Thorsten Meyer AI Foundations · 06 / 08
The market map behind every model choice — and why “which is best” is the wrong question
Ask the same question of Claude, GPT, Gemini, and Llama and you’ll get four different answers. All four will be useful. None will be wrong in the “off by a fact” sense. But the four answers will reflect four different stances — on how to be helpful, what to prioritize, what to say about itself, what to refuse, how much to hedge. The differences aren’t noise. They’re design.
This is the piece where we stop treating models as interchangeable boxes labeled “AI” and start reading the market map. Because every meaningful decision downstream — which model to build on, which vendor to commit to, whether to multi-model, how much portability to engineer for — depends on where on the map you are.
The good news: the map has structure. Two dimensions explain most of it.


Domain-Specific Small Language Models: Efficient AI for local deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The two dimensions
Closed ↔ Open-weight. Closed models live behind an API you don’t control. The weights stay on the provider’s servers. You send prompts, they send completions, you pay per token. Open-weight models ship as files you can download and run yourself. The first category includes Claude, GPT, and Gemini. The second includes Llama, Mistral, Qwen, DeepSeek, and a growing list.
Frontier ↔ Commodity. Frontier models push capability forward — biggest training runs, latest techniques, highest benchmark numbers, flagship prices. Commodity models deliver proven capability cheaply — smaller, faster, tuned for volume, priced to move. The frontier moves; what was flagship in 2024 is commodity today. Both categories have their place. The confusion starts when you pay frontier prices for commodity work, or try to scale commodity models to frontier tasks.
Cross the two dimensions and you get a 2×2. Four quadrants. Each has a different economic logic, a different use case, and a different risk profile. Most serious AI stacks draw from at least two of them.

Large Language Models: The Hard Parts: Open Source AI Solutions for Common Pitfalls
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The four quadrants
Closed + Frontier. Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro. The flagships. These are what you reach for when capability matters more than cost — complex reasoning, nuanced writing, novel analysis, multi-step agentic work. You pay a premium per token. You get the best available. You also get the closest thing to a capability ceiling the market has to offer at any given moment.
Closed + Commodity. Claude Sonnet 4.6, Gemini 3.1 Flash-Lite, GPT-5 Turbo (and the various “mini” siblings). Fast, cheap, and genuinely capable at the tasks most production workloads involve. These are the workhorses. Most inference budgets spend here, because most tasks don’t need the frontier. Classification. Extraction. Routing. Summaries. Most of what a “chatbot” does behind the scenes is running through a commodity model, with the frontier model reserved for the hard cases.
Open + Frontier. Llama 4 Maverick, DeepSeek V3.2, the largest Qwen 3.5 releases, GLM-5.1. Serious capability you can run on your own infrastructure. Pick this quadrant when you need frontier-adjacent quality plus one of: data sovereignty (the inputs can’t leave your network), cost control at high volume (no per-token bill), or the ability to fine-tune deeply (not possible against closed APIs). You pay for it in GPU costs and operational complexity.
Open + Commodity. Llama 4 Scout, Mistral Small 4, Phi, Gemma 4, and the Qwen 3.5 small series (0.8B to 9B). The edge category. Runs on modest hardware, sometimes on-device. Picks up tasks where latency matters more than peak capability, where regulatory constraints forbid sending data anywhere, or where the task is narrow enough that a 9B parameter model fine-tuned for it beats a 200B general-purpose one. This quadrant is where on-device AI lives.
Most production stacks mix at least two quadrants. The mistake is assuming one quadrant fits all your use cases. It almost never does.

Personal AI Servers: A Guide to Building Private AI Infrastructure for Secure, Offline and Self-Hosted Local LLMs for Data Privacy
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why “best model” is the wrong question
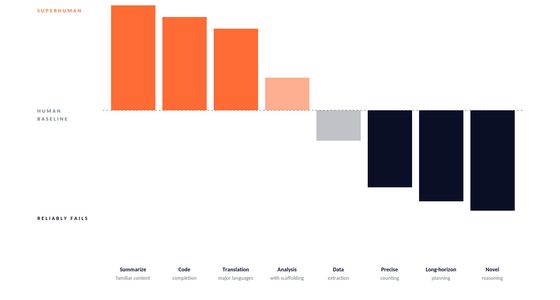
Every benchmark you read compresses four dimensions into one number. That compression is always lossy. A model can score 90% on a broad benchmark by crushing the peaks and partly failing on the valleys (see piece 03). A different model scores 88% by being more uniform. On the leaderboard, A wins. On your workload, B might feel like a completely different generation of technology.
Three questions move you from “which model is best” to something answerable.
What’s the task? A long-context analytical report, a structured data extraction, a real-time chat response, a code agent loop — these land in different parts of the capability map. Different providers have meaningfully different strengths. Test against your actual tasks, not their benchmarks.
What’s the stake? Rung 1 work (piece 05) can run on the cheapest commodity model you can find; the savings compound across millions of calls. Rung 4 work needs a flagship plus human verification regardless of cost. Matching model tier to verification rung is one of the highest-leverage decisions in any AI stack.
What’s the constraint? Data residency rules, latency budgets, cost targets, fine-tuning needs, and regulatory requirements all narrow the field before capability is even in scope. Sometimes “what’s best” turns out to be “what’s legal for this use case at our volume” — and that’s a different question with a different answer.

