GPT-5.5 dropped today. I’ve been living in it since launch.
tl;dr: Incredible model. But the intelligence bump isn’t the real story.
OpenAI is chasing something new
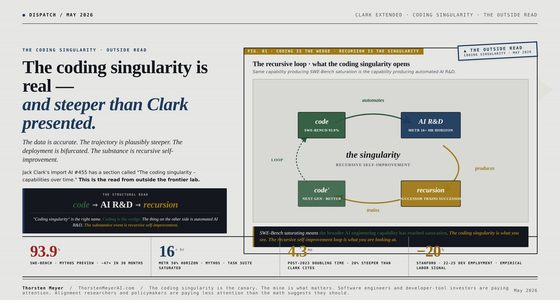
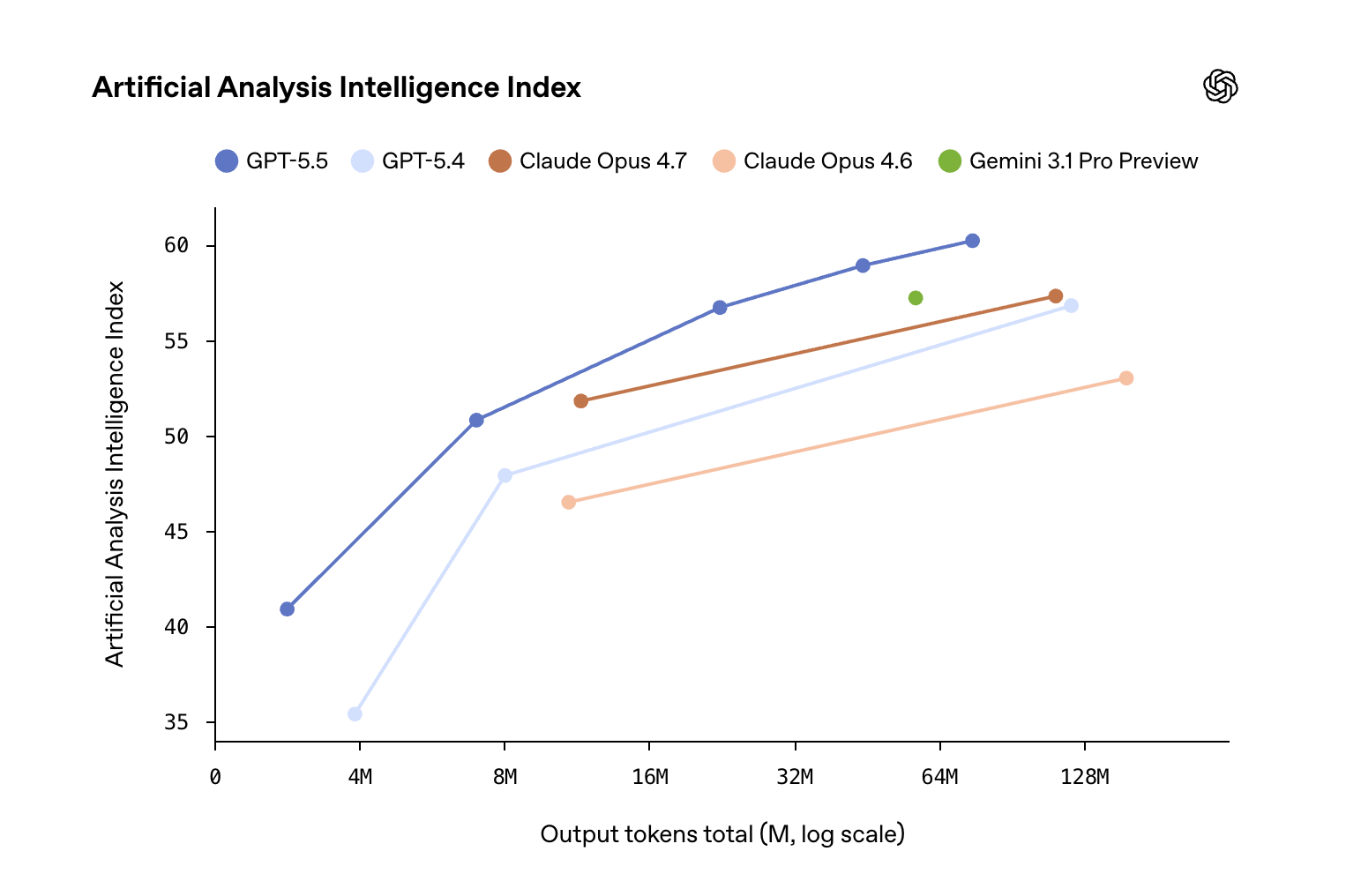
The jump from 5.4 to 5.5 isn’t a raw intelligence jump in the way you’d expect. Yes, the benchmarks moved. But OpenAI did something else this cycle that’s more strategically interesting than another few points on a leaderboard: they gave the model a personality.
