
By Thorsten Meyer — May 2026
The Memento Constraint dispatch earlier in this series argued that the gap between human continual learning and frontier-LLM continual learning is the single most important architectural bottleneck for genuinely autonomous agentic AI. Six months later, the empirical picture is clearer. The bottleneck is real. The research community is converging on the problem from five distinct architectural directions. None of the directions has produced a production-ready solution. The honest timeline for genuinely-continual frontier AI deployment is 2028-2030 for the first broken versions, 2030+ for reliable production deployment.
This dispatch is the technical reference companion to the original Memento piece. The point is not to argue the constraint matters — the original dispatch covered that. The point is to map where the research is, what each approach does well and badly, what timeline expectations are realistic, and what production-deployment patterns work today as approximations of continual learning even though the genuine version is still years out.
The dispatch on the agentic loop failure modes covered how 20-100 step agentic systems fail in production. Memory pollution and non-Markovian reasoning failures from that taxonomy are direct manifestations of the continual learning constraint. The dispatch on the China Sphere capability gap noted that Western frontier labs maintain durable advantage on generalization to genuinely unseen tasks. Both observations connect: the labs that solve continual learning first capture the most consequential capability advantage of 2027-2030.
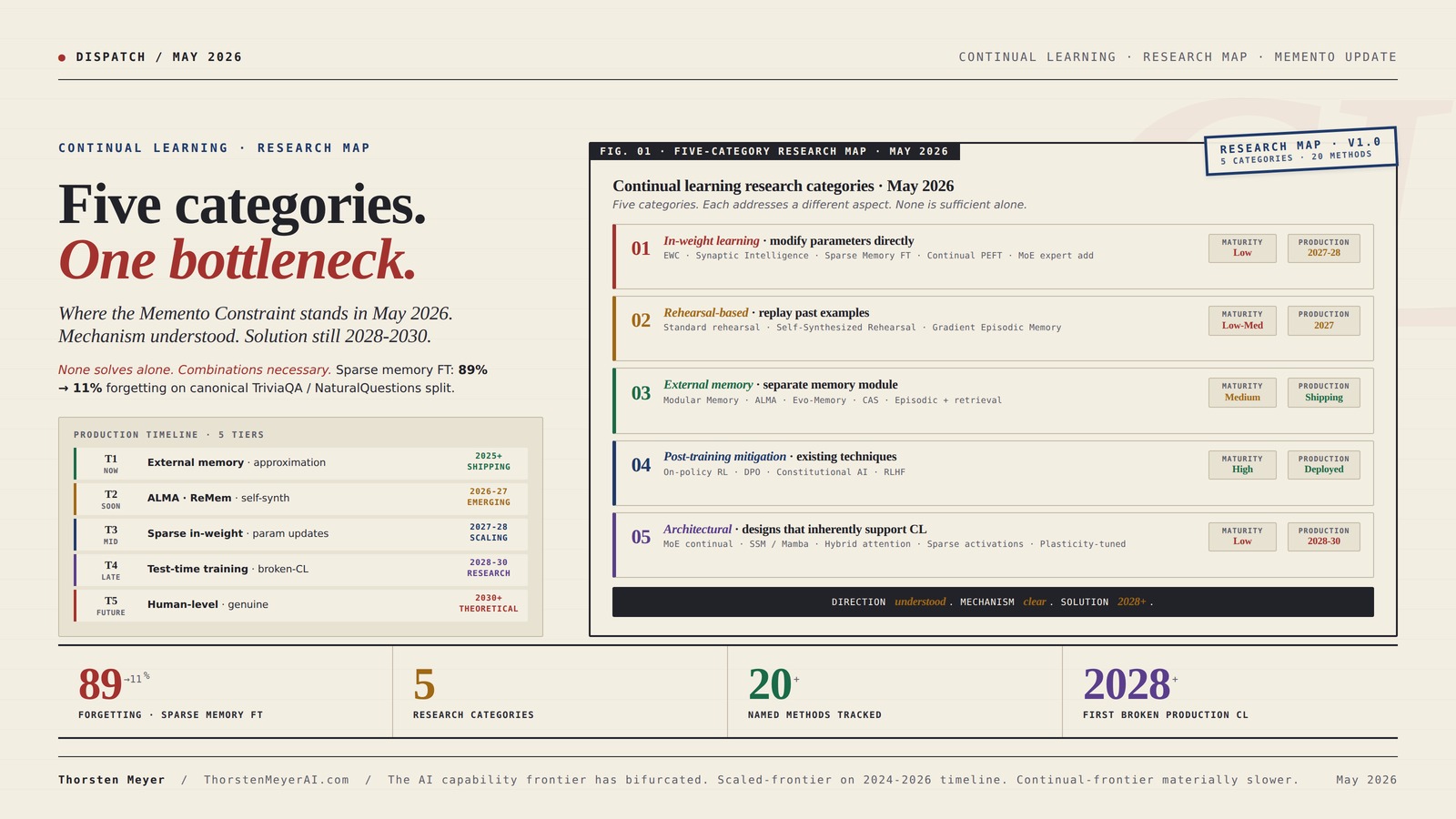
Five categories. One bottleneck.
