The Control Series, Part 3 of 6 · Chokepoint: Data. Part 2 ended on a line: compute taught the industry to rent the machine, and the next fight is over the one thing you can’t rent, because no one else has it. This is that fight.
The pitch was always that AI would learn from the sum of human knowledge. The uncomfortable update, in 2026, is that the industry has finished the free part — and the part that’s left is being fenced, priced, sued over, and, in a few cases, treated as a national asset.
This is the chokepoint that behaves differently from the others. You can rent compute. You can lease power. You cannot rent data that no one else has. And as models and chips slide toward commoditization — H100 rental rates are down 60–75% from peak, as Part 2 noted — the thing that stays scarce, the thing that actually separates one lab’s model from another’s, is increasingly the corpus underneath it.
So the fight has moved. Not to bigger crawls of the open web, but to the small, hard, expensive places where the remaining valuable data lives: behind paywalls, inside enterprises, in the heads of experts, on the battlefield. Here is how data became the chokepoint, who’s fencing it, and why “own your data” stopped being a slogan and became a survival strategy.
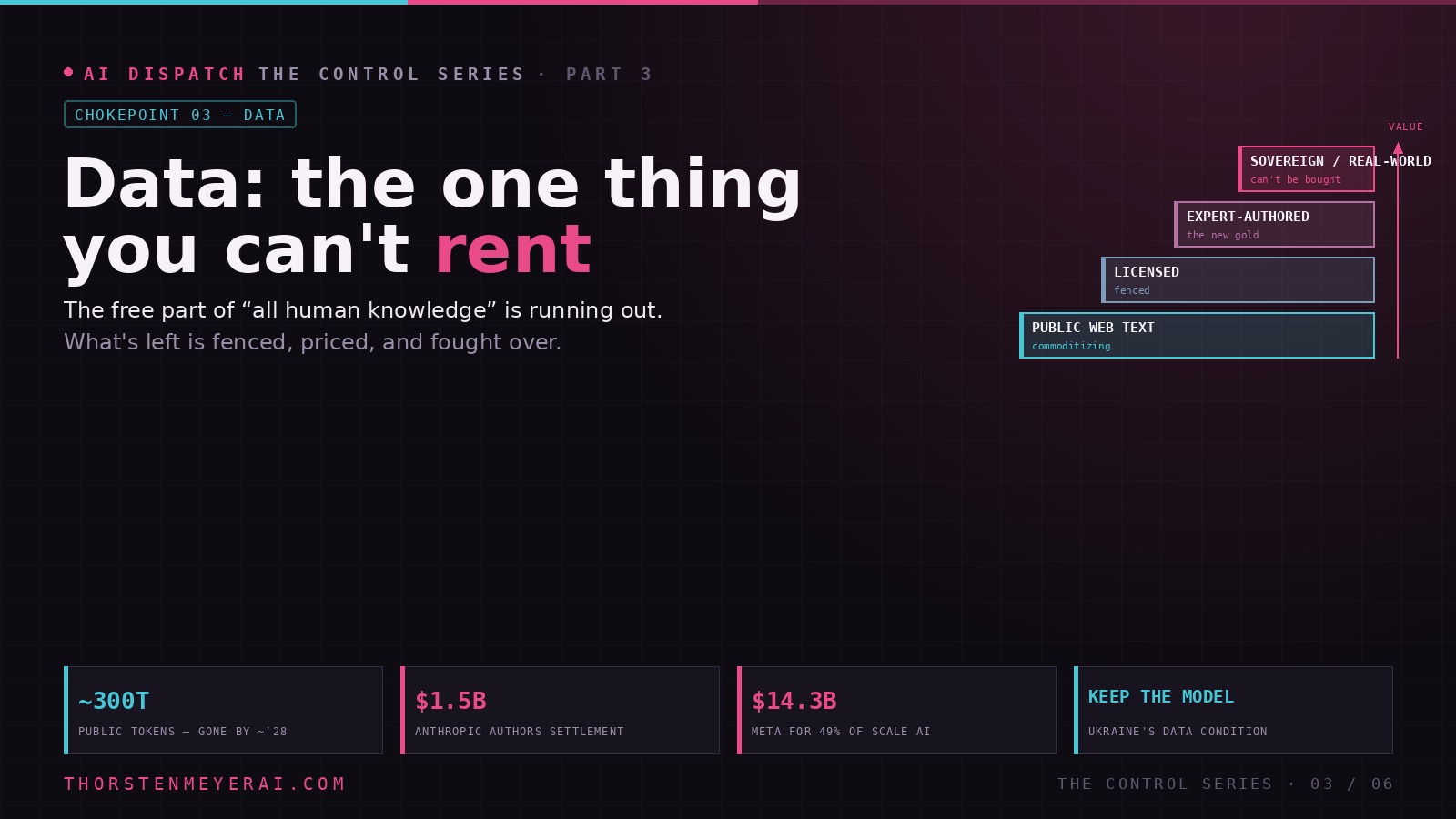
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
The well is running dry
Start with the scarcity that reframed everything. Epoch AI estimates the public internet holds roughly 300 trillion tokens of high-quality text — and frontier models are already training on datasets approaching that ceiling. Their projection: the stock of public human text gets fully used somewhere between 2026 and 2032, with a median around 2028, and “overtraining” for efficiency can pull that forward. Elon Musk put it more bluntly in early 2025, declaring the cumulative sum of human knowledge essentially exhausted for training.
