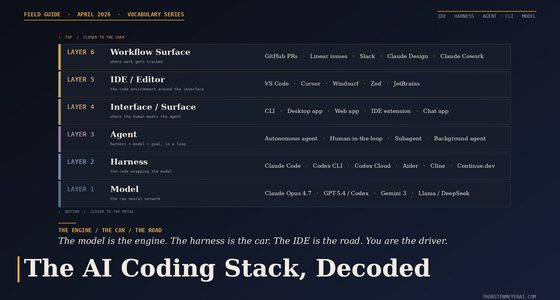
Google assembles a strike team to catch Anthropic on coding. The NSA runs Anthropic’s most dangerous model behind the Pentagon’s back. OpenAI’s “Spud” is reportedly already A/B testing inside ChatGPT. The frontier is no longer a benchmark — it’s a fight on three fronts, and each lab is winning a different one.
By Thorsten Meyer — April 22, 2026
For most of the last eighteen months, I have been writing about the AI race the way everyone else has: as a leaderboard. Opus clears SWE-bench Pro at 64. GPT-5.4 Pro hits 83 on ARC-AGI-2. Gemini 3.1 has a million-token context window. Numbers in, opinions out. It has been a comfortable way to cover a technology because numbers feel concrete even when they are not, and because a leaderboard lets you pretend the thing being measured is a horse race rather than a restructuring of the global software industry, the defense establishment, and the labor market all at once.
This week broke that frame. Three stories landed between April 19 and April 21 that, read together, force a different conclusion. The AI race is no longer a single-axis competition, and no single lab is winning it. There are at least three distinct fronts being fought simultaneously — coding workflow dominance, national-security access, and frontier capability — and each of the three frontier labs is currently winning a different one. If you are an operator trying to make infrastructure decisions for the next twelve months, that is the picture you need to hold in your head. Not a leaderboard. A front map.
Three
Fronts.
One week. Three frontier labs. Three different races — and no single winner. A reading of the 19–21 April cycle: Google’s strike team, the NSA’s backdoor, and a root vegetable at Stargate.
Front
DeepMind assembles a strike team to close the agentic-coding gap.
Per The Information (Erin Woo, 20.04), a task force led by pretraining veteran Sebastian Borgeaud is now working directly under Sergey Brin and CTO Koray Kavukcuoglu. Brin’s internal memo reportedly ordered an aggressive pivot to agents and framed the endgame as AI takeoff. Management now tracks engineer usage of Jetski, Google’s internal agentic IDE, on an internal leaderboard.
- LeaderSebastian Borgeaud — former Gemini pretraining lead, RETRO & Chinchilla co-author
- Corpus~2 billion lines of proprietary code — the world’s largest internal codebase
- AdmissionAlphabet CFO in Feb: ~50% of Google code now AI-written. Anthropic: pretty much all of it.
- SentimentInternal perception, per sources: Gemini is losing the coding workflow war to Claude Code.
Front

AI-Assisted Coding: A Practical Guide to Boosting Software Development with ChatGPT, GitHub Copilot, Ollama, Aider, and Beyond (Rheinwerk Computing)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The NSA is running Mythos — behind the Pentagon’s explicit blacklist.
Per Axios (19.04), two sources confirm NSA deployment of Claude Mythos Preview; a third says the model is used “more widely” inside DoD. This sits directly against Defense Secretary Hegseth’s February supply-chain-risk designation — blocked indefinitely on 26.03 by Judge Rita Lin as retaliation against protected speech. Two days before the scoop, Dario Amodei met Chief of Staff Wiles and Treasury Secretary Bessent at the White House.
- CapabilityFirst model to complete a full-network-takeover sim (UK AISI). Surfaced thousands of high-severity zero-days.
- Commitment$100M in model credits + $4M to open-source security via Project Glasswing.
- QuoteAdmin source to Axios: every federal agency except DoD wants access to Anthropic’s tools.
- CaveatVidoc Security reportedly reproduced key findings with public GPT-5.4 and Opus 4.6.
Front

Mastering Enterprise Platform Engineering: A practical guide to platform engineering and generative AI for high-performance software delivery
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
OpenAI’s “Spud” — a new base, reportedly days away.
Pretraining finished at Abilene Stargate on 24.03 per The Information. Greg Brockman on the Big Technology podcast: a new base, two years of research coming to fruition, “big model smell.” A leaked Q2 memo from CRO Denise Dresser (The Verge, 13.04) calls Spud an important step for the next generation of work. The A/B-inside-ChatGPT claim, however, traces to a thin source cluster and is not yet corroborated by TestingCatalog.