Responses are shorter. More human. Less formal. Less of that courtroom-transcript tone every frontier model has been sliding toward for the last eighteen months. It has a voice.
This isn’t an aesthetic choice. This is OpenAI going directly after the personal agent market — what I’d call the OpenClaw bucket. The category of use cases where a model isn’t completing a benchmark task but living alongside you: routing your messages, drafting your replies, holding context across your day. That market rewards voice more than it rewards IQ. If your agent sounds like an enterprise help desk, nobody wants it running their life.
Here’s the contrast that matters: while Anthropic is actively trying to prevent you from using Opus tokens outside of their own harnesses, OpenAI is making their models better for exactly that use case. That’s a significant strategic divergence, and it’s showing up in the product.
If you were using OpenClaw and felt like your agent lost its soul the second it routed to GPT — try it again with 5.5. The soul is back.
GPT-5.5
is the new frontier
And it finally has a personality.
Incredible model. But the intelligence bump isn’t the real story. OpenAI did something this cycle that’s more strategically interesting than another few points on a leaderboard — they gave the thing a voice.

Plaud Note Pro AI Voice Recorder, Transcribe & Summarize with AI Note Taker for Meetings & Calls, Professionals & Teams, Supports 112 Languages, Ultra-Slim, InstantView Display, Case Included, Black
- High-Accuracy Transcription: Supports 112 languages with speaker labels
- Instant Structured Summaries: Creates mind maps, To-Do lists, proposals
- Multimodal Input Capture: Record audio, add images, type notes
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
OpenAI chose soul over IQ.
Responses are shorter. More human. Less formal. Less of that courtroom-transcript tone every frontier model has been sliding toward for eighteen months. This isn’t cosmetic — it’s a direct play for the personal-agent market, the OpenClaw bucket, where voice beats benchmarks.

AI Chatbot | Emotional Interaction, Singing and Dancing, Emojis, Companion
- Emotional AI Interaction: Responds to conversations and emotions
- Singing and Dancing: Performs music and dance routines
- Festive Gift Idea: Ideal for birthdays and holidays
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Two labs. Two philosophies.
One lab wants your agent traffic inside its own harness. The other wants to power everyone else’s agents. That’s not a minor difference — it defines who the personal-agent category defaults to next.

Amazon Echo Dot Max (newest model), Alexa speaker with room-filling sound and nearly 3x bass, Great for living rooms and medium-sized spaces, Designed for Alexa+, Graphite
- Room-Filling Sound: Adaptive, high-quality audio for any space
- Enhanced Bass: Nearly 3x bass compared to previous model
- Smart Home Hub: Built-in hub for smart device control
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
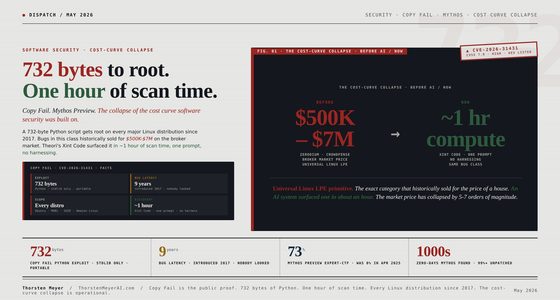
Higher price. Lower cost.
5.5 is more expensive per token than 5.4. That’s the headline — and it’s misleading. The model is dramatically more token-efficient. Reasoning converges faster, responses are leaner, tighter thinking per task. Net-net: lower total spend on real workloads.

