Part 2 of a five-day series on the 2026 memory crunch. Part 1 explained the squeeze; this one dissects the component causing it.
In Part 1 we said the factories that make your RAM now make something far more profitable instead. This is that something. Its name is High Bandwidth Memory, and in the space of three years it has gone from a niche specialty part to the single component that dictates the price and availability of nearly all the world’s memory — and, it turns out, a growing share of the world’s graphics cards too.
If you want to understand the memory squeeze, you have to understand HBM. So let’s open it up.
HBM ate the fab
The thing the factories make instead of your RAM is a tower of stacked memory bolted to every AI chip. In three years it went from niche part to the component that sets the price of nearly all the world’s memory — and now a chunk of its GPUs.
A tower, not a sheet
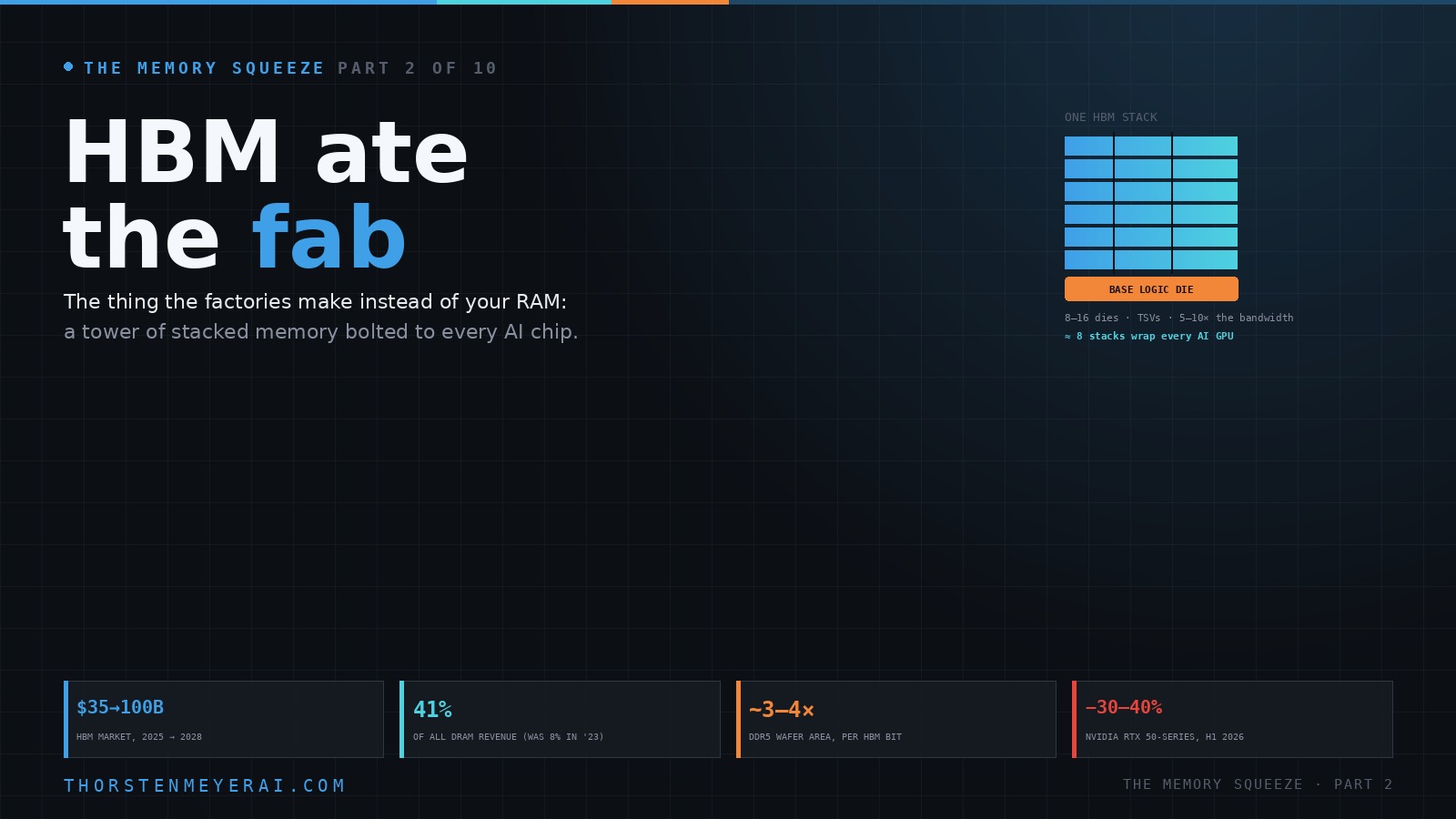
HBM stacks DRAM dies vertically, links them with thousands of through-silicon vias, and sits beside the GPU to deliver 5–10× the bandwidth of normal graphics memory. AI is bandwidth-bound — without it, the world’s most expensive silicon sits starved for data. But stacking is inefficient: one HBM bit eats 3–4× the wafer area of DDR5, and one defect can ruin a whole tower.