- CodenameSpud — consistent with OpenAI’s food lineage: Strawberry (o1), Orion (GPT-5), Chestnut (Image 1.5).
- MarketPolymarket: release by 30.04 priced near 92%. April 23 near 76–82%.
- CadencePretraining finished 19 days after GPT-5.4 shipped — parallel training runs.
- AsteriskJimmy Apples silent. TestingCatalog silent. Hold the date loosely.
No single lab is winning the race because the race is not one race.
Anthropic is ahead on workflow and winning the political navigation. OpenAI is positioned to swing the next capability pop. Google has the base-model depth, the biggest training corpus, and a founder personally force-marching the org — and still, this week, the gap is wide enough to require a named strike team.
Let me walk through each front, what actually happened this week, and what I think it means.

Lark-2: Language Activity Resource Kit – Second Edition – Speech & Language Therapy Resource
- Comprehensive Therapy Resources: Includes objects, photos, illustrations, print materials
- Versatile Language Support: For naming, categorization, sequencing, comprehension, speech tasks
- Clinical Applications: Suitable for aphasia, brain trauma, neurological conditions
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Front one: coding, where Google is losing and knows it
On Monday, The Information‘s Erin Woo reported that Google DeepMind has assembled what her sources called a “strike team” to improve Gemini’s coding models. The team is led by Sebastian Borgeaud — who previously ran Gemini pretraining and co-authored RETRO and Chinchilla — and it is being directly overseen by Sergey Brin and DeepMind CTO Koray Kavukcuoglu. The precipitating event, per three sources, was the release of Claude Opus 4.7 and an internal perception that Anthropic has decisively pulled ahead on agentic coding.
Two details from the reporting stand out. The first is a Brin memo to DeepMind staff telling the team it must “urgently bridge the gap in agentic execution and turn our models into primary developers [of code]” and that Gemini must “aggressively pivot” to agents. He reportedly framed the end goal as “AI takeoff” — a model good enough at coding that it can eventually improve itself. The second is that Google maintains an internal leaderboard tracking which engineers are using “Jetski,” its internal agentic coding IDE. Management is literally tracking usage.
Before anyone cries panic: Google is not losing at everything. Gemini 3 Pro is extremely good. Max Weinbach’s X posts have argued persuasively that the Gemini base models are possibly the strongest in the industry — the problem is post-training behavior and agentic reliability. You can see that on the public benchmarks too. On SWE-bench Verified, Opus 4.7 clocks around 87.6%, GPT-5.3-Codex sits near 85%, and Gemini 3.1 Pro trails at roughly 80.6%. On SWE-bench Pro the spread widens — Opus at 64, GPT-5.4 at 57.7, Gemini at 54.2. Gemini is in the race. But the race that matters in 2026 is not which base model is smartest. It is which tool a senior engineer reaches for when they have three hours to merge a feature branch.
That is a workflow war, and Anthropic is winning it. Boris Cherny, who runs Claude Code, said in January that “pretty much 100%” of Anthropic’s own code is now written using AI. On Alphabet’s February earnings call, CFO Anat Ashkenazi volunteered that roughly 50% of code at Google is written by coding agents. Six months ago that number would have been the headline. Placed next to Anthropic’s, it reads as an admission.
The part of the story that I find most revealing is the training direction. Woo reports that Google is putting more emphasis on models trained on its internal codebase — over two billion lines of code, by engineer accounts on X. Those models cannot be shipped to the public. They exist as stepping stones toward better public models and, ultimately, toward self-improving AI research. That is the real goal. Coding is not an end in itself. It is the substrate on which the next generation of research gets done, which is why Brin is “literally coding” with the Gemini team, per Sundar Pichai, and why Brin once had “a big tiff inside the company” after discovering Gemini was on an internal not-allowed-to-use list.
I will phrase my takeaway on this front carefully: Google has the base-model edge, the largest proprietary training corpus in the world, and a founder personally force-marching the org toward agentic coding. And they are still, right now, losing the only coding metric that determines enterprise spend: which tool developers actually open.