Where the Memento Constraint stands in May 2026. Mechanism understood. Solution still 2028-2030.
In-weight learning · rehearsal-based · external memory · post-training mitigation · architectural. None solves the problem alone. Combinations are necessary. Sparse memory fine-tuning produced the most promising recent result: 89% forgetting → 11% on the canonical TriviaQA / NaturalQuestions split.
Five categories. Twenty methods. Where the research stands.
Each category addresses a different aspect of the continual learning problem. None is sufficient alone; combinations are necessary. External memory is most production-mature; sparse memory fine-tuning is the most promising emerging result.

Literacy Beginnings: A Prekindergarten Handbook
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Five tiers. Five timelines.
Honest assessment of when each tier of continual learning capability reaches production deployment. Sholto Douglas-Trenton Bricken framing applies: broken early versions before genuine versions.
Deployed
at scale
Emerging
+ early prod
Emerging
scaling up
First versions
research
Possibly 32-35
+ research

ESP32-S3 AI Smart Speaker Development Board, Dual Microphones, Noise Reduction&Echo Cancellation, RGB Lighting, ESP32 Audio, Support Connect External Displays & Cameras, Support AI Speech Interaction
Adopts ESP32-S3R8 module with Xtensa 32-bit LX7 dual-core processor, up to 240MHz main frequency. Supports 2.4GHz Wi-Fi (802.11…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Different labs. Different strategies.
No lab is dominantly leading on continual learning. Capability is being developed in parallel across multiple research programs. The lab that wins durable CL advantage by 2028-2030 will combine multiple approaches.
The AI capability frontier has bifurcated. On dimensions that scale with parameters and compute, the frontier advances on the 2024-2026 timeline. On dimensions that require architectural breakthrough, the timeline is materially slower.

MOOG Theremini – Theremin with Pitch Correction, CV Out, Built-In Tuner and Speaker, AniMOOG Synthesizer Sound Engine with 32 Presets and LCD Screen
Get Started with Ease – Great for beginners or experienced musicians, Theremini's assistive pitch correction allows each player…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Four assignments. By role.
Continue the multi-approach strategy.
No single category will solve continual learning; combinations are necessary. Sparse memory fine-tuning is the most promising recent in-weight result; integrate with external memory and post-training RL. Publish methodology so the community can reproduce. The lab that ships first credible continual learning at frontier scale captures durable capability advantage.
Treat external memory as approximation, not solution.
Plan for memory pollution to compound over deployment time. Implement memory hygiene (periodic summarization, retrieval-quality monitoring, hierarchical memory) as default operational practice. Do not rely on production agents to “learn” from deployment in any meaningful sense — they cannot, yet. Hierarchical memory is the production hedge against the 2030 timeline.
Submit to FMAI / FAGEN.
Continue work on sparse memory fine-tuning at scale — most promising in-weight direction. Develop consolidated continual learning benchmark suites; current fragmentation slows community progress. Mechanistic understanding (Jan 2026 paper and follow-on work) is the foundation for targeted interventions.
Treat CL as 2028-2030 capability.
First broken versions 2028-2030; reliable production 2030+. Do not factor genuine continual learning into 2026-2027 strategic plans; do factor it into 2028-2030 plans. The lab that ships first will capture meaningful market-share advantage; bet accordingly. The bifurcation between scaled-frontier and continual-frontier capability is the structural fact to absorb.