AI Translator Language Translator Device Spanish & English Practice Companion – Supports 165 Languages,Tu compañero para practicar español e inglés,Travel Essentials traductor de idiomas portatil
- Real-Time 165-Language Translation: Instant two-way translation with 0.5s latency
- AI Language Tutor & Accent Support: Native pronunciation correction and regional accents
- Smart Vocabulary Flashcards: Automatically saves and reviews new words
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Two flavors. Both frontier.
- Hand it a spec, hit go, walk away
- Solo hours of autonomous execution
- Build → visually review → build loop feels autonomous
- Substantially better than Opus at backend & visual inspection
- 30 / 60 / 90+ minute single-task runs
- Optimized around Docs & Word plugins
- Ships coherent 60-page structured documents
- Feels like it can solve anything you give it
GPT-5.5 vs Opus.
Where each model still owns its territory, based on live workload testing across two weeks.
GPT-5.5 is the
new bar.
On intelligence, agentic execution, and personal-agent fit, this is now the frontier. Anyone building in the agent layer should rerun their routing decisions this week.
The token economics are better than the sticker price suggests
GPT-5.5 is more expensive per token than 5.4. That’s the headline and it’s true.
It’s also misleading.
5.5 is dramatically more token-efficient. To reach 5.4-level output quality, it burns far fewer tokens. The thinking is tighter, the responses are leaner (partly because of the personality work), and reasoning converges faster. Net-net, 5.5 should cost less to run overall for most real workloads.
This is a bigger deal than most people are pricing in. Everyone stares at the per-token number and assumes linear cost scaling. The actual economics of deploying a model for agentic workflows are governed by total tokens burned per completed task — and on that axis, 5.5 is a meaningful win.
But is it actually good?
Yes. It’s incredible. And it comes in two flavors: Codex and Pro.
Codex: the frontier of agentic coding
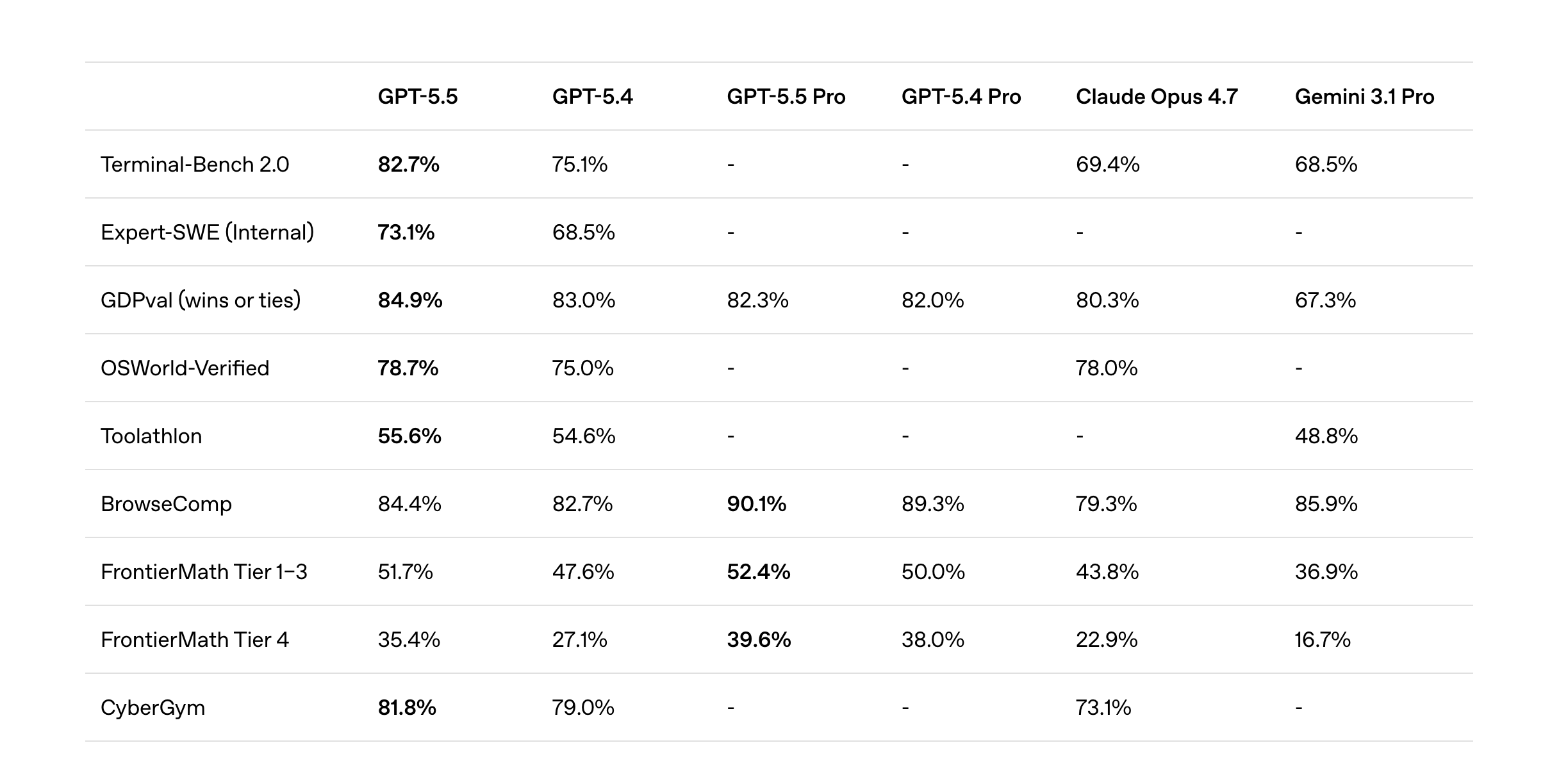
This is where 5.5 is genuinely in a league of its own. I gave it a PRD for a new project, hit go, and let it run. Hours later it had built the thing. End-to-end. No babysitting.
