
€37.4M EU budget, 20 organizations, four major EuroHPC supercomputers, 35 target languages. The project’s coordinator says: “significant challenges, especially in securing more compute for creating the final models, still remain.” This is what the pan-European pooled-resources answer to the sovereign-LLM question actually looks like.
By Thorsten Meyer — May 2026
This is the third standalone essay in the European sovereign-LLM track. In Essay 01, I extended Duarte O.Carmo’s analysis of Portugal’s AMÁLIA — the continuation pre-training answer. In Essay 02, I walked Italy’s Minerva — the from-scratch national investment answer. Both essays referenced a third architectural path that I deferred to a separate piece. This is that piece. The pan-European pooled-resources answer — OpenEuroLLM.
The structural argument I’ve been building across the track: each European sovereign-LLM project represents a different bet about what scale of investment, what architectural commitment, and what institutional model produces results that justify the public spending. Italy bet national. Portugal bet continuation. The EU bet consortium. The OpenEuroLLM project — coordinated by Jan Hajič at Charles University in Prague, co-led by Peter Sarlin at AMD-owned Silo AI in Finland, funded by €20.6M from the EU’s Digital Europe Programme as part of a €37.4M total budget, with 20 partner organizations spanning universities, companies, and high-performance computing centers across the continent — is what the consortium answer looks like in operational form.
And the project lead is publicly stating that even at pan-European pooled scale, compute is the bottleneck. From the March 6, 2026 first-year progress report:
“Creating an open source multilingual LLM in the public space and within a large consortium is a challenging task. I am proud that thanks to the expertise, enthusiasm, commitment and hard work of especially the core partners the project has achieved its first-year goals. However, significant challenges, especially in securing more compute for creating the final models, still remain.“ — Jan Hajič, Charles University
This is the structural editorial anchor for this piece. The pan-European consortium answer — explicitly designed as the response to individual national projects’ resource constraints — is itself constrained by the same resource that limits national projects: compute. The empirical complication that the prior essays each surfaced (Minerva’s INVALSI 4.9% finding, AMÁLIA’s 5.5% pt-PT share) finds its OpenEuroLLM equivalent in Hajič’s own statement. Each of the three answers, examined honestly, surfaces a complication the press coverage downplays.
The headline finding of this piece: the European sovereign-LLM movement’s three answers — Minerva from-scratch, AMÁLIA continuation, OpenEuroLLM consortium — are now operating at sufficient scale and duration that their structural limits are visible. None of them is the answer. Each of them is an answer. The strategic discourse benefits from treating all three as complementary data points in the same empirical experiment about what European sovereign-AI development actually requires.
This piece walks the OpenEuroLLM project forensically, surfaces the structural finding that Hajič’s own statement crystallizes, situates the consortium answer within the three-way comparison, and closes with what the project’s July 2026 first-models deliverable will determine. The standard caveat applies: OpenEuroLLM is one year into a three-year project. First models are due July 31, 2026 — six weeks from publication of this essay. The structural assessment may shift materially when those models actually ship.
OpenEuroLLM.
The third
path.
€37.4M EU budget, 20 organizations, four major EuroHPC supercomputers, 35 target languages. And the project’s coordinator says: “significant challenges in securing more compute still remain.”
Italy bet national. Portugal bet continuation. The EU bet consortium. OpenEuroLLM — coordinated by Jan Hajič at Charles University Prague, co-led by Peter Sarlin at AMD-owned Silo AI — is what the pan-European pooled-resources answer looks like in operational form. And the project lead is publicly stating that even at pan-European pooled scale, compute is the bottleneck. Each of the three sovereign-LLM answers, examined honestly, surfaces a complication the press coverage downplays.
Even at pan-European scale, compute is the bottleneck.
From the OpenEuroLLM first-year progress report, March 6, 2026. The single most important sentence in the public documentation of the project. The pan-European consortium answer — explicitly designed as the response to individual national projects’ resource constraints — is itself constrained by the same resource that limits national projects.
First-year progress and next steps · March 6, 2026

Dell Computers PowerEdge R740 Server 2X Gold 6154 3.00Ghz 36-Core 384GB RAM 16x Caddies (Renewed)
Renewed server with the highest quality standards
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
12 universities. 6 companies. 3 HPC centers. One conspicuous absence.
The OpenEuroLLM consortium combines academic NLP research, commercial AI capability, and EuroHPC supercomputing infrastructure across multiple European nations. The breadth is the strategic bet. The breadth is also the operational complication.

Polyglot Multilingual Language Language T-Shirt
Multilingual language design for men or women who speak multiple languages.
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Eleven deliverables. Two shipped. Nine pending.
From the official deliverables roadmap. As of mid-May 2026, only two of eleven deliverables have shipped — both from July 2025. The July 31, 2026 cluster — first models, initial dataset, evaluation code — is when OpenEuroLLM becomes empirically comparable to Minerva and AMÁLIA.

NVIDIA DGX Spark™ – Personal AI Desktop Supercomputer – Desktop GB10 Grace Blackwell Chip
Supercomputer performance directly to your desk in a compact, energy-efficient design, enabling enterprise-scale AI and high-performance computing right…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Three answers. Three structural findings.