AI memory augmentation devices
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Executive Summary · The Five-Category Research Map
| Category | Key methods | Best result so far | Production maturity | Timeline to production |
|---|---|---|---|---|
| In-weight learning | EWC · SI · Sparse Memory FT · Continual PEFT | 89% drop → 11% drop with sparse memory FT | Low | 2027-2028 (limited) |
| Rehearsal-based | Standard rehearsal · SSR · GEM | Strong on small-scale; cost-prohibitive at frontier scale | Low-medium | 2027 (small models) |
| External memory | ALMA · Evo-Memory · CAS · Modular Memory | Most production-deployed approximation today | Medium | Already shipping (limited) |
| Post-training mitigation | On-policy RL · DPO · Constitutional AI | Natural CL mitigation through existing techniques | High (existing) | Already deployed |
| Architectural | MoE continual · SSM hybrid · sparse activations | Promising but early; structural rather than fix | Low | 2028-2030 |
Five distinct research directions. Each addresses a different aspect of the continual learning problem. None is sufficient alone; combinations are necessary. The honest assessment: the next-generation frontier models (Opus 5, GPT-6, Gemini 3.5 Pro) will likely combine sparse memory fine-tuning, external episodic memory, and post-training RL refinement to produce a meaningfully improved approximation of continual learning. None of them will be human-level continual learners by 2027. The genuine version is 2028-2030.
1. The constraint, restated
Continual learning is the ability of a model to acquire new knowledge over time without forgetting prior knowledge, and to dynamically adapt existing knowledge to align with novel situations. The contrast with current frontier LLMs is sharp. Frontier models are trained once, frozen at deployment, and updated only through periodic full retraining cycles that cost hundreds of millions of dollars and take months to complete. Between training cycles, the models cannot learn — they can only retrieve from their existing parametric knowledge or from external memory systems that the inference layer queries.
The mechanistic problem was identified in 1989 by McCloskey and Cohen and described as catastrophic interference. French formalized the framework in 1999. The pattern: training a neural network on new data degrades performance on previously learned tasks at a rate roughly proportional to the new training data’s distance from the old data distribution. The further the new task is from the old, the worse the forgetting.
Modern frontier LLMs exhibit catastrophic forgetting acutely. The January 2026 mechanistic analysis paper (Llama 4 Scout, Maverick, GPT-5.1, Claude Opus 4.5, Gemini 2.5 Pro, DeepSeek-V3.1) documented forgetting rates that vary by architecture but reach catastrophic levels (40-80% performance degradation on prior tasks) under standard continual fine-tuning protocols. The Sparse Memory Finetuning paper from October 2025 produced one of the cleanest contemporary demonstrations: training on TriviaQA facts produced an 89% drop in NaturalQuestions performance with full fine-tuning, 71% drop with LoRA, and only 11% drop with sparse memory fine-tuning. Same model, same data, three orders of magnitude difference in forgetting based on the training method.
This is the constraint. It is real, mechanistically understood at increasing depth, and it is the primary obstacle to AI systems that learn from production deployment the way human professionals learn from job experience.
2. Category 1 · In-weight learning approaches
The most direct approach: modify the model’s parameters in ways that incorporate new knowledge without overwriting old.
Method 1 · Elastic Weight Consolidation (EWC). Kirkpatrick et al. 2017. The method computes Fisher information to identify which parameters were important for previous tasks, then penalizes large updates to those parameters during new-task training. Effective for small-scale demonstrations. Scales poorly to frontier-LLM parameter counts because the Fisher information matrix becomes computationally prohibitive at trillion-parameter scale. Production maturity: low for frontier models, medium for sub-10B models.
Method 2 · Synaptic Intelligence (SI). Zenke et al. 2017. Computes path integrals of gradient × parameter update during training, accumulating an importance signal that approximates EWC at lower computational cost. Better-scaling than EWC but still produces meaningful overhead at frontier scale. Production maturity: limited.
Method 3 · Sparse Memory Fine-tuning. Recent (October 2025-2026 work). Identifies a small subset of “memory layers” within the model and confines fine-tuning updates to those layers only. The 89% → 11% forgetting drop on TriviaQA-vs-NaturalQuestions noted above is the headline result. The architectural insight: sparsity is a key ingredient for continual learning. Production maturity: emerging — early-stage tooling, promising results, not yet integrated into production frontier deployments.