The standard responses are real but partial. Synthetic data is now a default ingredient — Nvidia paid $320 million for the synthetic-data firm Gretel; Microsoft trained a model on hundreds of billions of synthetic tokens — and better algorithms squeeze more from less. But synthetic data carries a documented hazard: in domains where answers are hard to verify, training on machine-generated text risks model collapse, errors compounding across generations. Which means the cure for the data shortage quietly increases the value of the one antidote to collapse: fresh, verified, human-made data.
The generic stuff is running out. The scarce stuff just became the whole game.

Western Digital Internal Hard Drives 18Tb DC HC550 Surveillance,Wd 3.5 HDD Sata 6Gb/s 7200 PRM NAS 512 mb Cache for Dvr Nvr
Outstanding Performance: The hard drive features a 7200 RPM speed and a 512MB cache, delivering excellent read/write speeds…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
So they fenced what’s left
For years the model was simple: scrape the web for free and sort out the lawyers later. 2026 closed that door.
The landmark is Anthropic’s $1.5 billion settlement with authors — the largest copyright recovery in the history of U.S. copyright law. The judge had drawn a sharp line: training on legally acquired books was “quintessentially transformative” fair use, but downloading millions of pirated books from shadow libraries was not. Anthropic settled the piracy claims at roughly $3,000 per work across some 500,000 titles, agreed to destroy the pirated files, and bought its way out of a trial that could have produced tens of billions in statutory damages. Notably, the settlement covers only past piracy — not future training, not model outputs.
The precedent matters less for the dollar figure than for what it ratifies: the era of free scraping is over, and a market-based licensing regime for training data is forming in its place. The New York Times’ case against OpenAI grinds on in discovery; News Corp and other publishers have moved from suing to licensing. Data that used to be a free input is now a priced one — and, as more than one analyst noted, a $1.5 billion price of entry is a moat that favors the deep-pocketed incumbents who can pay it, and a wall in front of the startups who can’t. Fencing the data doesn’t just protect creators. It concentrates the industry.

Apricorn 1TB Aegis Padlock USB 3.0 256-bit AES XTS Hardware Encrypted Portable External Hard Drive (A25-3PL256-1000)
Utilizes Military Grade FIPS PUB 197 Validated Encryption Algorithm
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The new gold is expertise
Here’s the shift inside the shift. When AI was learning to tell cats from dogs, the data that mattered was cheap — armies of contractors in low-income countries paid pennies a task. The move to reinforcement learning and “reasoning” models changed the requirement entirely. Now labs need experts — lawyers, physicists, surgeons, competition mathematicians — to define what a good answer looks like in their domain. The data isn’t labeled anymore; it’s authored, by people who are expensive precisely because they’re rare.
That turned a sleepy labeling sector into a battleground. In June 2025 Meta paid $14.3 billion for 49% of Scale AI and installed its founder atop Meta Superintelligence Labs. The reaction was instant and revealing: OpenAI, Google, and xAI backed away from Scale almost overnight — not over price, but over neutrality. No lab wants to feed its hardest training problems through a vendor half-owned by a competitor who could see what it’s working on. Data access had become a way to spy on a rival’s roadmap.
The exodus minted new powers. Mercor’s valuation jumped to $10 billion in eight months; Surge, reportedly raising near $15 billion, boasts Fields medalists and Supreme Court litigators on its expert rosters. One rival CEO compared the disruption to an oil pipeline exploding between Russia and Europe. And the cautionary tale sits right there in the same industry: Appen, once worth $4.3 billion with 80% of revenue from five tech giants, is now worth under $130 million — a reminder that a data supplier dependent on a few buyers is itself standing on a chokepoint.