The Minerva from-scratch path. The AMÁLIA continuation path. The OpenEuroLLM consortium path. Each project surfaces an empirical complication the press coverage downplays. Each finding is harder than the framing it’s wrapped in.
Three projects. Three findings. Each one harder than the framing it’s wrapped in. Each answer is valid for its specific positioning and resource context. None of the three is “the right answer” in the abstract. The strategic discourse benefits from treating all three as data points in the same empirical experiment.
EU digital infrastructure hardware
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
First models in six weeks. Three scenarios.
The July 31, 2026 first-models deliverable is the strategic moment for OpenEuroLLM specifically and for the European sovereign-LLM movement broadly. Three scenarios are plausible. The structurally honest framing will require acknowledging whatever the empirical results actually show.
OpenEuroLLM is one valid answer to the European sovereign-LLM question. AMÁLIA is another. Minerva is a third. Mistral is potentially a fourth — the commercial-frontier answer this essay track examines next. The strategic discourse benefits from treating all of them as complementary experiments in the same empirical question. More analysis like this is needed. Not less.
I · What OpenEuroLLM actually is · the institutional and technical foundation
The factual baseline before the structural argument. From the official project documentation, the February 3, 2025 launch press release, TechCrunch’s launch coverage, Fortune’s funding analysis, the European Commission STEP Seal announcement, and the March 6, 2026 first-year progress report.
The institutional architecture
OpenEuroLLM is coordinated by Jan Hajič, computational linguist at Charles University’s Institute of Formal and Applied Linguistics (ÚFAL) in Prague. Hajič has been coordinating the High Performance Language Technologies (HPLT) project since 2022 — the predecessor effort that established much of the data infrastructure, partner relationships, and technical foundations OpenEuroLLM now builds on. The co-lead is Peter Sarlin, CEO and co-founder of Silo AI — the Finnish AI lab that AMD acquired for $665 million in 2024, making Silo AI the operational AI lab inside AMD’s European footprint.
The consortium spans 20 organizations across three categories:
Universities and Research Organizations (12 institutions):
- Charles University (Czechia, coordinator)
- AI Sweden
- ALT-EDIC (Alliance for Language Technologies EDIC, France)
- University of Tübingen (Germany)
- ELLIS Institute Tübingen (Germany)
- Fraunhofer IAIS (Germany)
- Barcelona Supercomputing Center / BSC (Spain)
- Forschungszentrum Jülich (Germany)
- Eindhoven University (Netherlands)
- University of Helsinki (Finland)
- University of Oslo (Norway)
- University of Turku (Finland)
Companies (6 organizations):
- Aleph Alpha (Germany)
- AMD Silo AI (Finland, AMD-owned)
- Ellamind (Germany)
- LightOn (France)
- ELDA (Evaluations and Language resources Distribution Agency, France)
- Prompsit Language Engineering (Spain)
HPC Centres (3 organizations):
- CINECA (Italy — operating Leonardo, the supercomputer that trained Minerva)
- CSC (Finland — operating LUMI, one of Europe’s top supercomputers)
- SURF (Netherlands)
Notable absence: Mistral, the French AI unicorn. From TechCrunch’s reporting, Hajič stated: “I tried to approach them, but it hasn’t resulted in a focused discussion about their participation.” This is structurally significant — Mistral has positioned itself as Europe’s commercial open-source alternative to US frontier developers, and its absence from the official EU sovereign-LLM consortium reflects a strategic-positioning divergence I’ll return to in the next standalone essay in this track.
The funding architecture
€37.4 million total budget for the model-building work specifically. €20.6 million from the EU’s Digital Europe Programme under grant agreement No 101195233. Industry partner researcher time and contributions arguably double the effective budget when factored in. The project is part of the EU’s Strategic Technologies for Europe Platform (STEP) framework — OpenEuroLLM was the first Digital Europe Programme project to receive a STEP Seal (February 3, 2025), the EU’s mark of excellence for strategic technology investments.
The scale comparison from Fortune’s February 2025 coverage is structurally important: €37.4 million is approximately $38.6 million USD — “a pittance compared with the sums being invested in other AI-related projects like the $100 billion first tranche of the U.S.’s Stargate AI infrastructure project.” The pan-European consortium budget is approximately 0.04% of the US Stargate first tranche. Even when industry researcher contributions and compute allocations are factored in, the order-of-magnitude difference holds.
But the compute side of the calculation is more favorable. The broader EuroHPC project has a budget of approximately €7 billion — and OpenEuroLLM has secured strategic compute allocations on four major EuroHPC supercomputers as of December 2025. The structurally most important specific allocations:
- 3 million GPU hours on Leonardo BOOSTER (CINECA, Italy) — awarded via the EuroHPC AI Factory Large Scale call EHPC-AIF-2025LS01-028 — for the MultiSynt synthetic multilingual data project
- 1.5 million GPU hours on LUMI (Finland, CSC) — awarded via the Finnish LUMI Extreme Scale Access program
- Strategic compute resources on four major EuroHPC supercomputers (Leonardo, LUMI, MareNostrum 5, and a fourth allocation) secured for the remainder of the project per the December 12, 2025 announcement
This is real scale. 4.5 million combined GPU hours across just the two named allocations is structurally comparable to what a frontier-model developer like Anthropic or OpenAI commits to a major training run. The compute substrate is operational. Hajič’s “still need more compute” framing in the first-year progress report is therefore not a baseline-resource-availability complaint — it is a frontier-model-class compute requirement statement.