Method 4 · Continual Parameter-Efficient Fine-Tuning (PEFT). Variants of LoRA and prefix-tuning adapted for sequential task learning. Each new task gets its own LoRA adapter; the base model is frozen. Production maturity: medium — already widely deployed for task-specific customization in production but does not solve the fundamental continual learning problem because it requires explicit task boundaries and adapter switching, which is not how human continual learning works.
Method 5 · Mixture-of-Experts continual updates. Add new experts to a MoE model for new domains; route relevant queries to the new experts. Approach used implicitly in some Chinese frontier models (DeepSeek V4, Qwen 3.6). Production maturity: emerging — the architectural approach is established but the continual-update protocols are still being developed.
The in-weight learning category is the most direct theoretical approach to continual learning but the most difficult to scale. The sparse memory fine-tuning result is the most promising recent development; if it generalizes from small-model demonstrations to frontier-scale deployment, it will be a meaningful production capability by 2027-2028.
3. Category 2 · Rehearsal-based approaches
Replay past examples while training on new ones. The approach borrows from biological memory consolidation.
Method 6 · Standard rehearsal. Maintain a buffer of past training examples and interleave them with new training. Effective when the buffer can capture enough variance from past tasks. Cost-prohibitive at frontier scale because the buffer would need to be substantial fractions of the original training data, and replay through the full buffer would dominate compute. Production maturity: low for frontier scale.
Method 7 · Self-Synthesized Rehearsal (SSR). Recent work (Huang et al. 2024, refined through 2026). The model generates its own rehearsal examples by inferring from the previous-task input distribution. Eliminates the need for stored real data and reduces compute substantially. Not yet at frontier-scale demonstration but promising results on mid-size models. Production maturity: emerging.
Method 8 · Gradient Episodic Memory (GEM). Lopez-Paz and Ranzato (FAIR) 2017. Stores a small number of examples per task and ensures that gradients on new-task training do not increase loss on stored examples. The stored examples are “memories” that constrain new learning. Strong theoretical foundation; scales to mid-size models; computational cost grows linearly with task count, which becomes prohibitive over many tasks. Production maturity: limited.
The rehearsal-based approaches share a common limitation: they require either substantial storage (real data buffer) or substantial inference compute (synthesized data). Both costs grow with deployment time, which creates a fundamental scaling problem. For frontier models intended to be continually deployed for years, the rehearsal cost dominates training cost over time.
4. Category 3 · External memory approaches
Separate the memory function from the model parameters. Use external retrieval systems for long-term storage; reserve parameters for skills and reasoning.
Method 9 · Modular Memory architectures. Dagstuhl seminar (October 2025) framing — separate “in-weight learning” (parametric updates) from “external memory” (retrievable storage). The seminar’s published framing in March 2026 argued that “modular memory is the key to continual learning agents.” Production maturity: high — most current production agentic systems already implement some version of this through retrieval-augmented generation (RAG) and vector databases.
Method 10 · ALMA (Automated meta-Learning of Memory designs for Agentic systems). Xiong, Hu, Clune (February 2026). Meta-learns the memory design itself rather than hand-crafting it. Memory designs expressed as executable code; a Meta Agent searches over the design space. Applicable across four sequential decision-making domains in the published evaluation. Production maturity: research stage — promising but early.
Method 11 · Evo-Memory benchmark. November 2025 evaluation of 10+ memory modules across 10 datasets. Includes ExpRAG (retrieval-based experience reuse) and ReMem (action-think-memory refine pipeline). Production maturity: benchmarking infrastructure is mature; specific methods range from established (ExpRAG-style retrieval is widely deployed) to research-stage.
Method 12 · Temporal Memory / Compress-Add-Smooth. Chertkov, April 2026. Memory as a Bridge Diffusion stochastic process. Recursive compression and smoothing of past experience under fixed memory budget. Production maturity: research stage — mathematical framework is novel, demonstration scale is small.
