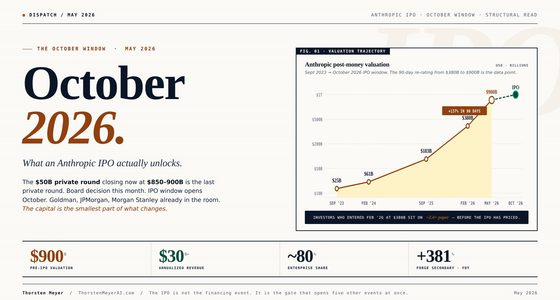
A fair, analytical teardown of the AI infrastructure leader — plus what to watch next.
Core thesis: NVIDIA isn’t “winning AI” because it sells fast GPUs. It’s winning because it controls multiple control points across the AI compute stack — software, systems, networking, and supply chain. NVIDIA Investor Relations+1
Core tension: the same choices that compound advantages also create concentration, dependency, and expectations risk. NVIDIA Investor Relations
Executive summary
- NVIDIA’s “product” is increasingly a repeatable AI factory blueprint: GPUs + interconnect + networking + software + deployment patterns, distributed through clouds/OEMs. NVIDIA Investor Relations+1
- It compounds because revenue scale enables faster iteration (architectures, packaging, networking, software), which attracts developers and buyers, which increases revenue scale again. NVIDIA Investor Relations+1
- The moat is less “FLOPS” and more time-to-value: CUDA, libraries, compilers, comms, and validated reference systems that reduce deployment risk. NVIDIA Developer Download+1
- Vulnerabilities cluster around hyperscaler bargaining power, foundry/packaging chokepoints, geopolitics/export controls, and inference standardization (cost-per-token pressure + more standardized networking). NVIDIA Investor Relations+1

The AI Data Center Engineering Handbook: Designing High-Performance GPU Clusters, AI Networks, and Scalable Cloud Infrastructure
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
1) NVIDIA’s business model: selling the “standard rack,” not a chip
At this stage, NVIDIA’s unit of value is closer to a rack-scale system than a single accelerator. In Q3 FY2026, NVIDIA reported record revenue of $57.0B and record Data Center revenue of $51.2B, underscoring how dominant the Data Center platform has become. NVIDIA Investor Relations
A key strategic point: Data Center isn’t just “GPU compute.” NVIDIA explicitly frames it as compute + networking, which is how a component vendor becomes a platform vendor. Q4 Capital+1
Annotated screenshot: Data Center mix (compute + networking)
Strategic implication: once the purchase includes GPUs and NICs/switches/fabric, customers aren’t just switching silicon — they’re switching an entire performance + operations stack. Q4 Capital+1

NVIDIA Jetson AGX Orin 64GB Developer Kit with Ethernet, USB, Display Port
- Compact AI Development Kit: Easy to start with Jetson Orin
- High AI Performance: Up to 275 TOPS of AI power
- Includes 64GB Module: Supports complex AI models
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
2) The flywheel that makes NVIDIA hard to catch
NVIDIA compounds because multiple loops reinforce each other:
- More performance + better developer UX → more workloads land on NVIDIA.
- More workloads → more revenue + more deployment feedback.
- More revenue → more R&D + better supply-chain leverage.
- Better supply position → faster ramps + better availability.
- Availability + performance → more design wins (repeat).
This is why NVIDIA communications emphasize platform shifts and long-range “visibility” language: it’s an attempt to turn an adoption surge into a multi-year planning cycle for customers (and investors). Q4 Capital+1
Annotated screenshot: revenue scale + the expectations problem
Fair (non-doomer) critique: the bigger the narrative, the more volatility you get when reality becomes “less extraordinary.” Great companies can still experience rough periods when expectations are priced for perfection. NVIDIA Investor Relations+1