The technical scope and goals
OpenEuroLLM’s stated technical scope from the official project page:
- Multilingual foundation models for EU official languages and beyond — 24 official EU languages plus candidate-country languages (Albanian and others) plus strategic global languages, totaling 35 target languages per Peter Sarlin’s reporting
- Truly open — data, documentation, training and testing code, evaluation metrics, community involvement
- EU AI Act compliant — designed to meet the regulatory framework that became effective February 2, 2025 (one day after OpenEuroLLM’s official start date — the timing is not coincidence)
- Diverse for European languages and other socially and economically interesting ones, preserving linguistic and cultural diversity
- Compute compliance — partner HPC centers handle training; the project explicitly architecturally avoids dependency on any single cluster
- Software stack and infrastructure for distributed training across European clusters — the project is building the substrate, not just the models
The deliverables roadmap
From the official deliverables page — and this is structurally important because as of mid-May 2026, only 2 of 11 deliverables have shipped:
Shipped (July 31, 2025):
- D3.1 · Initial training data catalogue and analytics reports
- D6.1 · Communication, Dissemination and Exploitation Strategy
Due July 31, 2026 (6 weeks from publication of this essay):
- Initial dataset release · texts with metadata used to train the model at mid-project
- First models · initial release of LLM models (tokenizers and model weights)
- Evaluation Code package · Python package for model evaluation procedures
Due July 31, 2027:
- Final dataset release · texts with metadata for final OpenEuroLLM model(s)
Due January 31, 2028:
- Stakeholder Report
- Final models · final release of LLM models (tokenizers and model weights)
- LLM training report · open publishing and regulatory compliance details
- Evaluation Report · multilingual and regulatory aspects findings
- Evaluation Report of Communication, Dissemination and Exploitation Strategy
The July 31, 2026 first-models deliverable is the strategic moment for OpenEuroLLM. It is also the strategic moment for the broader European sovereign-LLM movement, because the first-models release will be what makes the consortium answer empirically comparable to Minerva (operational since November 2024) and AMÁLIA (final version June 2026). For approximately six weeks between AMÁLIA’s June 2026 final release and OpenEuroLLM’s July 2026 first models, all three answers will have operational artifacts for the first time. This is the moment the structural comparison becomes empirically tractable.
II · What OpenEuroLLM has produced in year one · operational outputs before first models
The first-year progress report and accumulated blog posts document significant operational outputs even before the formal first-models deliverable ships. These are research-grade contributions that demonstrate the consortium machinery is functional, even if the headline model release is still 6 weeks away.
Open-sci-ref 0.01 · scaling-laws reference models
Released August 22, 2025 in collaboration with Open-sci. A research-dense transformer model family designed to establish scaling laws for ranking datasets and other hyperparameters. With all intermediate checkpoints public — the kind of methodological transparency that benefits the broader research community independent of OpenEuroLLM’s eventual headline models. This is the “Olmo standard” operational openness I argued for in the AMÁLIA essay, applied at the OpenEuroLLM scale.
HPLT v2 · 38 monolingual reference models
Released July 17, 2025 in collaboration with the HPLT (High Performance Language Technologies) initiative — Hajič’s predecessor project. 38 monolingual reference models with 2.15B parameters each, full models and intermediate checkpoints every 1,000 steps. Available at the HPLT/hplt-20-monolingual-reference-models Hugging Face collection. The cross-lingual comparison infrastructure that the consortium answer requires.
MixtureVitae · permissive open web-scale pre-training dataset
Released as arXiv 2509.25531 in collaboration with LAION, Ontocord, and Open-sci. The first permissive open web-scale pre-training dataset that matches or outperforms strong non-permissive datasets like FineWeb-Edu and DCLM. Particularly strong on mathematics and code reasoning. This is structurally important for European sovereign-LLM development specifically — the EU AI Act and European copyright directive constrain what training data European developers can use redistributively, and a permissive open dataset that performs comparably to non-permissive alternatives is operationally significant for compliance.
MultiSynt · synthetic multilingual pre-training data
The MultiSynt MT-Nemotron-CC dataset is described as the first comprehensive multilingual synthetic pre-training dataset. Methodology based on Nvidia’s Nemotron-CC extended to multilingual. The MultiSynt project operates as a four-phase strategy with the 3 million GPU hours on Leonardo BOOSTER allocation:
- Phase 1 (20% of GPU hours): Quality estimation models, 100M-4B parameters
- Phase 2 (20% of GPU hours): Synthetic data generation pipelines, up to 50B token synthetic datasets
- Phase 3 (10% of GPU hours): End-to-end ablation studies, 100M-2B parameter models trained on up to 200B tokens
- Phase 4 (50% of GPU hours): Production · minimum 1T tokens synthetic multilingual dataset · several 8B parameter models on up to 1T tokens each · ~100K A100-hour runs
This is the operational pipeline for OpenEuroLLM’s eventual first-models release. The Phase 4 production output is what feeds the July 2026 first-models deliverable.
