
Outcome-First Decisions
A skill for AI agents that turns business uncertainty into proof, decisions, and action — fast. It doesn’t motivate. It doesn’t cheerlead. It asks for buyer evidence, picks one scoreboard number, and forces a written kill criterion before more time gets spent.


Algorithms for Decision Making
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What this skill actually does
Most “AI assistant” skills generate plans. Outcome-First Decisions rejects plans that lack a named buyer, a measurable scoreboard number, a 7-day proof test, and a kill criterion. If those are missing, the skill refuses to commit to a verdict and asks the smallest question that fills the gap.
The job, stated explicitly in the skill’s SKILL.md:
The skill’s job is not to motivate the user or make every idea sound promising. Its job is to help the user spend scarce attention on work that creates measurable business value, and to remove work that only feels productive.
Outcome-First Decisions — A Skill for AI Agents A skill for AI agents · Claude · Codex · Cursor Refuses
to motivate.A skill that turns business uncertainty into proof, decisions, and action — fast.
It doesn’t motivate. It doesn’t cheerlead. It asks for buyer evidence, picks one scoreboard number, and forces a written kill criterion before more time gets spent.
PMXBOARD – Kaizen Activity Summary Magnetic Card (2-Pack) – Reusable KPI Tracking & Project Closure Tool for Lean Six Sigma, CI Events & Team Boards | Dry-Erase Magnetic Whiteboard Accessory
Summarize Kaizen Event Results in One Place – Capture all final KPIs, improvement percentages, team details, and closure…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Most “AI assistant” skills generate plans. This one rejects them.
If a plan lacks a named buyer, a measurable scoreboard number, a 7-day proof test, and a kill criterion — the skill refuses to commit to a verdict and asks the smallest question that fills the gap.
From the SKILL.mdThe skill’s job is not to motivate the user or make every idea sound promising. Its job is to help the user spend scarce attention on work that creates measurable business value — and to remove work that only feels productive.
A buyer who pays today is more reliable than a hundred who say they would pay someday. Gold, Silver & Platinum Testing Magnet – Strong N52 with Brass Keychain – Precious Metal Test Tool
Contains 1 N52 Brass Keychain
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Every answer is six fields.
The same shape, every time. Predictable so the user can compare verdicts across decisions and across weeks.
response.shape
verdictWorth doing · Test first · Change · Defer · DropwhyThe business logic, in plain language.evidence_readStrongest and weakest parts of the case, mapped to the Buyer Evidence Ladder.proof_testThe smallest test that creates real evidence in1–7 days.thresholdsWhat result means keep, change, or kill.next_3_actionsSpecific actions for today or this week.Successful AI Product Creation: A 9-Step Framework
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
