Thorsten Meyer AI Foundations · 01 / 08
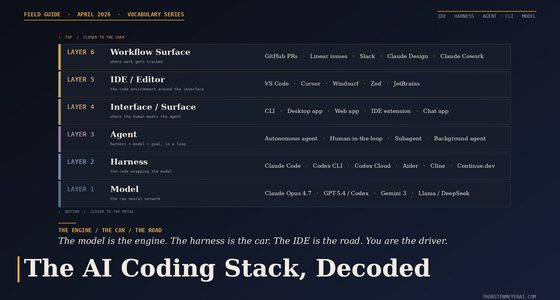
The three-layer stack behind every AI app you use
When you type a message into ChatGPT, you are not talking to GPT. You are talking to an app that talks to GPT.
This sounds like a technicality. It isn’t. It is the single most useful distinction for making sense of almost everything else about AI — why the same model behaves differently across products, why “Claude said X” is usually misleading, why vendor lock-in doesn’t work the way people assume, and why “regulating AI” is harder than it looks. Miss the distinction and everything downstream gets a little bit wrong.
So let’s get it right.


AI Operating Systems (Toward Artificial SuperIntelligence)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The three-layer stack
Every AI product you have ever used is built on the same three layers.
The model is a file of numerical weights produced by a training run. The weights are frozen once training ends. The model itself does not remember, does not learn, does not update. It is a static artifact — a brain in a jar, capable of processing, but inert until someone runs it.
Inference is the act of actually running the model on an input. You pass in some text, the weights transform it into probability distributions over next tokens, a decoding process picks tokens, and you get output. Inference happens millions of times per second across the global AI industry. Each inference call is independent — the model has no memory of the last one.
The application is everything the user actually touches. The chat interface. The hidden system prompt. The tools the model can call. The memory system that fakes continuity by stuffing your past conversations into each new prompt. The guardrails, the rate limits, the billing, the UI. The application is the body built around the brain in the jar.
When you open ChatGPT and type help me write an email, all three layers fire. The application takes your input, adds a system prompt you never see (“You are ChatGPT, a helpful assistant from OpenAI…”), retrieves relevant context from memory if memory is on, and sends the whole package to the inference service. Inference loads the model weights, runs the forward pass, and streams tokens back. The application receives those tokens, renders them in your chat window, stores the result, and bills your account.
You never see the model. You see the output of the application.

AI Systems Performance Engineering: Optimizing Model Training and Inference Workloads with GPUs, CUDA, and PyTorch
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What weights actually are
The model is a file. A big file — hundreds of billions of numbers for frontier models — but still a file. Each number is a parameter, and the parameters are the compressed statistical residue of a training process that consumed trillions of tokens of text, images, and code, plus enormous compute.
Training is a one-time, extremely expensive event. For a frontier model, it costs tens to hundreds of millions of dollars, takes weeks to months of wall time, and runs on specialized hardware clusters. At the end of training, you have a file. The file is the model. Training, as an activity, is over.
This matters because “the model learned from our conversation” is almost always wrong. Once training ends, the weights do not change when you use the model. Your conversation with ChatGPT does not update GPT’s weights. Your feedback might eventually feed into a future training run — which produces a new model — but the model you just talked to is unchanged by the fact that you talked to it.
What can update, and what people confuse with learning, is the application layer. Memory systems that store facts about you. Fine-tuned adapter layers that sit on top of a base model and specialize it. Retrieval systems that pull in relevant documents on demand. All of that lives at or around the application layer. The base model underneath stays frozen.
This is why a genuinely learning AI — one that updates itself from every interaction — is a hard, unsolved problem. What we have instead are apps that fake learning convincingly enough that most users never notice the difference. For most use cases, that’s good enough. For understanding what the technology actually is, the distinction is essential.