The OpenEuroLLM training data catalogue
The GitHub repository provides a uniform, collectively curated, well-documented collection of candidate LLM training datasets. Datasets are made publicly available (read-only) across multiple EuroHPC systems — LUMI, Leonardo, and MareNostrum — to avoid duplicative storage and effort. This is institutional infrastructure that benefits not just OpenEuroLLM but every European sovereign-LLM project that needs access to vetted European-language training data.
The 2B/100B and 2B/4TT reference models
Internal research outputs from the consortium’s first year: 2B-parameter reference models trained on 100B tokens for cross-lingual comparison, and 2B-parameter models trained on 4 trillion tokens for studying multilingual data mixes and determining optimal language proportion within training datasets. These inform the scaling decisions for the eventual headline models — they are the empirical foundation for the Phase 4 production runs.
What this operational output demonstrates
OpenEuroLLM has produced a year of structurally important research outputs before its first formal headline models ship. The consortium machinery is operational. The methodological transparency exceeds the Olmo standard in some dimensions (e.g., intermediate checkpoints every 1,000 steps for the HPLT reference models). The infrastructure work — distributed training across European clusters, training data catalogues, evaluation harnesses — is the institutional substrate that makes the headline models possible.
This complicates the simple “consortium is slow” critique. The Anastasia Stasenko (Pleias) skepticism I quoted from TechCrunch — “sprawling consortia of 20+ organizations” vs the focused approach of agile firms like Mistral and LightOn — has structural merit as a critique of decision-velocity. But it underweights the institutional-infrastructure contribution that consortia produce that agile firms structurally cannot. The MixtureVitae dataset, the HPLT reference models, the training data catalogue, the open-sci scaling-laws reference family — these are public goods that single-firm AI development does not produce.
The legitimate critique is whether the consortium’s headline models, when they ship, will be empirically competitive with what Mistral, Minerva, or AMÁLIA produce at the same parameter scales. That question is answered July 31, 2026.
III · The Hajič compute bottleneck · the structural editorial finding
The most important sentence in the March 6, 2026 first-year progress report is the one I quoted at the top of this essay:
“However, significant challenges, especially in securing more compute for creating the final models, still remain.”
This is the structural editorial finding of this piece. Even at pan-European pooled scale, the project lead is publicly stating compute is the bottleneck. This deserves careful unpacking, because it inverts the standard framing of why the EU consortium answer was structured the way it was.
The standard framing · why the consortium answer was designed
The strategic logic for OpenEuroLLM as a pan-European consortium rather than a national project was, partly, that individual European nations cannot sustain the compute investment frontier-model development requires. Italy’s Minerva project secured 128 GPUs simultaneously on Leonardo for weeks of training — substantial but a fraction of what frontier developers use. Portugal’s AMÁLIA does not publicly detail its compute infrastructure. France’s Mistral has gone the commercial route to access frontier-scale compute through revenue and venture funding. The pan-European consortium answer was supposed to be the alternative: pool the resources of multiple nations and the EU itself, and access frontier-class compute through that pooling.
What Hajič’s statement actually means
OpenEuroLLM has secured:
- 3M GPU hours on Leonardo BOOSTER (MultiSynt allocation)
- 1.5M GPU hours on LUMI
- Strategic compute on four major EuroHPC supercomputers through project end (December 2025 announcement)
- Industry partner contributions that arguably double the effective resource base
This is structurally substantial — and Hajič is publicly stating it is insufficient for the final models the project aims to produce. The implication: the pan-European consortium answer, as currently funded and resourced, may not produce final models at the parameter scale required to compete with frontier developers on general capability. Or — more precisely — Hajič is signaling that additional compute will need to be secured beyond the current strategic allocations for the January 2028 final models deliverable to meet its stated ambitions.
Three implications
Implication 1 · The Stasenko critique partially holds. Pleias co-founder Anastasia Stasenko’s skepticism — that 20+ organization consortia struggle to maintain focus — is partly answered by the year-one operational outputs (the consortium machinery clearly works for research-grade outputs) and partly not answered by the compute statement (resource pooling at this scale is itself a coordination problem that adds friction to compute access).
Implication 2 · The EU’s regulatory-vs-investment imbalance is operationally visible. The EU AI Act became effective February 2, 2025 — one day after OpenEuroLLM’s official start date. The regulatory framework is operational. The investment framework — €37.4M model budget, even with €7B EuroHPC infrastructure context — is structurally smaller than US frontier-developer commitments by orders of magnitude. Hajič’s compute statement is the operational artifact of this imbalance. Europe is regulating a frontier it is structurally underinvested in actually competing on.