It finds and fixes hard bugs. It navigates large codebases without losing the plot. It’s better than Opus at backend work — and it’s substantially better at visual inspection. The build → visually review → build more loop feels genuinely autonomous in a way no other model has nailed. Opus is close, but 5.5 Codex iterates on visual output with far less hand-holding.
The exception is frontend design. Opus still wins there. If you’re shipping design-forward interfaces, 5.5 won’t replace your Opus run. But for architectural work, backend, debugging, and full-stack build-outs of complex systems, it’s the new ceiling.
I defaulted to medium and high thinking settings. Extra-high was just too slow, and the marginal quality bump wasn’t worth the wait. Most tasks didn’t need it anyway.
Pro: the problem-solving beast
Using 5.5 Pro in ChatGPT is a different experience. It just feels like it can solve anything. I’ve honestly struggled to hand it problems hard enough to stump it. And it’ll happily grind on a single task for 30, 60, 90 minutes — sometimes more.
It’s also clearly been optimized around OpenAI’s plugin ecosystem — Google Docs, Microsoft Word, the rest. Ask it for a 60-page coherent, well-designed document and it produces one. Not a wall of text pretending to be a document. An actual structured deliverable you can ship.
The one real caveat: speed
Opus — especially 4.6 fast — is still significantly faster than any GPT model I’ve used. Not a little faster. Noticeably faster.
I’m a speed-maxxer. For me this matters. There are workflows where Opus’s wall-clock advantage wins even when 5.5 would produce a marginally better output, because iteration velocity compounds. If you’re doing a lot of tight interactive loops, Opus is still the better tool.
But if you’re handing off autonomous work and coming back later? The speed gap closes to irrelevance.
GPT-5.5 is the new bar
This is the frontier now. On intelligence, on agentic execution, on personal-agent fit, 5.5 is as good as any Opus model and often better at specific tasks. The only axes where Opus clearly wins are speed and frontend design.
More importantly, the release tells you something about OpenAI’s posture. They’re no longer just optimizing for raw intelligence deltas. They’re building a model that wants to live outside of their own interface — designed to be routed to, embedded, composed with. A model with enough personality to actually function as someone’s agent.
That’s the move. And for anyone building in the agent layer — OpenClaw, and everything adjacent — it changes the stack.