≈ 8 HBM stacks wrap every AI GPUThis isn’t artificial scarcity — AI really is bandwidth-bound, HBM really is the fix, and it really does eat 3–4× its weight in fab capacity. The discomfort is structural: one component, coupled to one customer’s demand, now sets the price of nearly all memory and a slice of GPUs. The market is now $35B → ~$100B by 2028, ~41% of all DRAM revenue (was 8% in 2023), and sold out through 2026. The one hope: with all three suppliers finally racing on HBM4, competition can add supply. The matching risk: if AI demand corrects, HBM is where it breaks first. Next: DDR5 now, DDR6 soon.
What HBM actually is
Standard DDR5 is a flat sheet of memory: chips laid out in two dimensions on a stick that plugs into your motherboard. HBM is a tower. It stacks eight, twelve, or sixteen DRAM dies vertically, drills thousands of microscopic vertical channels — through-silicon vias, or TSVs — straight through the silicon to connect them, sits the whole stack on a base logic die, and mounts it on an interposer millimeters away from the GPU it feeds.
The reason for all that engineering is one number: bandwidth. AI training and inference are memory-bandwidth-bound — the accelerator can do the math far faster than ordinary memory can feed it data, so the memory becomes the bottleneck. HBM solves that by being physically enormous in its connection to the chip: it delivers roughly five to ten times the bandwidth of the GDDR memory on a normal graphics card. A modern AI GPU doesn’t have one HBM stack; it has around eight of them wrapped around the compute die. Without HBM, the most expensive silicon in the world would sit idle, starved for data. That is why every AI accelerator that matters — Nvidia’s H100, H200, B200, and the coming Rubin; AMD’s MI300-series — is built around it.
High Bandwidth Memory (HBM) graphics cards
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why it’s so greedy with wafers
Here is the part that turns a clever technology into a global shortage. HBM is brutally inefficient to manufacture.
Stacking is hard. The dies are larger to fit the TSVs and interface logic, so fewer fit on each wafer. Yields are worse, because a single defect anywhere in a twelve-layer tower can ruin the entire stack. Net result, from Part 1: one bit of HBM consumes roughly three to four times the wafer area of one bit of DDR5. Every wafer a manufacturer points at HBM removes three or four wafers’ worth of ordinary memory from the world.
And they point a lot of wafers at it, because the economics are irresistible. An HBM3 stack runs on the order of $200; HBM3E around $300; the new HBM4, an estimated $500 a stack. Samsung and SK Hynix pushed HBM3E prices up about 20% for 2026 — a hike almost unheard of for a maturing memory product — and demand still outran supply. When the same wafer can become a $5 commodity module or part of a $500 stack the customer is begging for, the wafer becomes HBM. The squeeze on your RAM isn’t a side effect; it’s the arithmetic working exactly as designed.
HBM2 or HBM3 GPU memory modules
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The generational arms race
HBM moves on a relentless annual cadence, and each step both raises performance and tightens the wafer screws further.
HBM3 delivered around 819 GB/s per stack (the H100 era). HBM3E pushed past 1.18 TB/s and became 2026’s workhorse — each Nvidia H200, for instance, carries six HBM3E stacks. HBM4, ramping through 2026 for Nvidia’s “Rubin” platform, introduces a redesigned logic base die, data rates above 10 gigabits per second, and total bandwidth north of 2.8 TB/s, with capacities up to 48GB per stack. HBM4E follows in 2027–2028. Each generation is faster, denser, more packaging-intensive — and more expensive. The roadmap guarantees that the most wafer-hungry product in the fab keeps getting hungrier.