Implication 3 · Position 1 may not be the OpenEuroLLM target. In the strategic-positioning framework from the AMÁLIA essay, Position 1 was “match the frontier on overall capability.” OpenEuroLLM’s stated goals include “performant” multilingual foundation models — but Hajič’s compute statement implies the project may need to recalibrate to Position 2 (sovereignty/openness/compliance) and Position 3 (country-knowledge depth across 35 languages) rather than competing with Llama / Mistral / Gemini on raw capability benchmarks. This would be a strategic-positioning narrowing that is not currently public — but it is the structural implication of the compute statement.
What the press coverage misses
Most coverage of OpenEuroLLM treats the project as Europe’s answer to the US/China AI race. Some coverage frames it as “Europe’s First Big AI Chatbot, OpenEuroLLM Aims to Compete with ChatGPT & DeepSeek.” Fortune was more honest about the budget asymmetry. But none of the major coverage I’ve found has foregrounded Hajič’s own March 2026 statement that compute remains the bottleneck.
This is the same discourse pattern I documented in the AMÁLIA and Minerva essays. Press coverage of European sovereign-LLM projects emphasizes the institutional achievements (real and important) without surfacing the technical findings that complicate the simple narrative. The Hajič compute statement is to OpenEuroLLM what the INVALSI 4.9% finding is to Minerva and the 5.5% pt-PT share is to AMÁLIA: the empirical finding the press coverage downplays.
Three projects. Three findings. Each one harder than the framing it’s wrapped in.
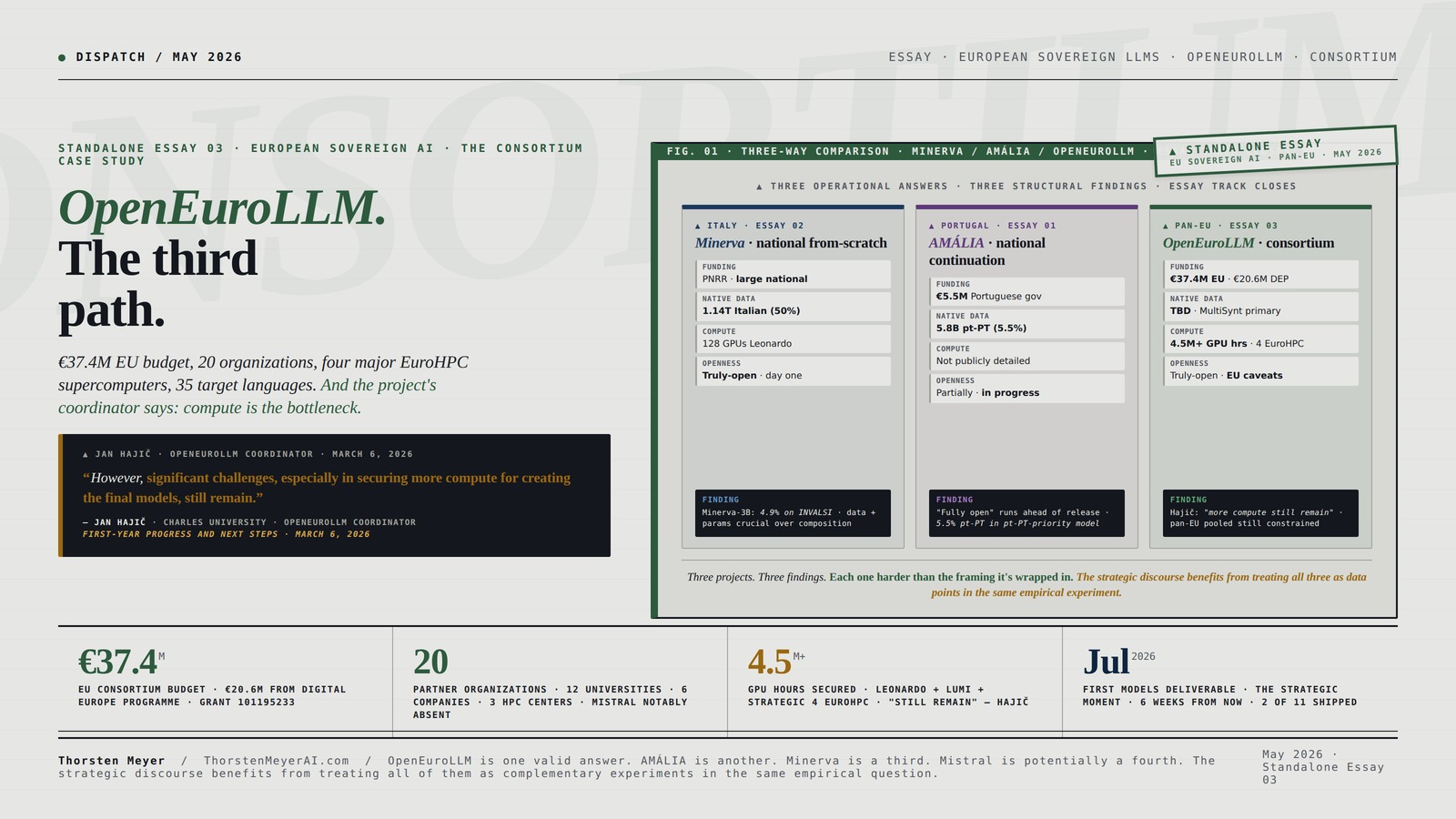
IV · The three-way structural comparison · Minerva, AMÁLIA, OpenEuroLLM
With OpenEuroLLM now documented at the same level of detail as the prior two essays, the three-way structural comparison becomes possible.