INFINIBAND FOR HIGH-PERFORMANCE COMPUTING AND AI CLUSTERS: Configure RDMA networking, optimize GPU interconnects, and build low-latency infrastructure for distributed training and HPC workload
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
3) What actually keeps customers from switching
Moat A: Software as the primary control point
CUDA matters less as a brand name and more as a compatibility + productivity layer: driver/ISA abstraction + language/tool integration reduces friction and protects existing code investments. NVIDIA Developer Download
Annotated screenshot: where the control point sits
Why this is sticky in practice: switching isn’t just “port code.” It’s retuning kernels, debugging performance regressions, retraining teams, revalidating models, and rewriting deployment playbooks — all of which are time, risk, and organizational inertia. NVIDIA Developer Download
Moat B: Systems-level performance (interconnect + comms)
In multi-GPU training, interconnect and collective comms can matter as much as the accelerator. NVIDIA has invested in scale-up fabrics (NVLink/NVSwitch) and system blueprints designed for cluster-scale use. Advanced Clustering Technologies
Annotated screenshot: why “system” beats “SKU”
Strategic takeaway: competing with NVIDIA often means competing with a system, not a SKU. A “faster chip” that’s painful to scale, integrate, and operate often loses to a slightly slower solution that ships as a predictable, repeatable deployment pattern. Advanced Clustering Technologies
Moat C: Supply chain as strategy (availability is a feature)
When demand spikes, the “best chip” is frequently the one you can actually deploy. NVIDIA’s filings describe substantial inventory purchase and long-term supply/capacity obligations, indicating that securing supply is treated as strategic.
Annotated screenshot: capacity commitments as a double-edged sword
Trade-off: this can protect supply during shortages — but creates downside exposure if demand cools or the mix shifts faster than commitments can be adjusted.

NVIDIA MSN2700-CS2FC Spectrum 100GbE 1U Open Ethernet Switch
- Reliable Data Center Networking: Predictable and affordable network performance
- Vendor Flexibility: No vendor lock-in options
- High Data Integrity: Zero packet loss for reliable transmission
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
4) Where NVIDIA is vulnerable (pressure points, not predictions)
This isn’t “NVIDIA is doomed.” These are conditional vulnerabilities: they matter if certain market shifts occur.
1) Hyperscaler concentration and bargaining power
A meaningful share of spend sits with a small set of buyers who:
- negotiate hard,
- can multi-source over time,
- and increasingly build internal silicon and/or system architectures.
Even if NVIDIA remains the performance leader, buyer power can compress margins or shift value capture toward integrators and cloud services.
2) Foundry + advanced packaging chokepoints
NVIDIA is fabless, which means leading-edge manufacturing and advanced packaging remain potential bottlenecks. The emphasis on supply and long-term commitments is a tell: availability is strategic. NVIDIA Investor Relations
3) Geopolitics / export controls
AI accelerators are now geopolitical assets. Export controls, compliance overhead, and market access constraints can reshape TAM, mix, and product planning. NVIDIA Investor Relations
4) Inference may standardize faster than training
Training rewards tightly coupled, high-performance systems. Inference at scale can reward:
- cost per token,
- power efficiency,
- operational simplicity,
- and more standardized networking.
If the market shifts toward “good-enough inference everywhere,” NVIDIA’s premium can face pressure — unless it keeps extending software + systems advantage.
5) Portability layers are improving
The center of gravity is gradually moving from “write CUDA” to “deploy a runtime that targets everything.” If runtimes/compilers/frameworks stay effectively hardware-agnostic, CUDA’s lock-in weakens at the margin.
6) Power, cooling, and deployment constraints
Often the bottleneck is not GPUs but power, cooling, real estate, and build-out speed. If customers can’t build fast enough, demand becomes lumpy and planning becomes harder.
7) Scrutiny and platform risk
Once you’re the default standard, you attract regulatory pressure and ecosystem pressure for openness, pricing clarity, and escape hatches.
5) Leading indicators to watch
If you want to track NVIDIA’s strength without getting lost in hype, watch:
- Data Center mix: compute vs networking growth (platform breadth vs “just GPUs”). Q4 Capital+1
- Gross margins: buyer power/competition usually shows up here first (Q3 FY2026 gross margin disclosed in the press release). NVIDIA Investor Relations
- Evidence of multi-sourcing: portable runtimes, heterogeneous clusters, “runs well on X/Y/Z” messaging.
- Time-to-deploy signals: lead time/backlog language and customer build-out pace.
- Workload shift: training-heavy vs inference-heavy spend (inference pushes harder on cost efficiency).
6) If you’re competing with NVIDIA: three realistic plays
- Win a narrow beachhead with brutal clarity
Pick one workload + one buyer segment where you can offer a step-change in TCO + operability (not just FLOPS). - Be the unbundler
Attack portability and developer experience: compilers, runtimes, profiling, kernel libraries, deployment tooling — the parts that make switching feasible. - Compete at the system layer with open standards
If you can’t beat NVIDIA’s proprietary fabric, offer a standardized alternative that’s “good enough” and easier to procure and operate at scale.