MINISFORUM MS-S1 MAX Mini AI Workstation PC, AMD Ryzen AI Max+ 395 (16C/32T),RDNA3.5 GPU,64GB LPDDR5 2TB SSD Mini PC,Dual M.2 PCIe 4.0, PCIe x16 Slot, USB4 V2(80Gbps)& Dual 10GbE, 320W PSU,Wi-Fi 7
- High-Performance AMD Ryzen AI Max+ 395: 16-core, 32-thread CPU with RDNA 3.5 GPU
- Powerful AI Capabilities: 126 TOPS system output with NPU for AI tasks
- Large Unified Memory: 64GB LPDDR5x-8000MT/s for smooth multitasking
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Front two: national security, where Anthropic is winning the most politically combustible fight in tech
On Saturday, Axios reported that the National Security Agency is using Claude Mythos Preview — Anthropic’s most powerful model to date, released April 7 under Project Glasswing — despite the Department of Defense designating Anthropic a “supply chain risk” on February 27. Since the NSA sits under DoD authority, this is not a small contradiction. It is a direct one.
The backstory is worth remembering because it is the single most dramatic industry-government confrontation of this cycle. In July 2025, Anthropic won a $200M CDAO contract and Claude became the first frontier model cleared for classified networks. In early 2026, during contract renegotiation, the DoD demanded Claude be available “for all lawful purposes.” Anthropic refused, insisting on walling off mass domestic surveillance and autonomous weapons development. On February 27, Defense Secretary Pete Hegseth issued the supply-chain-risk designation with the on-record line that “America’s warfighters will never be held hostage by the ideological whims of Big Tech.” On March 26, Judge Rita Lin in the Northern District of California blocked the designation indefinitely, writing — in what I will nominate as the legal sentence of the year — that “nothing in the governing statute supports the Orwellian notion that an American company may be branded a potential adversary and saboteur of the U.S. for expressing disagreement with the government.”
And now we learn that, while all of that was happening publicly, the NSA was using Mythos.
The tool itself is not a normal frontier model. Mythos has discovered thousands of high-severity zero-days across every major OS and every major browser in red-team testing. The UK’s AI Security Institute reported it was the first model to complete a simulated full-network-takeover. Anthropic has committed $100M in model credits and $4M in direct donations to Project Glasswing’s defensive ecosystem. Over 99% of the vulnerabilities Mythos has surfaced remain unpatched — Anthropic is withholding them under coordinated disclosure. Most of the twelve public launch partners (AWS, Apple, Cisco, CrowdStrike, Google, JPMorgan, Microsoft, Nvidia, Palo Alto Networks, Broadcom, the Linux Foundation) are using it defensively. Axios notes pointedly that the NSA’s use case “is not purely defensive.”
Two days before the scoop broke, Dario Amodei walked into the White House to meet Chief of Staff Susie Wiles and Treasury Secretary Scott Bessent. Both sides called it productive. Per Axios, the next steps will focus on how departments other than the Pentagon engage with the model. An administration source told Axios: “Every federal agency except the Department of Defense wants access to Anthropic’s tools.” Separately, Bessent and Fed Chair Jerome Powell are reportedly encouraging major bank CEOs to test Mythos directly.
I want to be honest about the contrarian read on this, because I think Bruce Schneier has a point. His blog called Project Glasswing “a PR play by Anthropic — and it worked,” and noted that the initiative is ultimately reactive. Researchers at Vidoc Security reportedly reproduced several of Mythos’s alarming findings using publicly available GPT-5.4 and Claude Opus 4.6 — which suggests the capability uniqueness narrative is overstated. Jack Clark himself has said as much: “This is not a special model. There will be other systems just like this in a few months from other companies.”
But the political story is separate from the capability story, and on the political story Anthropic is running the table. They held their red lines against the Pentagon. They lost the contract, won in federal court, got quietly adopted by the exact intelligence agency the Pentagon sits above, and got invited to the White House. If you had told me in February that this sequence was survivable for Anthropic, let alone winnable, I would not have believed you. Hegseth declared the decision “final.” It was not.
Front three: capability, where OpenAI is about to swing
The third story is the one that requires the heaviest asterisk, so let me put the skepticism up front: none of what follows about a release date is officially confirmed by OpenAI, and the “A/B testing inside ChatGPT” claim traces to a very small, tightly-clustered set of primary sources — one YouTube channel, one Medium post, and one Geeky Gadgets writeup. Tibor Blaho’s TestingCatalog, which normally surfaces these model-selector A/B tests, has not published a dedicated piece on it. That absence is conspicuous.