The architectural comparison
| Dimension | Minerva (Italy) | AMÁLIA (Portugal) | OpenEuroLLM (Pan-EU) |
|---|---|---|---|
| Strategic answer | National from-scratch | National continuation | Pan-European consortium |
| Coordinator | Sapienza NLP / FAIR | NOVA / IST / IT / FCT | Charles University / AMD Silo AI |
| Lead | Roberto Navigli | (consortium-led) | Jan Hajič + Peter Sarlin |
| Funding | PNRR via MUR PE0000013-FAIR | €5.5M Portuguese gov | €37.4M EU (€20.6M Digital Europe) |
| Partner organizations | ~15 named researchers + CINECA + NVIDIA + Babelscape | ~60 researchers across 4 institutions | 20 organizations (12 univ. + 6 companies + 3 HPC centers) |
| Languages targeted | Italian + English | Portuguese (pt-PT) | 35 languages (24 EU + others) |
| Architectural commitment | From scratch · Mistral arch · custom IT tokenizer | Continuation of EuroLLM | From scratch · methodology-in-development |
| Native-language data | 1.14T Italian tokens (50% of 7B) | 5.8B clearly pt-PT (5.5% of 107B mid-training) | TBD · MultiSynt synthetic data primary path |
| Total training data | 2.5T tokens (7B model) | 107B tokens extended pre-training | TBD · 8B model planned summer 2026 |
| Compute | 128 GPUs on Leonardo, weeks | Not publicly detailed | 4.5M+ GPU hours secured across 4 EuroHPC systems |
| Openness | Truly-open (weights + data + code, day one) | Partially open (research-in-progress) | Truly-open commitment (with some EU-copyright caveats) |
| First public release | April 2024 (preview), Nov 2024 (7B) | September 2025 (base) | July 31, 2026 (first models target) |
| Final release target | Ongoing iteration | June 2026 (final version) | January 31, 2028 (final models) |
| Structural finding | Minerva-3B: 4.9% on INVALSI | 5.5% pt-PT in mid-training | Hajič: “significant challenges… in securing more compute… still remain” |
Each project surfaces an empirical complication the press coverage downplays. Italy’s complication: even from-scratch 50% Italian doesn’t produce strong performance at small parameter scales. Portugal’s complication: the model that’s supposed to prioritize European Portuguese has 5.5% European Portuguese in extended pre-training. The EU’s complication: even pan-European pooled scale has compute as the bottleneck.
The strategic-positioning comparison
In the four-position framework from the AMÁLIA essay:
| Project | Position 1 (frontier-match) | Position 2 (sovereignty/openness) | Position 3 (country-knowledge depth) | Position 4 (vertical specialization) |
|---|---|---|---|---|
| Minerva | Not targeted explicitly | ✓ Operational (truly-open) | ✓ Strong commitment, scaling-limited at 7B | Not the primary path |
| AMÁLIA | Not targeted | Partial (openness claim, not yet operational) | Partial (5.5% pt-PT share insufficient) | Not the primary path |
| OpenEuroLLM | Stated goal · compute-constrained | ✓ Strong commitment (EU AI Act compliance) | Targeted across 35 languages | Not the primary path |
OpenEuroLLM is the only one of the three explicitly targeting Position 1 (frontier-match on overall capability). Hajič’s compute statement is the public signal that Position 1 may not be achievable within current resource commitments. If the consortium recalibrates toward Position 2 + Position 3 as the primary positioning — which the compute statement implies it may need to — then OpenEuroLLM converges toward the same positioning combination Minerva already operates within.
The temporal comparison
All three projects converge to operational artifacts in summer 2026:
- June 2026 · AMÁLIA final version target
- July 31, 2026 · OpenEuroLLM first models deliverable
- Summer 2026 · OpenEuroLLM 8B model target (stated in Hajič’s first-year progress report)
- Ongoing · Minerva-7B continued iteration; continual training research per CLiC-it 2025
This is the strategic moment for the European sovereign-LLM movement. For the first time, all three answers will have operational artifacts that can be empirically compared on the same benchmarks at the same time. The strategic discourse that has been speculative for two years becomes data-grounded for the first time in summer 2026.
V · What the OpenEuroLLM case demonstrates beyond the project itself
Three structural lessons emerge from the OpenEuroLLM case that extend the analysis from the prior two essays.
Lesson 1 · The institutional infrastructure work is the durable contribution
Even if OpenEuroLLM’s headline models don’t compete with frontier developers on general capability, the institutional infrastructure the consortium has built in year one is structurally important and durable. The MixtureVitae permissive open dataset. The HPLT 38 monolingual reference models. The open-sci scaling-laws reference family. The training data catalogue across LUMI / Leonardo / MareNostrum. The distributed training infrastructure across European clusters. These are public goods that benefit every subsequent European sovereign-LLM effort — and they exist now because the consortium model produces them.
