infinite. The right mental model: quantization reliably shifts you one rung down the hardware ladder at modest-to-zero quality cost, which in this market is worth a great deal — but it’s a discount, not a cancellation, of the memory tax.
cloud GPU rental service
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The decision
Put together, the three levers resolve into a simple framework rather than a single answer:
- Steady, high-utilization, privacy-sensitive work → Build. Right-sized, quantized, owned. Cheapest over its life.
- Elastic, spiky, uncertain work → Rent. Right-sized, reserved, monitored. Pay for flexibility, not idle capacity.
- Either way → Quantize first. Before you spec a build or a cloud instance, ask how small you can make the requirement. Q4 weights and FP8 KV cache cost almost nothing and routinely save you a hardware tier or a chunk of your instance bill. It’s the one move that lowers the cost in both venues.
The mistake the squeeze punishes hardest is solving a memory problem by buying more memory, when you could have needed less. Build-versus-rent is real and worth getting right — but it’s the second question. The first is always: how little memory can this actually take?
The take
The entire series comes down to this chapter’s quiet inversion. Every front — RAM, HBM, SSDs, workstations, the cloud, the local rig — got more expensive because the world decided it needed vastly more memory. The individual’s best response isn’t to win the bidding war for that memory; it’s to opt partway out of it by needing less. Build when ownership pays, rent when flexibility pays, and quantize always, because shrinking the requirement is the only lever that makes both cheaper at once and the only one that’s nearly free.
That’s the strategy for living inside the squeeze. The last question is when, if ever, it ends — which is where the series closes. Next: When Does Cheap Memory Come Back? The 2027–2029 Question.
Sources: O-mega.ai, Spheron, Nerd Level Tech, Vast.ai, Kriraai (TurboQuant mechanism, compression ratios, framework-availability status, Google Q2 2026 implementation timeline); LLM-Stats (Q4_K_M quality/memory tradeoff, KV-cache scaling math, MoE memory behavior, PagedAttention); the build/rent economics draw on Parts 6–8 of this series. TurboQuant figures reflect the ICLR 2026 paper (arXiv 2504.19874) and community implementations. Figures are point-in-time, late June 2026, and fast-moving. Analysis and recommendations are the author’s and not financial advice.