What is well-sourced is the model itself. The Information reported on March 24 that OpenAI had finished pretraining on a next-generation model codenamed “Spud” at the Abilene Stargate facility, with Sam Altman telling staff it was “a very strong model that could really accelerate the economy.” On the Big Technology podcast, President Greg Brockman went on-record describing Spud as “a new base, a new pre-train” with “maybe two years’ worth of research coming to fruition,” and invoked the “big model smell” framing — the vibe when a model is not just smarter, but visibly bends to your intent. On April 13, The Verge published a leaked Q2 memo from OpenAI CRO Denise Dresser calling Spud “an important step in the intelligence foundation for the next generation of work” and saying it will make all OpenAI’s core products “significantly better.”
Polymarket as of April 20 priced “GPT-5.5 released by April 30” near 92%, with an April 23 release priced at 76–82%. Two OpenAI employees — @thsottiaux and @pashmerepat — posted cryptic teases on April 10–11. The leaker @synthwavedd claimed an early checkpoint was “superior to GPT-5.4,” though he also noted a small delay. @chatgpt21 said it is “still before the end of April and tentative for next week.”
Hold that date lightly. The base rate for missed insider-predicted AI launch windows in 2026 is high. What I am reasonably confident of is the capability direction: Spud is not a 5.4.1 point-release. If Brockman’s “big model smell” framing is even half-honest — and Brockman is not a man given to marketing overstatement — this is meant to be a genuine step-change over GPT-5.4 and a direct challenge to Opus 4.7. Whether it ships as GPT-5.5, GPT-5.5 Pro, or something numbered higher depends on how OpenAI judges the jump internally. Every source flags that naming as undecided, which itself is a signal.
What this adds up to
Lay the three fronts out next to each other and the picture gets interesting.
On the coding front, Anthropic is ahead in the workflow war and Google is openly scrambling to close the gap. That is not a rumor. Brin’s memo said it in almost those words.
On the national-security front, Anthropic held its red lines against the Pentagon, won in court, and is now being used by the intelligence agency that sits above the Pentagon. The White House is routing around the DoD blacklist. OpenAI, for its part, signed a $500M–$2B Pentagon deal in late February that Altman himself later called “definitely rushed” with optics that “don’t look good.” Ninety-eight OpenAI employees and 796 Google employees signed protest letters. Caitlin Kalinowski resigned. Anthropic took the harder position and is currently looking vindicated.
On the capability front, OpenAI is holding the biggest next-shoe, a model Brockman says contains two years of research and that a leaked internal memo promises will make every OpenAI product “significantly better.” The release window could slip. The A/B-testing-inside-ChatGPT claim could turn out to be wishful extrapolation. But the model is real and the window is short.
No single lab is winning the race, because the race is not one race. Anthropic is winning on workflow and on political navigation. OpenAI is positioned to win the next capability pop. Google has the research depth and the training corpus and almost everything else — except, right now, the agentic coding product that developers actually reach for, which is why Brin is personally force-marching a strike team.
What I am watching over the next two weeks
The Spud release window. If OpenAI ships a genuine step-change before May 1, every coding leaderboard in the industry resets and the Google strike team’s problem gets twice as hard overnight. If Spud slips into May or underwhelms, Anthropic’s coding lead consolidates and the political tailwind from the NSA-White House story has time to compound.
The Mythos disclosure timeline. Ninety-nine percent of Mythos’s findings remain unpatched. At some point those coordinated-disclosure windows close and a significant chunk of publicly catalogued CVEs will trace back, directly, to an Anthropic model. That is a narrative bomb — positive or negative depending on how it is framed in the press — and it is coming.
Google’s next Gemini release. Jetski and the Google-codebase-trained internal models are presumably the engine for a Gemini 3.2 or a Gemini 4. A well-timed coding benchmark sweep is the cleanest path back into the conversation. Whether Borgeaud’s strike team can deliver it in a quarter will define whether Google spends the rest of 2026 on the back foot.
And the quiet front, which is China. Jack Clark’s line — “a year to a year and a half later, there will be open-weight models from China that have these capabilities” — is the one I keep returning to. None of the three stories this week were about China. By the end of this year, every one of them probably will be.
The leaderboard is dead as an analytical frame. What we have instead is a front map. Once you start reading the news that way, this week looks less like a burst of unrelated stories and more like what it actually is: the first week of a phase of the AI industry in which the stakes, the strategy, and the scoreboard are each on different axes.
That is the shape of it. We will see on which of the three fronts the next shoe drops.
Thorsten Meyer writes about AI strategy, tooling, and editorial infrastructure at ThorstenMeyer.ai. Subscribe for weekly analysis of the frontier lab cycle.