This is the structural argument for the consortium answer that the press coverage hasn’t foregrounded. National projects (Minerva, AMÁLIA) produce models but tend not to produce the cross-cutting infrastructure that multi-language research requires. Commercial actors (Mistral, Aleph Alpha) produce models but don’t produce open public-goods infrastructure as a primary deliverable. The consortium model produces both — at the cost of slower decision-velocity on the headline model deliverable.
Lesson 2 · The EU AI Act compliance dimension is operationally significant
OpenEuroLLM started one day before the EU AI Act became effective. This timing is structural, not coincidental. The project is designed to be the reference implementation of how to develop frontier-capability AI within the EU AI Act framework. Every architectural choice — truly-open openness commitment, distributed compute across European HPC centers, partner consortium spanning academic and commercial actors, methodology transparency — is structured to demonstrate EU AI Act compliance is operationally achievable for frontier development.
This is competitive positioning that US and Chinese frontier developers cannot match. OpenAI, Anthropic, Google, and the Chinese frontier labs do not architect their development processes around EU AI Act compliance — they architect for capability and then retrofit compliance. OpenEuroLLM is the operational demonstration that compliance-first development is possible. Whether it produces capability-competitive models is the question that the July 2026 first models will partially answer.
Lesson 3 · The compute investment gap is the binding constraint
Hajič’s compute statement crystallizes the structural reality. The European sovereign-AI agenda is constrained by compute investment more than by talent, methodology, openness, or coordination. Italy’s Minerva used 128 GPUs on Leonardo. OpenEuroLLM has secured 4.5M+ GPU hours across multiple EuroHPC systems — and the project lead publicly says more compute is needed for final models. The compute gap between European and US frontier development is the binding structural constraint that no amount of consortium pooling or regulatory framework operationalization can directly close.
This points toward an unstated structural question: does the European sovereign-LLM movement need to recalibrate its strategic ambitions to match its compute investment, or does it need to substantially increase its compute investment to match its strategic ambitions? The €7B EuroHPC budget is real, but it serves many projects and is structurally smaller than what a single US frontier developer commits to a single training run cycle. This is the question the July 2026 first models will force into public discourse, because the empirical comparison with US frontier developers becomes unavoidable when operational artifacts exist.
VI · The closing argument · what the July 2026 moment will determine
OpenEuroLLM’s July 31, 2026 first models deliverable is the strategic moment for the project specifically and for the European sovereign-LLM movement broadly. Three scenarios are plausible:
Scenario A · The first models are capability-competitive at their parameter scale. If OpenEuroLLM’s 8B model demonstrates competitive performance against frontier developers’ similar-scale models on multilingual benchmarks, the pan-European consortium answer is validated. The strategic positioning combines Position 1 (frontier-competitive at relevant scale), Position 2 (sovereignty/openness/compliance), and Position 3 (multilingual depth across 35 languages). This would be the strongest outcome for the European sovereign-LLM movement broadly — it would demonstrate that pan-European pooling produces results that individual national projects cannot.
Scenario B · The first models are methodologically interesting but capability-limited. If the 8B model demonstrates strong multilingual capability but lags frontier developers on general benchmarks, the project converges toward Position 2 + Position 3 positioning — sovereignty/openness/compliance combined with multilingual specialization, deprioritizing the frontier-match ambition. This is the most likely outcome given Hajič’s compute statement and the structural funding asymmetry with US frontier developers. It would validate the consortium answer for its specific positioning while making the strategic ambition recalibration explicit.
Scenario C · The first models surface a finding that complicates the simple narrative. Each of the prior two European sovereign-LLM projects surfaced a structural finding the press coverage downplayed (Minerva’s INVALSI 4.9%, AMÁLIA’s 5.5% pt-PT share). OpenEuroLLM’s first models will likely surface their own version. The compute statement is one such finding. The 35-language coverage commitment may produce another — for example, very uneven performance across the language portfolio, with strong results for high-resource languages and weak results for lower-resource languages. The structurally honest framing will require acknowledging whatever this complication turns out to be.
In all three scenarios, the discourse that O.Carmo’s analysis of AMÁLIA modeled and that this essay track has attempted to extend is what the moment requires. Holding competing views simultaneously: the work is real AND the empirical findings are harder than the press coverage suggests. The institutional achievement is substantial. The structural complications are real. Both can be true at once.
For the European sovereign-LLM movement broadly, the three-way comparison this essay track has built — Minerva from-scratch, AMÁLIA continuation, OpenEuroLLM consortium — produces three observations that the public discourse should internalize:
- Each answer is valid for its specific positioning and resource context. None of the three is “the right answer” in the abstract. Each makes sense for what its sponsors can actually sustain.
- All three surface empirical complications at scale. Press coverage that treats any of them as unqualified national or pan-European triumphs is doing structural disservice to the strategic discourse. Each project’s published findings — including the inconvenient ones — should anchor the public narrative.
- The July 2026 moment is when the structural comparison becomes data-grounded for the first time. Two years of speculation about European sovereign-LLM development converge to operational artifacts that can be empirically evaluated. The strategic discourse should be ready for whatever the data actually shows.