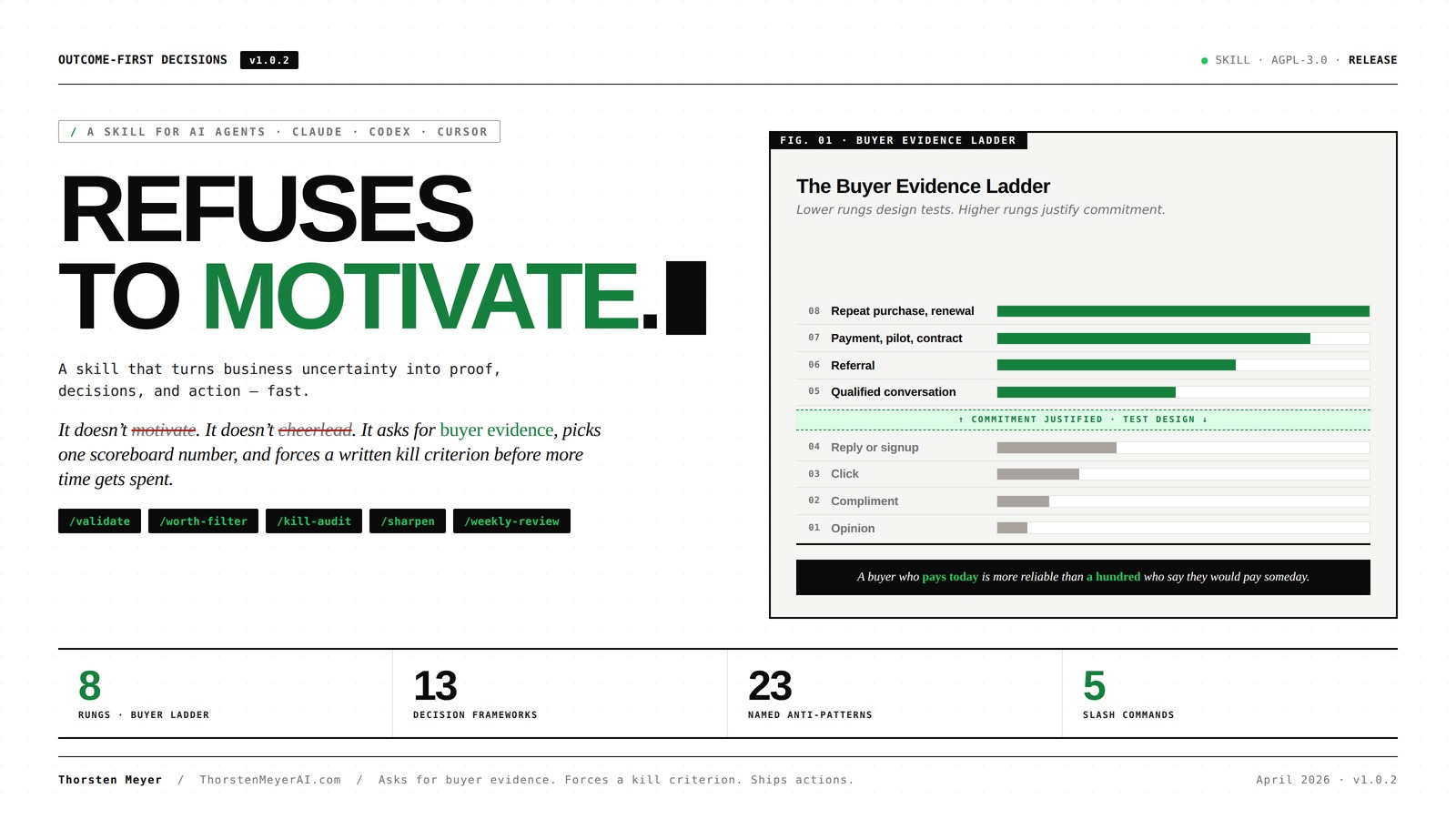
Every claim about demand sits on a rung.
Lower rungs design tests. Higher rungs justify commitment. The bar lengths are illustrative — the asymmetry is real. A paid customer is dramatically more reliable than an opinion.
01Opinionweak02Complimentweak03Clickweak04Reply or signupweak↑ Commitment justified · Test design ↓05Qualified conversationsignal06Referralstrong07Deposit, payment, signed pilot or contractstrong08Repeat purchase, retained usage, renewal, marginproofA buyer who pays today is more reliable than a hundred who say they would pay someday.Every answer must pass all five before it ships.
If any gate fails, the answer isn’t ready. The skill asks the smallest follow-up question that closes the gap — instead of papering over it with a plausible-sounding plan.
✓named_buyerNot a category (“freelance designers”). A segment specific enough to put 25 names on a list today.✓one_scoreboard_numberA single measurable metric — paid audits collected, replies booked, dollars deposited. Not three.✓7_day_proof_testA test that creates evidence on the ladder within 1–7 days. Anything longer is planning, not proof.✓written_kill_criterionThe exact result that means stop. Written before the test runs. No retroactive reframing.✓three_actions_todayThree specific actions for today or this week. Not strategies. Actions with verbs.If any gate is missing: the skill refuses to ship a verdict. It asks the smallest question that closes the gap — instead of generating a plausible plan around the hole.A founder asks. The skill doesn’t soften.
$ outcome-first-decisions · validateI want to build a SaaS that helps freelance designers manage client feedback rounds. Designers waste hours chasing approvals. I’m thinking about building it. Should I?Verdict Test firstdo not buildwhy“Designers waste hours chasing approvals” is a real-sounding problem. But the offer is unvalidated, the buyer is loosely defined (“freelance designers” is a category, not a segment), and there is no evidence any of them will pay to fix it. Building before a paid pilot is the most common failure path for solo SaaS — months of code, no buyer, no channel.
evidence_readStrongest: the friction is real (rung 1–2 — opinion + own observation). Weakest: no named buyer, no money on the table, no channel that reaches this buyer repeatedly. Currently rung 1.
proof_test · cash_proof_sprintA 14-day “approval-cycle audit” — review the buyer’s last 5 client projects, identify the cycles that lost time, give a one-page tightening plan.
$250, paid before. Direct outreach to 25 freelance brand designers billing $5k+ per project with 3+ active clients. 7 days.thresholds▲ Keep5+ paid audits ($1,250+ collected) · 2+ buyers ask “is there a tool for this?”↻ Change1–4 paid audits with consistent objections about workflow specifics. Reshape the offer.▼ Kill0 paid audits after 25 contacts. The pain isn’t painful enough to pay for. Capture the learning. Stop.next_3_actions · today
- Write the 25-name outreach list. Use Twitter/X bio search + LinkedIn.