AI GPU with HBM memory
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The three-horse race for the most coveted chip
For most of HBM’s history the competitive question was binary: can you even ship a working stack? Through 2024–25, often only one company could ship at volume — SK Hynix, which got to HBM3E first, locked up the majority of Nvidia’s orders, and rode it to the top of the entire memory industry. SK Hynix still leads, with somewhere around 50–62% of the HBM market, and Nvidia reportedly accounts for roughly 90% of its HBM supply — a coupling so tight that SK Hynix is, functionally, Nvidia’s memory division.
The other two are clawing in. Samsung, after yield stumbles cost it the HBM3E generation, mounted a 2026 comeback — passing Nvidia’s HBM4 qualification and reportedly set to supply a large share of the Rubin platform’s HBM4. Micron sold out its entire 2026 HBM capacity and is targeting HBM4 for inference-class accelerators. The milestone came in June 2026, when Nvidia confirmed all three suppliers qualified and in production for Rubin — the first time an HBM generation has ramped with all three in the game at once. That shifts the question from “who can ship?” to “who ships at the best yield, price, and allocation?” It is the one development in this whole story that points, eventually, toward more supply rather than less.
stacked DRAM memory modules
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The money that bends the fab
To see why three of the planet’s largest manufacturers reorganized themselves around one product, follow the revenue. The HBM market was about $35 billion in 2025 and is projected to reach roughly $100 billion by 2028 — a ~40% annual growth rate in an industry that historically grew in the teens. HBM is forecast to contribute around 41% of all DRAM revenue in 2026, up from a mere 8% in 2023. And HBM capacity is sold out across all three suppliers through 2026.
That is the gravitational center of the entire memory squeeze. When nearly half your revenue and all your growth come from a product whose buyers will take everything you can make at rising prices, every other product — the DDR5 in your laptop, the chips in your phone — becomes an afterthought you make with leftover capacity.
It didn’t just eat your RAM — it ate your GPU too
The cruelest twist arrived for gamers and builders who thought this was only a RAM story. Because suppliers prioritize HBM and high-margin data-center memory, the specialized GDDR7 memory that consumer graphics cards need has gone short as well. Nvidia reportedly cut RTX 50-series production by 30–40% in the first half of 2026 to cope with GDDR memory constraints. The same wafer logic that doubled your RAM is now thinning the supply of the very GPUs you’d buy to run AI locally. The squeeze doesn’t stay in its lane.
The take
It would be satisfying to call HBM artificial scarcity, but that would be wrong, and the honest version is more unsettling. AI genuinely is bandwidth-bound; HBM genuinely is the solution; the demand is real and the manufacturing really is this inefficient. There is no villain hoarding chips in a warehouse — there is a spectacularly profitable component that legitimately consumes three-to-four times its weight in fab capacity, and a market rational enough to feed it first.
The discomfort is structural. A single component, coupled overwhelmingly to a single customer’s demand, now sets the price and availability of nearly all consumer and enterprise memory and a chunk of the GPU market. The one genuine hope is the three-horse race: with all three suppliers finally qualified on HBM4, competition moves from existence to economics, and that is the kind of pressure that eventually adds supply. The matching risk is that the same concentration makes the whole edifice fragile — if AI demand ever corrects, HBM is exactly where the overbuild and the pain would land first.
For now, the tower in the data center is eating the fab, and everything else in computing is standing in its shadow. Next in the series, we come back down to the part you actually buy: DDR5 Now, DDR6 Soon — a buyer’s field guide to the RAM market.
Sources: Silicon Analysts (HBM per-stack pricing, market share, qualification timeline); Introl (HBM TAM, SK Hynix/Nvidia coupling, RTX 50-series cuts); TrendForce and DigiTimes (HBM3E price hike, HBM4 supplier allocation, bit-share projections); Unibetter (HBM share of DRAM revenue); Astute Group and Reuters (Micron/Samsung HBM4 status). Bandwidth and capacity specs per JEDEC/vendor disclosures. Figures reflect reporting as of late June 2026 and are fast-moving. Analysis and opinions are the author’s.