
Generative‑AI systems expose attack surfaces that ordinary web and API security controls were never meant to see: natural‑language prompts, token streams, retrieval‑augmented documents, and model outputs that may themselves be executable, confidential, or toxic. “Firewall for AI” (F4AI) is emerging as the architectural pattern that inserts a purpose‑built, low‑latency security broker between every caller and every large‑language‑model (LLM). Below is a consolidated research digest on how F4AI products and open‑source frameworks are closing those gaps today, with a focus on real‑time detection, real‑time protection, and policy‑based enforcement.
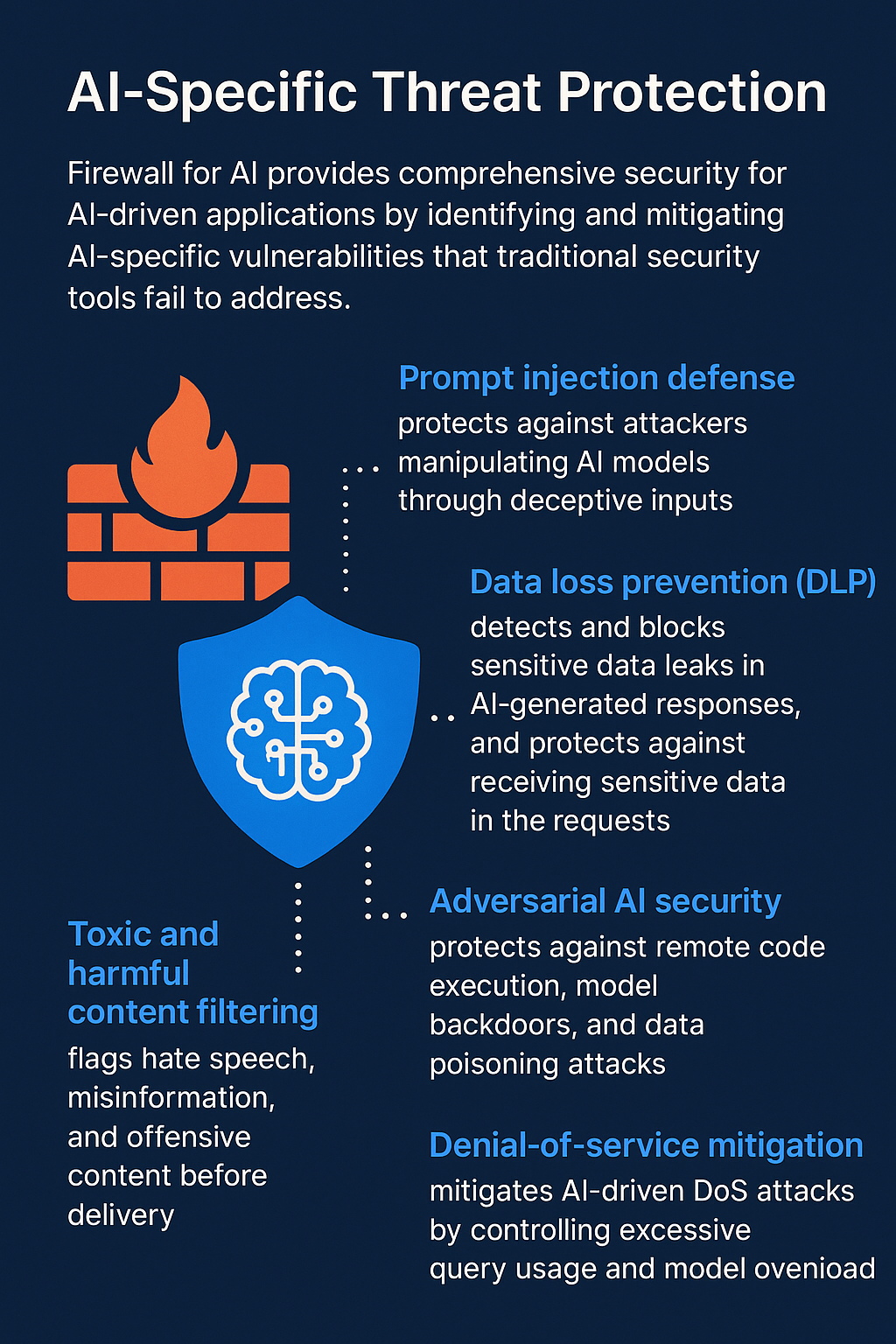
Why an AI‑aware firewall is needed
| Classical gap | How LLMs magnify it | OWASP LLM Top‑10 mapping |
| Input injection | Prompts are arbitrary natural language; attackers can smuggle instructions or code that bypass system rules | LLM01 Prompt Injection, LLM07 Insecure Plugin Design |
| Output tampering/leakage | Model may reveal training secrets, customer data, or copyrighted text | LLM06 Sensitive Information Disclosure, LLM03 Training‑Data Poisoning |
| Volumetric abuse | Each request is GPU‑intensive; a few dozen aggressive clients can create a denial‑of‑service or blow through budgets | LLM04 Model DoS |
Cloudflare formalised the pattern in March 2024: Firewall for AI is an inline proxy that scans every prompt and completion, rates injection likelihood, tags topics, blocks or rewrites traffic, and couples those controls with classic WAF features such as rate limiting and sensitive‑data detection .

LLM Firewalls: Securing AI Systems in the Age of Generative Intelligence: Prompt Injection, RAG Security, Agent Governance, and Enterprise AI Defense
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Core capability stack
| Layer | Real‑time detection technique | Real‑time protection / enforcement examples |