Building AI-Powered Products: The Essential Guide to AI and GenAI Product Management
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Choosing: a decision tree
Instead of picking a model, pick a decision sequence.
First, constraints. Do regulations or policies forbid sending this data to a third party? If yes, you’re in the open-weight quadrants — no amount of capability comparison between closed APIs matters, because none of them are eligible. Are there hard latency budgets the best closed APIs can’t hit? Same answer. Constraints eliminate most of the map before capability comparisons begin.
Second, stakes. Is this rung 1 work? A commodity model is almost always the right starting point — faster, cheaper, often plenty good enough. Is this rung 3 or 4? Start with a frontier model and engineer down only if cost or latency forces the question.
Third, fit. Among the models still in the running, build a private probe suite (piece 03). Five or six tasks from your real work. Run every candidate. Log the results. The winner is whichever performs best on your tasks, not whichever trends on the leaderboards.
Fourth, one lock-in check. If you’re about to commit to a single model in a long-running workflow, stop and design for portability. Can you route? Can you swap the model behind an abstraction? Can you move if pricing, policies, or capability shifts under you? If the answer is no to all three, the real question is whether you’re buying a model or buying a dependency.
Multi-model architectures
Serious production AI systems are increasingly multi-model by default. This is not sophistication for its own sake. It’s the logical consequence of the market map: different quadrants have different strengths, and real workloads span multiple quadrants.
A typical shape: a router decides which model to send each request to. Easy cases — classification, routing, short lookups — go to a commodity model. Harder cases — complex reasoning, code generation, careful analysis — go to a frontier model. Sensitive data goes to an open-weight model running on-premises. The router adds a layer of complexity; it also often saves 70–90% of total inference spend versus running every call through the flagship.
A second typical shape: ensemble. Two models answer the same question; a third judges or merges. Higher cost per call, but genuinely higher quality at the top of the capability curve. Reserved for tasks where that extra quality matters.
A third shape, growing fast: an agent loop where different steps use different models. The planner runs on the frontier model — it needs the reasoning capability. The executors run on commodity — each step is individually simple. The verifier might run on yet a third. The cost and latency profile is vastly better than one-frontier-model-for-everything.
If you’re building past prototypes, expect multi-model to be the norm within 12 months, not the exception.
Provider risk, named
Single-vendor AI strategies carry the same risks as single-vendor cloud strategies, plus a few new ones.
Pricing risk. Providers change prices. Not often, not dramatically — but they do. Your per-token costs in 2027 are not guaranteed to look like 2026’s. Workloads with thin unit economics are especially exposed.
Policy risk. Providers change what the model will do. A use case that worked in January can quietly stop working in March because of a policy update. Content policies, safety tunes, refusal behaviors, agent permissions — all subject to change. Your workflows inherit those changes whether you want them or not.
Capability risk. The model you built on gets deprecated. Providers sunset old versions to manage inference costs. You get a new model with similar benchmark scores and different behavior in the ten places your prompts depended on subtle quirks. This is survivable. It’s not free.
Availability risk. Outages happen. Rate limits tighten. A country gets added to a restricted list. These are rare individually, common in aggregate across enough time.
None of these is a reason to avoid closed-model providers. They are reasons to design for portability from day one, even when you’re only using one provider. The cost of portability is usually low at design time and expensive at retrofit time.
What this changes
Two shifts once you hold the map in mind.
Procurement gets granular. “We’re standardizing on X” is often a shortcut — convenient, but it locks your cost structure, risk profile, and capability ceiling to one provider’s roadmap. The better move is “we’re standardizing on an architecture, with X as the default model and open routing to others.” Same sentence length, radically different downstream flexibility.
The model market starts looking like the cloud market. Closed flagships for premium workloads. Open-weight and commodity for price-sensitive ones. Multi-provider as the default for anything production. A handful of hyperscalers plus a long tail. If this description sounds like cloud infrastructure circa 2015 — yes. The analogy is imperfect but it’s the best one available. Plan accordingly.
Next in Thorsten Meyer AI Foundations: models that talk are one thing. Models that act are another. Tools, agents, and the word “agentic.”