- Write the 4-sentence outreach message ending with
“$250, paid before, reply by Friday.”- Send the first 5 messages today.
A package, not a prompt.
6+7Frameworks
- Worth Filter
- Cash Proof Sprint
- One Number Map
- Kill List Audit
- Buyer-Problem-Path
- Leverage Ladder
- +7 supporting
5Industry overlays
- SaaS
- Services / agency
- Creator
- E-commerce
- B2B
3+5Subskills + slash commands
- Buyer-conversation kit
- Decision journal · YAML schema
- Stuck-to-Shipped 7-day chain
- Calibration / blind-spot register
/validate/worth-filter/kill-audit/sharpen/weekly-reviewWhen the user mentions runway, the skill changes shape.
CRISIS MODEVerdict + 3 hour-level actions + dollar kill threshold.
The Worth Filter scoring tables and Evidence Ladder discussion are skipped. Output collapses to what can be acted on before tomorrow.
TRIGGER: “runway” · “payroll” · “lost biggest customer” · “weeks left”▸ verdict ▸ 3 actions · hour-level ▸ $ kill thresholdThree platforms. One package.
Distributed as
outcome-first-decisions.zip. AGPL-3.0. Compatible with Claude Code, Codex/OpenAI, and Cursor.▸ Claude Code# Claude Code mkdir -p ~/.claude/skills && unzip outcome-first-decisions.zip -d ~/.claude/skills/▸ Codex / OpenAI# Codex / OpenAI mkdir -p ~/.codex/skills && unzip outcome-first-decisions.zip -d ~/.codex/skills/▸ Cursor# Cursor mkdir -p ~/.cursor/skills && unzip outcome-first-decisions.zip -d ~/.cursor/skills/Then invokeUse the outcome-first-decisions skill to validate this idea.



How it answers
For most decisions, the skill answers in this shape:
- Verdict. Worth doing, test first, change, defer, or drop.
- Why. The business logic in plain language.
- Evidence read. Strongest and weakest parts of the case, mapped to the Buyer Evidence Ladder.
- Proof test. The smallest test that creates real evidence in 1–7 days.
- Keep / change / kill thresholds. What result means continue, adjust, or stop.
- Next three actions. Specific actions for today or this week.
Every answer is gated by a self-check protocol: named buyer / one number / 7-day proof / kill criterion / three actions. If any is missing, the answer is not yet ready.
The Buyer Evidence Ladder
Every claim about demand sits on a rung. Lower rungs design tests; higher rungs justify commitment.
- Opinion
- Compliment
- Click
- Reply or signup
- Qualified conversation
- Referral
- Deposit, payment, signed pilot, or signed contract
- Repeat purchase, retained usage, renewal, or margin improvement
A buyer who pays today is more reliable than a hundred who say they would pay someday.
What’s inside
- 6 core frameworks — Worth Filter, Cash Proof Sprint, One Number Map, Kill List Audit, Buyer-Problem-Path, Leverage Ladder.
- 7 supporting frameworks — Offer Sharpener, Sharp Ask Builder, Channel Bet Sheet, Price Integrity Check, Repeatability Test, Opportunity Cost Check, Weekly Decision Review.
- 23 named anti-patterns, 16 principles, 21 mental models, disambiguated.
- 5 industry overlays — SaaS, services / agency, creator, e-commerce, B2B.
- Buyer-conversation kit — cold-outreach templates, customer-interview guide, pre-sale ask language, objection-handling diagnostics.
- Decision journal with queryable YAML schema, weekly retrospective, prediction tracking, and a blind-spots register.
- Stuck-to-Shipped 7-day workflow chain for “I’m busy and nothing is moving.”
- Crisis Mode for runway-pressured situations — collapses output to verdict + 3 hour-level actions + dollar kill threshold.
- 3 nested subskills and 5 Claude Code slash commands for narrow flows:
/validate,/worth-filter,/kill-audit,/sharpen,/weekly-review.
Sample interaction
Prompt:
“I want to build a SaaS that helps freelance designers manage client feedback rounds. Designers waste hours chasing approvals. I’m thinking about building it. Should I?”
Response:
Verdict. Test first. Do not build.
Why. “Designers waste hours chasing approvals” is a real-sounding problem, but the offer is unvalidated, the buyer is loosely defined (“freelance designers” is a category, not a segment), and there is no evidence any of them will pay to fix it. Building before a paid pilot is the most common failure path for solo SaaS — months of code, no buyer, no channel.
Evidence read.
- Strongest: the friction is real (rung 1–2 — opinion + own observation).
- Weakest: no named buyer, no money on the table, no channel that reaches this buyer repeatedly. Currently rung 1.
