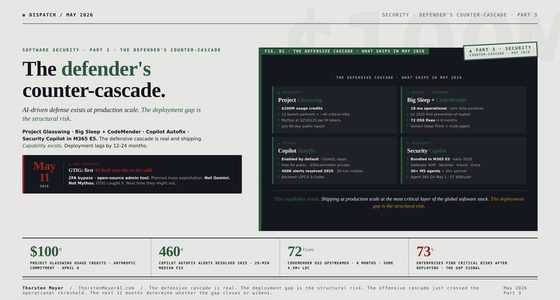
Apple researchers unveiled a retrofit that lets standard autoregressive LLMs predict several future tokens at once—and then verify them—cutting latency without hurting quality. In “Your LLM Knows the Future,” they add learned mask tokens, a small gated‑LoRA adapter, and a lightweight sampler; proposed tokens are verified via linear or “quadratic” decoding. The team frames the approach as a minimal supervised fine‑tune that preserves next‑token performance. On Tulu3‑8B fine‑tuned to predict eight future tokens, Apple reports ~2.5× faster chat/knowledge and up to ~5× on code/math with no quality loss.
TL;DR
Apple researchers published a new paper showing how to make standard autoregressive LLMs predict several future tokens at once with minimal retraining. Using special mask tokens, a tiny gated LoRA adapter, a lightweight sampler head, and a verification step they call linear/quadratic decoding, they report ~2.5× speedups on general chat/QA and up to ~5× on coding & math with no quality loss in their tests on Tulu3‑8B.
Why it matters: Lower latency and compute per user—especially in predictable domains—without a second draft model or major architecture changes; viable for on‑device or server inference.
How it compares: Speculative decoding uses a smaller helper model; Apple’s approach keeps a single model proposing and verifying its own futures, aiming for “lossless” quality. Coverage pegs gains at 2–3× on average, up to 5× for code/math.
Bottom line: A light, practical recipe to accelerate existing LLMs with minimal retraining. It’s research, not a shipping feature, but likely to influence Apple Intelligence and open‑model ecosystems—and broader developer tooling adoption soon.

havit HV-F2056 15.6"-17" Laptop Cooler Cooling Pad – Slim Portable USB Powered (3 Fans), Black/Blue
Ultra-Portable: Slim, portable, and light weight allowing you to protect your investment wherever you go
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.

CAN CEREBRAS DETHRONE NVIDIA’S REIGN? The AI Hardware Showdown: A Story of Innovation, Competition, and the Fight for the Next Big Leap in Artificial Intelligence (AI AND TECH UPDATES)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
on-device AI acceleration tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.

ARCHITECTING RELIABLE INDUSTRIAL AI: EDGE DEPLOYMENT, MULTIMODAL AGENT, AND VERIFICATION: Building Safe, Low-Latency LLM and Vision Systems for Manufacturing, Infrastructure, and Mission-Critical
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.