Method 13 · Episodic memory with retrieval. The widely-deployed pattern. Production agents store episode-level summaries of customer interactions, decisions made, outcomes observed; retrieve relevant episodes when similar situations arise. Cursor’s memory feature, Claude Code’s project memory, and similar systems implement this approximately. Production maturity: high — already deployed at scale.
The external memory category is the most production-mature of the five. Most agentic systems shipping today implement some version of external memory + retrieval as the operational approximation of continual learning. The approximation has substantial limitations — retrieval is imperfect, the model’s parametric knowledge does not actually update from production experience, and the memory pollution problem from the agentic failure modes taxonomy compounds over deployment time. But it is what works in production today.
5. Category 4 · Post-training mitigation
Leverage existing post-training techniques (RLHF, DPO, Constitutional AI) as natural mitigation for catastrophic forgetting.
Method 14 · On-policy reinforcement learning. Wolfe’s 2026 analysis argues that on-policy RL — where the model generates its own training data through sampling and the training signal comes from rewards — naturally mitigates catastrophic forgetting because the model is constantly re-sampling its own behavior distribution. The training data does not drift away from the model’s current capability; it adapts with the model. Production maturity: high — RLHF and its variants are the dominant post-training technique at all major labs.
Method 15 · Direct Preference Optimization (DPO). Rafailov et al. 2023. Avoids the explicit reward model of RLHF by directly optimizing on preference data. Less prone to reward hacking than full RLHF. Used at multiple major labs. Production maturity: high.
Method 16 · Constitutional AI. Anthropic’s framework. The model generates and revises its own outputs against constitutional principles, producing training data that aligns with intended behavior. Production maturity: high at Anthropic; influence on other labs varies.
The post-training mitigation category is not a solution to continual learning — it is a partial mitigation that emerges naturally from existing techniques. The implication: every major lab is already partially addressing catastrophic forgetting through their post-training pipeline. The next-generation models will likely formalize and extend this approach, producing meaningfully improved continual learning behavior even without architectural breakthroughs.
6. Category 5 · Architectural approaches
Designs that inherently support continual learning rather than adding it as a post-hoc fix.
Method 17 · Mixture-of-experts with continual expert addition. Add new experts to a MoE model for new domains. Route queries to relevant experts. The experts can be added without disrupting prior expert weights. DeepSeek V4’s 1.6T parameter MoE flagship and Qwen 3.6’s 35B-A3B variant are examples of MoE architectures that could support this approach in principle, though the continual-update protocols are still being developed. Production maturity: emerging — architecture is established, continual-update protocols are research stage.
Method 18 · State space models / Mamba / hybrid attention. Linear-time sequence processing rather than quadratic attention. Maintains a fixed-size state that updates as new information arrives. Architecturally more aligned with biological memory consolidation than pure transformer attention. From the agentic failure modes dispatch — early-stage for production agent deployments, but the architectural direction is clear. Production maturity: low for production deployments; research is active.
Method 19 · Sparse activation networks. Networks where only a fraction of parameters activate for any given input. Reduces interference between tasks because different task distributions activate different parameter subsets. Connects to the sparse memory fine-tuning approach. Production maturity: emerging.
Method 20 · Neural plasticity-inspired architectures. Designs that include explicit “plasticity” parameters that modulate how much a given parameter can change. Inspired by biological synaptic plasticity. Production maturity: research stage.
The architectural category is the most theoretically promising but the least production-ready. Architectural changes require new pre-training runs at frontier scale, which is enormously expensive. Labs adopt new architectures slowly; the conservative approach is to layer continual learning techniques on top of established architectures rather than redesigning from the ground up. The implication: architectural breakthroughs in continual learning will arrive but on the 2028-2030 timeline rather than sooner.
7. The lab-by-lab strategic position
Different labs are pursuing different approach combinations. The strategic positioning matters for downstream production deployment.
DeepMind. Strongest historical position. Hadsell et al. (2020) framed the stability-plasticity tradeoff as the core CL problem. Long-running research program through DeepMind/Brain merger. Public emphasis on episodic memory and meta-learning. Likely positioning: external memory + post-training mitigation + selective in-weight updates.
Meta / FAIR. Lopez-Paz and Ranzato originated GEM (2017). Strong open-research culture. Llama 4 Scout and Maverick are MoE architectures that could support continual expert addition. Likely positioning: in-weight learning emphasis + open-source contribution to community methods.