Synology DS423 Family & Business Backup – Secure File Sharing, Photo Vault & Video Surveillance (4-Bay Diskless NAS)
Secure private cloud – Safely access and share files and media from anywhere, and keep friends, partners, or…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
And the rarest data is real
The most valuable corpus of all can’t be bought from a broker at any price, because it’s generated by doing something no one else does.
Part 1 of this series opened with Ukraine’s Avengers Labs: millions of annotated frames from real combat drone missions, offered to companies to train on only on the condition that Ukraine keeps the resulting model. That’s the template for data as a sovereign asset — licensed, never surrendered, with the strings pulled by whoever owns the irreplaceable source. The same logic governs the real-world data flywheels inside self-driving fleets, humanoid-robot training runs, and defense ISR systems: proprietary, adversarial, continuously refreshed, and impossible for a competitor to replicate without running the same operation in the same physical world.
Generic text is a commodity. A war’s worth of thermal footage, a fleet’s worth of driving edge cases, an enterprise’s decade of transactions — those are sovereign. And their owners are beginning to act like it.

Building Products for the Enterprise: Product Management in Enterprise Software
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Who holds the lever
Pull the threads together and the control concentrates in three places.
The owners of unique corpora — publishers, platforms, governments, and any enterprise sitting on proprietary, hard-to-collect data. They’ve discovered they own an input the labs now have to pay for, and they’re setting terms.
The expert-data brokers, and the labs racing to lock them up. Whoever controls the supply of expert-authored training data controls a gate to frontier progress — which is exactly why Meta tried to buy that gate, and why everyone else fled to keep it neutral.
The courts and the licensing market, which are quietly setting the price of data — and a high price is itself a barrier that favors incumbents.
In each case, access to data is now gated (licensing, exclusivity, paywalls), repriceable (the settlement put a number on it), and revocable (terms of service, robots.txt, sovereign conditions). That is the precise signature of a chokepoint — the same gated-repriceable-revocable pattern this series found at the power, compute, and model layers.
My take
The deep irony deserves to be said plainly: the technology sold as a way to learn from all of human knowledge has exhausted the freely available portion and must now buy, broker, or seize the rest — and the rest is concentrated in a small number of hands. Data was supposed to be the abundant input. It turned out to be the scarce one.
For anyone building on top of AI — which is most companies and most countries — this is the most actionable chokepoint in the series, because it’s the one you can actually own. Your proprietary data is your single most defensible asset: the one input no model provider can reprice or reclaim out from under you. The corollary is the Scale–Meta lesson, learned the hard way by everyone who fled: do not hand your most valuable data to a provider who can become your competitor. And for institutions and nations thinking about sovereignty, Ukraine wrote the playbook — license your unique data conditionally, keep the model, keep the leverage.
I’ll be fair to the optimistic case. The data wall is not a cliff; Epoch already pushed its estimate from 2026 toward 2028, and synthetic data, multimodal sources, and more efficient training keep moving it. A licensing market is arguably fairer to creators than a decade of uncompensated scraping was. None of this is purely a doom story. But the direction is unmistakable: the input everyone assumed was free and infinite is becoming owned and finite, and ownership confers control.
The watch items for the rest of 2026 are concrete: whether the New York Times case produces an output-based precedent that the Anthropic settlement explicitly left open; whether exclusivity deals fragment the expert-data supply into competing camps; whether the Ukraine model of conditional, sovereign data licensing spreads to other nations and institutions; and whether synthetic-data quality holds well enough to keep the wall at bay — or whether model collapse sends everyone scrambling back to the humans.
Next in the series
Three chokepoints down, and a pattern is hardening: every layer of AI is becoming something a few owners can gate, price, and switch off. Part 4 takes the most dramatic switch of all — model access, and the June precedent in which the U.S. government turned off a frontier model worldwide on ninety minutes’ notice. Power, compute, and data are levers you squeeze slowly. Access is the one you can pull all at once.
Sources: Epoch AI; PBS; The Conversation; the International AI Safety Report 2026; NPR; the Authors Guild; Wolters Kluwer; TechCrunch; TIME; CNBC; Forbes; and Ukraine’s Ministry of Defense (2024–June 2026). Token and exhaustion estimates are projections; data-market valuations are as reported. Analysis and opinions are the author’s.