| Prompt‑side inspection | • Signature & ML classifiers (Cloudflare scoring 1‑99; Microsoft Prompt Shields) • Semantic diff against system prompt • Encoding / role‑play heuristics | Block, redact, or transform prompt; apply spot‑lighting to down‑rank untrusted document chunks (Azure) |
| Completion‑side inspection | • PII/secret regex + ML DLP (Cloudflare SDD, Palo Alto AI Access Security) • Content‑harm classifiers (violence, hate, sexual, self‑harm). Azure does this token‑by‑token in streaming mode to keep latency ≤ tₗ ms | Mask/redact sensitive strings; reject or re‑generate toxic output; watermark or hash approved content for provenance logs |
| Adversarial & supply‑chain security | • Runtime syscall monitoring for RCE in agent plug‑ins • Model‑lineage scanning (Prisma AIRS) • Open‑source guard models (Meta Llama Guard 2/3) classify unsafe input/output streams at ~4 ms per 1 k‑tokens | Kill request; quarantine plug‑in; trigger model‑roll‑back |
| Denial‑of‑Service mitigation | Anomaly tracking (queries/min, tokens/output‑sec) + GPU‑utilisation telemetry; Cloudflare combines bot‑score and prompt‑score to throttle or drop bursts | Progressive rate limiting, budget‑based cut‑off, or queueing |
| Policy engine | Declarative rules: if prompt.score > 80 OR contains “nuclear recipe” → block; if response.PII detected → mask + log | Multi‑tenant RBAC, context‑window quotas, per‑department DLP profiles |

The Developer's Playbook for Large Language Model Security: Building Secure AI Applications
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Alignment with standards and frameworks
- NIST AI RMF Generative‑AI Profile calls for “real‑time monitoring, alerting, and dynamic risk assessments” (MEASURE 2.6, MANAGE 2.2‑2.3) and recommends live auditing tools for lineage and authenticity .
- MITRE ATLAS maps concrete attacker TTPs (e.g., Training‑Data Poisoning, Model Evasion) that F4AI sensors can emit to your SIEM for correlation .
- OWASP GenAI Security Project enumerates the same ten risks F4AI aims to block at the edge, letting teams show measurable coverage during audits .