Anthropic. Sholto Douglas and Trenton Bricken on the Dwarkesh podcast (mid-2025) projected reliable computer-use agents by end of 2026. Constitutional AI provides natural CL mitigation through post-training. Likely positioning: external memory + post-training mitigation + Constitutional AI extensions. The JV with Blackstone-Goldman provides operational pipeline for testing CL approaches in mid-market production environments.
OpenAI. Strong RLHF and on-policy RL infrastructure. GPT-5.4 / 5.5 capability ceiling at the top of the Stanford AI Index benchmarks suggests post-training pipeline is mature. Likely positioning: post-training mitigation + RL-driven natural CL + episodic memory through ChatGPT memory feature.
Academic groups. Clune (UBC/Vector Institute), Hadsell (DeepMind/UCL), Grossberg (Boston University), and the Dagstuhl seminar attendees. Substantial independent research output. The Modular Memory framing came from this community. The ALMA approach came from the Clune group. Production-relevance varies.
Chinese labs. DeepSeek, Alibaba, Moonshot, Z.ai are MoE-heavy. The MoE architectural approach is well-positioned for continual expert addition. Open-weight licensing (GLM-5.1 MIT) makes Chinese-lab CL research available to the global community for fine-tuning and extension. Likely positioning: architectural approaches + post-training mitigation.
The cumulative picture: no lab is dominantly leading on continual learning specifically. The capability is being developed in parallel across multiple research programs with different strategic emphases. The lab that wins durable continual learning advantage by 2028-2030 will likely combine multiple approaches rather than commit to one.
8. The production-timeline reality check
Honest assessment of when continual learning capabilities will reach production deployment, by capability tier.
Tier 1 · External memory + retrieval (already deployed). Cursor’s memory, Claude Code’s project memory, ChatGPT’s memory feature, basic RAG with vector databases. Functional approximation of continual learning at the surface level. Limitations: retrieval imperfect, parametric knowledge static, memory pollution accumulates. Production status: 2025+, currently deployed.
Tier 2 · Improved external memory with self-synthesis (2026-2027). ALMA-style meta-learned memory designs, ReMem-style action-think-memory refine pipelines, ExpRAG-evolution. Better than current production but still bounded by parametric staticness. Production status: emerging through 2026-2027.
Tier 3 · Sparse in-weight updates (2027-2028). Sparse memory fine-tuning at frontier scale, continual PEFT integrated with deployment, periodic targeted parameter updates. The model’s parametric knowledge actually starts updating from production experience, but in limited and controlled ways. Production status: emerging through 2027-2028.
Tier 4 · Test-time training (2028-2030). Genuinely continual learning during deployment. The model adjusts its parameters in response to specific deployment experience. Sholto Douglas-Trenton Bricken framing: “broken early version of continual learning before we see something which truly learns like a human.” Production status: 2028-2030 for first broken versions.
Tier 5 · Human-level continual learning (2030+). The model learns from production deployment the way human professionals learn from job experience. Cumulative knowledge over years, dynamic adaptation, no catastrophic forgetting. Production status: 2030+, possibly 2032-2035 depending on whether breakthroughs accelerate the timeline.
The Dwarkesh framing from June 2025 — “I don’t see an obvious way to slot in continuous online learning into current models, 7 years is a long time” — remains the appropriate baseline expectation. Continual learning will arrive incrementally through 2026-2030, with each tier producing meaningful capability improvement but none of them being the breakthrough that solves the constraint. The genuine version is 5+ years out at minimum.
9. Three failure modes to track
The continual learning research has identified three structural failure modes that each approach must address.
Failure mode 1 · Catastrophic forgetting. The original problem. New training degrades performance on prior tasks. Mitigation: rehearsal, sparse updates, post-training RL, external memory. Tracked by: standard CL benchmarks (GLUE, TriviaQA, NaturalQuestions, domain-specific evaluations). Status: partial mitigation through sparse memory fine-tuning (89% → 11% on the canonical benchmark); not solved.
Failure mode 2 · Stability-plasticity tradeoff. Hadsell et al. 2020. A model that resists forgetting becomes too rigid to learn new things; a model that learns easily forgets too much. The tradeoff is fundamental rather than incidental. Mitigation: architectural designs that explicitly modulate plasticity per parameter or per layer. Status: actively researched; no clean solution.