Thames & Kosmos Simple Machines Science Experiment & Model Building Kit, Introduction to Mechanical Physics, Build 26 Models to Investigate The 6 Classic Simple Machines
- Number of Models: Build 26 models to explore simple machines
- Includes All Classic Machines: Gears, wheels, axles, levers, pulleys, screws, wedges
- Durable Construction: Modular system compatible with other kits
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Inference is the hinge
Most of what you experience as “using AI” happens inside inference, and most users never think about it.
Every time you send a message, inference runs. The model takes your input plus whatever the application has packed around it, runs a forward pass, and produces output. Inference is cheap per call compared to training — cents rather than millions — but expensive in aggregate because it happens constantly, at scale, everywhere.
Inference is stateless by default. The model has no memory of the last call, the last user, or anything else. If an application wants continuity, the application has to provide it, typically by packing history back into the next prompt. Everything that feels like “the AI remembering me” is actually “the application stuffing my history back into the model every time it calls inference.”
Speed, cost, and availability all live at this layer. When a new model launches and the API is slow or overloaded, that’s inference capacity, not the model itself. When one app feels faster than another using the same underlying model, that’s inference optimization, not a better model. When a provider charges twice as much as a competitor for the same model weights, you are paying a premium on inference, not on intelligence.

AI Engineering: Building Applications with Foundation Models
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why this distinction matters — three places
Trust
Claude said something racist. GPT made up a fact. Gemini refused to answer.
In almost every viral AI-did-X story, the thing that actually did X was an application using a model, not the model in isolation. The same model behaves differently when wrapped in different system prompts, different tools, different guardrails, different fine-tunes, different retrieval layers. A model accessed raw through an API behaves differently from the same model accessed through a consumer chatbot with a two-thousand-word system prompt telling it how to behave.
Which means: when you read a story about what a model “said,” the correct next question is which application, which prompt, which configuration. Often the answer changes the story completely. Sometimes it changes who’s responsible.
Regulation
Regulating AI is not one thing. It is at least three things, because there are three layers, and they each require different regulation.
Regulating the model means regulating training data, compute thresholds, evaluation regimes, weights release policy. This is where most current AI regulation focuses, partly because it’s where the most concentrated decisions happen.
Regulating inference means regulating the services that run models — latency obligations, availability, data flow across borders, logging requirements, the compute infrastructure itself. Inference regulation barely exists yet, and it’s the layer where surveillance, data residency, and sovereign AI questions actually land.
Regulating applications means regulating how models are deployed — what they can be sold for, what users must be told, what human oversight is required, what accountability attaches to outputs. Application regulation is where sector-specific law (healthcare, finance, legal, education) is starting to show up.
Policy that conflates the three ends up badly calibrated. A rule designed for the model layer applied at the application layer becomes overreach. A rule designed for the application layer applied at the model layer becomes underreach. The three-layer framing is not a pedantic technicality — it is the structural basis for thinking clearly about where intervention belongs.
Procurement
When you buy AI, you are buying at a specific layer.
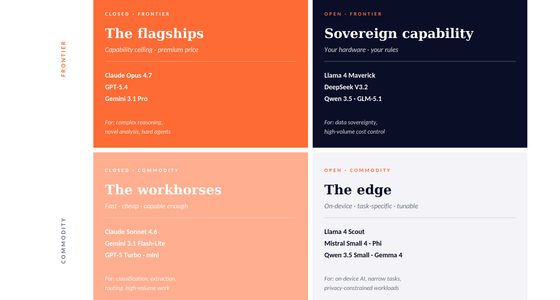
Buy at the model layer — the model API, calling Claude or GPT directly — and you get raw capability. You build everything above it. Your cost is per-token inference. Your lock-in is low, because switching from one model to another is a configuration change, not a migration.
Buy at the application layer — a chatbot, a copywriting tool, a code assistant — and you get a finished experience. You inherit the vendor’s choices about system prompts, guardrails, memory, integrations, and data policy. Your cost is per-seat or per-feature. Your lock-in is high, because your workflows, your data, and your institutional habits get built around the specific application, not the underlying model.
Most buyers don’t notice which layer they’re buying at. They assume they’re buying “AI” and end up locked into an application, not a model — which is a completely different kind of dependency, and one most procurement processes aren’t designed to catch.
The brain, the body, and you
The cleanest way to carry this framing around is the metaphor the engineers use themselves. The model is a brain in a jar. Inference is the act of running that brain on a question. The application is the body built around the brain — eyes, hands, mouth, memory, manners. You, the user, never touch the brain. You touch the body.
When the body does something surprising, the first question to ask is always: was that the brain, or was that the body? Almost always, it is the body.
Next in Thorsten Meyer AI Foundations: the three numbers — parameters, tokens, and context window — that shape every interaction with any model, and why they explain most of what users find surprising about AI behavior.