McAfee Total Protection 5-Device | AntiVirus Software 2026 for Windows PC & Mac, AI Scam Detection, VPN, Password Manager, Identity Monitoring | 1-Year Subscription with Auto-Renewal | Download
DEVICE SECURITY – Award-winning McAfee antivirus, real-time threat protection, protects your data, phones, laptops, and tablets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Representative vendor & open‑source landscape (mid‑2025)
| Segment | Products / projects | Notable differentiator |
| CDN / edge | Cloudflare Firewall for AI | Inline prompt‑scoring + existing WAF rules |
| Secure Access Service Edge (SASE) | Palo Alto AI Access Security & Prisma AIRS | Combines DLP, CASB, and model‑posture scans |
| NGFW / SWG | Check Point GenAI Security Gateway—new IPS sigs for prompt‑injection CVE CPAI‑2024‑1130 | |
| Cloud‑provider native | Microsoft Prompt Shields, Azure configurable content filters (streaming) ; AWS Bedrock Guardrails & GuardDuty for AI (session anomaly alerts) | |
| Open source guardrails | Meta Llama Guard 2/3, Nvidia NeMo Guardrails, IBM watsonx tutorials |
AI content filtering and redaction tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Reference architecture blueprint
[Client] ──► ① API Gateway (authN, coarse RBAC)
└─► ② Firewall for AI (this layer)
• Prompt inspector
• Output inspector
• Policy & decision engine
• Rate‑limit / circuit breaker
• Audit & telemetry export
└─► ③ Orchestration / RAG layer
└─► ④ Model endpoint(s)
- Deployment: ② can be a side‑car (for private VPC models) or an edge service (for SaaS LLMs).
- Latency budget: Vendors target < 10 ms p95 added latency for ≤ 4 k‑token prompts by streaming inspection and early verdicts.
- Fail‑safe: If ② is unreachable, the gateway can default‑deny or pass‑through, depending on business criticality.
Implementation checklist
| Phase | Actions |
| Assess | 1. Inventory every LLM endpoint, context doc store, and plug‑in. 2. Map threats using OWASP LLM‑Top‑10 and MITRE ATLAS. |
| Deploy controls | 1. Insert F4AI inline; enable prompt & completion inspection in monitor mode for two weeks. 2. Turn on rate limiting and token‑budget alerts. |
| Tune policies | 1. Tri‑age logs; raise/relax thresholds to balance false positives. 2. Add regex/ML patterns for org‑specific secrets. |
| Automate response | 1. Forward high‑severity events to SIEM/SOAR. 2. Auto‑quarantine user/session after ≥ N violations within T minutes. |
| Continuous monitoring | 1. Track drift in guard‑model precision/recall; retrain monthly. 2. Review NIST AI RMF risk metrics (real‑time monitoring, response time). |
Open research fronts (2025‑2026)
- Token‑level watermarking & reversible redaction to allow safe release of partially sensitive outputs.
- Adaptive guard models that learn from each customer’s own domain and threat intel feeds to reduce false positives.
- Formal policy languages (e.g., Rego extensions for LLM context) that can express semantic constraints.
- Hardware‑rooted metering (e.g., Nvidia NGX) to enforce tenant‑level GPU quotas against model DoS.
Key take‑aways
- Inline, low‑latency inspection of both prompts and completions is now table‑stakes; relying solely on model‑side safety is porous.
- Real‑time policy orchestration—block, mask, transform, throttle—bridges the gap between detection and actionable protection.
- Standards alignment (NIST AI RMF, MITRE ATLAS, OWASP GenAI) provides the vocabulary to prove that your F4AI posture actually mitigates the new AI‑specific risks.
- Vendor landscape is maturing fast—edge CDNs, NGFWs, cloud platforms, and open source tools are converging on similar control primitives. Choose based on latency budget, deployment model, and integration with your existing WAF/SIEM/DLP stack.
By embedding a purpose‑built Firewall for AI at every model boundary and continuously tuning it with real‑time telemetry, organisations can close the distinctive security gaps—prompt injection, data leakage, toxic output, adversarial manipulation, and DoS—that generative AI introduces.