Failure mode 3 · Memory pollution at scale. As external memory grows, retrieval quality degrades. The memory becomes large enough that the agent retrieves irrelevant experiences and acts on them. The mode connects to the agentic failure modes dispatch — memory pollution is one of the named failure modes there, and at the continual-learning scale it becomes structural rather than incidental. Mitigation: hierarchical memory, summarization layers, retrieval-quality evaluation. Status: actively researched; production tooling is emerging.
The three failure modes are interdependent. Sparse memory fine-tuning addresses (1) but may exacerbate (2) by reducing plasticity. External memory addresses (1) but creates (3) at scale. Post-training RL addresses (1) and partially (2) but does not address (3). The combinatorial nature of the failure modes is why no single approach will produce production-ready continual learning; combinations are necessary.
10. The benchmark landscape
How continual learning capability is measured in 2026.
Benchmark 1 · GLUE-CL and SuperGLUE-CL. Sequential task learning across NLU benchmarks. Tests forgetting rate on prior tasks while training on new. Established benchmark; produces reproducible results. Limitation: narrow capability scope.
Benchmark 2 · TriviaQA / NaturalQuestions split. The canonical pair for testing knowledge-domain forgetting. The 89% / 71% / 11% headline numbers from the sparse memory fine-tuning paper come from this evaluation. Limitation: knowledge-only, doesn’t test reasoning or planning.
Benchmark 3 · Evo-Memory benchmark suite. November 2025. 10+ memory modules across 10 datasets. Tests test-time learning capability across multi-turn goal-oriented tasks. Limitation: emerging benchmark; not yet community standard.
Benchmark 4 · Sequential agentic tasks (ALMA evaluation). Four sequential decision-making domains. Tests agentic continual learning specifically. Limitation: narrow domain coverage.
Benchmark 5 · Long-horizon-task reliability. METR Task Complexity Analysis (January 2026) and follow-on work. Doubles task horizon and measures reliability degradation. Indirect measure of continual learning at the task level. Limitation: indirect signal.
The benchmark landscape is fragmented. No single benchmark captures continual learning capability comprehensively. Researchers and labs use different benchmarks based on what they’re optimizing. This produces some of the cross-paper comparison difficulty in the literature. The community needs a consolidated benchmark suite by 2027-2028 to properly track progress.
What to Do This Quarter
1. AI labs. Continue the multi-approach strategy. No single category will solve continual learning; combinations are necessary. Sparse memory fine-tuning is the most promising recent in-weight result; integrate it with external memory and post-training RL. Publish methodology so the community can reproduce. The lab that ships first credible continual learning at frontier scale captures durable capability advantage.
2. Production deployment teams. Treat current external-memory + retrieval as approximation, not solution. Plan for memory pollution to compound over deployment time. Implement memory hygiene (periodic summarization, retrieval-quality monitoring, hierarchical memory) as default operational practice. Do not rely on production agents to “learn” from deployment in any meaningful sense — they cannot, yet.
3. Researchers. Submit to ICML 2026 FMAI/FAGEN workshops on failure modes. Continue work on sparse memory fine-tuning at scale — this is the most promising in-weight direction. Develop consolidated continual learning benchmark suites; the current fragmentation slows community progress. Mechanistic understanding (Jan 2026 paper and follow-on work) is the foundation for targeted interventions.
4. Strategic planners and forecasters. Treat continual learning as a 2028-2030 capability for first broken versions, 2030+ for reliable production. Do not factor genuine continual learning into 2026-2027 strategic plans; do factor it into 2028-2030 plans. The lab that ships first will capture meaningful market-share advantage; bet accordingly.
The Strategic Read
Continual learning is the most important architectural bottleneck for genuinely autonomous frontier AI, and it is being addressed across five distinct research directions. None of the directions has produced a production-ready solution as of May 2026. The most promising recent results — sparse memory fine-tuning at 11% forgetting vs 89% for full fine-tuning — demonstrate that meaningful progress is possible but require frontier-scale validation that has not yet occurred.