OpenEuroLLM is one valid answer. AMÁLIA is another. Minerva is a third. Mistral is potentially a fourth — the commercial-frontier answer that I’ll examine in the next standalone essay in this track. The strategic discourse benefits from treating all of them as complementary experiments in the same empirical question: what does it actually cost to develop frontier-capability AI within European institutional and regulatory constraints, and what positioning produces results that justify the investment?
That’s the read on OpenEuroLLM as of mid-May 2026. The work is substantial. The institutional infrastructure contribution is durable and important. The compute bottleneck is the binding structural constraint. The July 2026 first models will determine which strategic-positioning combination the project ultimately stakes — and that determination matters for every subsequent European sovereign-AI initiative.
The questions are real. The answers are still being determined. More analysis like this is needed across every European sovereign-LLM project. Not less.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Related Reading · the European sovereign-LLM essay track
- AMÁLIA · The Three Hard Questions — Standalone Essay 01, the Portuguese case study (continuation pre-training answer)
- Minerva · The Opposite Path — Standalone Essay 02, the Italian case study (from-scratch national investment answer)
- This piece — Standalone Essay 03, the OpenEuroLLM case study (pan-European consortium answer)
- Coming next · Mistral · the commercial-frontier answer
Sources
- OpenEuroLLM official project page · partner list, goals, status
- OpenEuroLLM deliverables roadmap · 11-deliverable timeline through January 2028
- OpenEuroLLM blog · year-one operational output documentation
- OpenEuroLLM: First year progress and next steps · March 6, 2026 · the Hajič compute statement
- Launch press release · February 3, 2025 · full partner list
- Strategic access to EuroHPC resources granted to OpenEuroLLM · December 12, 2025 · four-supercomputer allocation
- Open-sci and OpenEuroLLM release of reference models · August 22, 2025 · open-sci-ref 0.01
- Release of 38 Monolingual 2.15B LLMs Trained on HPLT v2 · July 17, 2025
- MultiSynt: Advancing Multilingual AI Through Open Synthetic Training Data · May 27, 2025 · 3M GPU hours on Leonardo BOOSTER
- OpenEuroLLM secures compute on the LUMI Supercomputer · May 26, 2025 · 1.5M GPU hours
- MultiSynt AI Factory Leonardo page · four-phase synthetic data methodology
- TechCrunch · Open source LLMs hit Europe’s digital sovereignty roadmap · Hajič interview, Mistral absence, budget breakdown, Stasenko critique
- Fortune · OpenEuroLLM project works to develop AI models for European languages · €37.4M vs $100B Stargate comparison
- European Commission · A pioneering AI project awarded for opening Large Language Models to European languages · February 3, 2025 · STEP Seal award
- ComplexDiscovery · OpenEuroLLM Initiative Signals EU’s Transition from Regulation to AI Innovation · February 6, 2025
- HPCwire · OpenEuroLLM Awarded STEP Seal · February 3, 2025
- Mischa Dohler · OpenEuroLLM Project Fuels Europe’s Digital Sovereignty · 35-language target detail
- Blicio · OpenEuroLLM: A Bold Step Towards Europe’s Digital Sovereignty · Silo AI / AMD acquisition context
- News9live · Europe’s First Big AI Chatbot! OpenEuroLLM Aims to Compete with ChatGPT & DeepSeek
- MixtureVitae arXiv 2509.25531 · permissive open web-scale pre-training dataset
- HPLT/hplt-20-monolingual-reference-models · 38 monolingual reference models
- MultiSynt/MT-Nemotron-CC · first comprehensive multilingual synthetic pre-training dataset
- OpenEuroLLM training-data-catalogue GitHub · vetted datasets on LUMI / Leonardo / MareNostrum
- Jan Hajič · Charles University · Institute of Formal and Applied Linguistics (ÚFAL) · OpenEuroLLM coordinator · HPLT project coordinator since 2022
- Peter Sarlin · AMD Silo AI · CEO/co-founder · OpenEuroLLM co-lead · Silo AI acquired by AMD for $665M in 2024
- Anastasia Stasenko · Pleias · co-founder · published skepticism about consortium decision-velocity
- Grant agreement No 101195233 · EU Digital Europe Programme · OpenEuroLLM funding
- STEP (Strategic Technologies for Europe Platform) Seal · first Digital Europe Programme project to receive it
- EuroHPC AI Factory Large Scale call EHPC-AIF-2025LS01-028 · 3M GPU hours Leonardo BOOSTER (MultiSynt)
- Finnish LUMI Extreme Scale Access program · 1.5M GPU hours
- EU AI Act · effective February 2, 2025 · regulatory framework OpenEuroLLM is designed to comply with
- Nemotron-CC arXiv 2412.02595 · Nvidia methodology underlying MultiSynt
- LAION, Open-sci, OpenML · collaborating open-source/open-science communities
- EuroLLM technical report · the project’s relationship to existing European multilingual model work
- Common Crawl · primary open-data source per Hajič TechCrunch interview