The five categories — in-weight learning, rehearsal-based, external memory, post-training mitigation, architectural — each address a different aspect of the problem. External memory is the most production-mature; current agentic systems already deploy approximations through RAG and vector databases. Post-training mitigation through RLHF and Constitutional AI provides natural partial mitigation. The other three categories are research-stage with emerging production paths.
The lab-by-lab strategic positions vary. DeepMind has the strongest historical research foundation. Meta/FAIR has the strongest open-research output. Anthropic combines external memory with Constitutional AI post-training. OpenAI emphasizes RLHF natural mitigation. Chinese labs lean architectural through MoE. No lab is dominantly leading; the capability is being developed in parallel.
The honest production timeline: external memory plus retrieval is already shipping (Tier 1). Improved external memory with self-synthesis arrives 2026-2027 (Tier 2). Sparse in-weight updates arrive 2027-2028 (Tier 3). Test-time training in broken-but-functional form arrives 2028-2030 (Tier 4). Human-level continual learning is 2030+ (Tier 5). The Sholto Douglas-Trenton Bricken framing — broken early versions before genuine versions — is the appropriate expectation.
Three structural failure modes (catastrophic forgetting, stability-plasticity tradeoff, memory pollution at scale) are interdependent. Each approach mitigates some at the cost of exacerbating others. The combinatorial nature is why no single method will produce production-ready continual learning; combinations are necessary, and combinations introduce engineering complexity that takes years to resolve.
The strategic implication for production deployment teams: do not rely on agents to “learn” from production in any meaningful sense through 2027. Plan operational practices around memory hygiene, hierarchical retrieval, and explicit re-training cycles. The capability arrives incrementally through 2026-2030; design systems that can absorb each tier as it ships rather than waiting for the breakthrough that solves the constraint.
The deeper signal: the AI capability frontier has bifurcated. On the dimensions that scale with parameter count and training compute (raw reasoning, knowledge, instruction-following), the frontier is advancing on the timeline established through 2024-2026. On the dimensions that require architectural breakthrough (continual learning, genuine agentic reliability, long-horizon planning), the timeline is materially slower. The 2030 gap between scaled-up frontier capability and genuinely-continual frontier capability is the structural fact that production strategy needs to absorb.
Continual learning research clusters into five categories. None solves the problem alone; combinations are necessary. External memory is production-mature; sparse memory fine-tuning is most promising emerging result; architectural breakthroughs are 2028-2030+. The Memento Constraint is structural, well-understood, and not going away soon.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Related Dispatches
- The Memento Constraint — continual learning bottleneck
- Agentic Loop Failure Modes — production taxonomy at year one
- The China Sphere Capability Gap Q2 Update — five labs, narrowing frontier
- Forward-Deployed Engineer Economics 2.0 — the unit economics math
- The Stanford AI Index 2026 Audit — reading the report card with a critic’s pen
Sources
- Mechanistic Analysis of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning (arxiv 2601.18699, January 2026) — six contemporary architectures evaluated
- Continual Learning via Sparse Memory Finetuning (arxiv 2510.15103, October 2025) — 89% / 71% / 11% forgetting comparison
- Modular Memory is the Key to Continual Learning Agents (arxiv 2603.01761, March 2026) — Dagstuhl seminar framing
- Learning to Continually Learn via Meta-learning Agentic Memory Designs (ALMA) — Xiong, Hu, Clune, February 10, 2026
- Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory (arxiv 2511.20857, November 2025)
- Temporal Memory for Resource-Constrained Agents: Continual Learning via Stochastic Compress-Add-Smooth — Chertkov, April 2026
- Continual Learning with RL for LLMs — Cameron Wolfe substack, January 2026
- Self-Synthesized Rehearsal — Huang et al. 2024, refined through 2026
- Gradient Episodic Memory — Lopez-Paz and Ranzato (FAIR), 2017 foundational
- Elastic Weight Consolidation — Kirkpatrick et al., 2017 foundational
- McCloskey & Cohen 1989 · French 1999 · catastrophic interference foundational papers
- Hadsell et al. 2020 · stability-plasticity tradeoff framing
- Dwarkesh interview with Sholto Douglas + Trenton Bricken · June 2025 · production timeline
- Continual Learning in Large Language Models: Methods, Challenges, and Opportunities (arxiv 2603.12658)