Proof test. Cash Proof Sprint, 7 days. A 14-day “approval-cycle audit” — review the buyer’s last 5 client projects, identify the cycles that lost time, give a one-page tightening plan. $250, paid before. Direct outreach to 25 freelance brand designers billing $5k+ per project with 3+ active clients.
Keep / change / kill thresholds.
- Keep: 5+ paid audits ($1,250+ collected), and 2+ buyers explicitly ask “is there a tool for this?”
- Change: 1–4 paid audits with consistent objections about workflow specifics — reshape the offer.
- Kill: 0 paid audits after 25 contacts. The pain is not painful enough to pay for. Capture the learning and stop.
Next three actions, today.
- Write the 25-name outreach list. Use Twitter/X bio search + LinkedIn.
- Write the 4-sentence outreach message ending with “$250, paid before, reply by Friday.”
- Send the first 5 messages today.
This is a worked transcript that ships with the skill. Two more (prioritization, kill-audit) are included in the package.
How it’s different
- It refuses to soften. When evidence is rung 1–2, the verdict is “test first,” not “looks promising, here’s a roadmap.”
- It tracks calibration. Predictions are logged with stated confidence. Once 10+ entries exist in a category, the skill cites the user’s actual hit rate before accepting new probability claims.
- It names blind spots. If a user habitually skips rung 6 before committing, the skill flags it inline on the next decision in that domain.
- It has a Crisis Mode. When the user mentions runway, payroll, or a lost biggest customer, the skill collapses output to verdict + three hour-level actions + dollar kill threshold. Worth Filter scoring tables and Evidence Ladder discussion are skipped.
Manual
How to actually use the skill once it’s installed. This section is the operating guide — read it once before your first session, then keep it as a reference.
1. What to bring to a session
The skill is sharp on specific situations and dull on broad ones. Before invoking it, get the following on the table:
- A specific decision, idea, project, or list. “Should I build X?” is a session. “Help me think about my business” is not.
- The buyer or user the decision is about. Even a rough first draft — “freelance brand designers billing $5k+ per project” beats “designers.”
- Numbers, if any exist. Current revenue, signups, churn, conversion rate — whatever’s relevant. The skill works with assumptions when numbers are missing, but real numbers always sharpen the answer.
- The deadline or budget. “I have 60 days and $5k” changes the verdict; “no constraints” produces a fuzzier answer.
If any of these are missing, the skill will ask the smallest question that fills the gap. Don’t pretend to have data you don’t — the answer is still useful with stated assumptions.
2. How to invoke it
Two ways: a plain prompt naming the skill, or a slash command if you’re in Claude Code.
Plain invocation. Start your prompt with “Use the outcome-first-decisions skill to…” followed by the situation. Examples:
Use the outcome-first-decisions skill to validate this idea: [paste idea].
Use the outcome-first-decisions skill to choose between these three opportunities: [paste list].
Use the outcome-first-decisions skill to audit my current commitments: [paste list].
Use the outcome-first-decisions skill to sharpen this offer: [paste current offer].
Use the outcome-first-decisions skill for my weekly review. Scoreboard number: [name + value].Slash commands (Claude Code). Each command loads a narrow flow with extra hard rules:
/validate [idea]— for a single idea you’re considering. Forces a 7-day Cash Proof Sprint and a written kill criterion./worth-filter [options]— for two or more comparable options. Returns scored verdicts and a re-trigger condition for anything deferred./kill-audit [list]— for an active commitment list when you’re scattered. Returns keep/change/kill verdicts with reclaimed capacity allocated to surviving work./sharpen [offer]— for a vague offer. Returns a Buyer/Moment/Promise/Mechanism/Ask one-pager and a pre-sale ask. Refuses to sharpen without rung-5+ buyer evidence cited./weekly-review [scoreboard]— for the Friday check-in. Combines a five-question retrospective with the next-week plan.
3. What the skill will refuse to do
The hard rules are the point of the skill. It will refuse, redirect, or push back when:
- The buyer is a category, not a segment. “Founders” gets pushed back to “founders of what, at what stage, with what active problem.”
- The evidence is opinion or compliment. “My friends say it’s a great idea” is rung 1–2; the skill will design a test, not commit to a verdict.
- The “ask” is a survey or “book a call”. The skill replaces it with a pre-sale pattern: price, scope, deadline, refund policy, and cap.
- The decision has no kill criterion. The skill won’t approve a commitment without naming the result that would end it.
- You ask for emotional reassurance. The skill is not a coach in that sense. It will name the trade-off, not soften it.
You can override any of these by stating the assumption explicitly — e.g., “I know rung-1 evidence isn’t enough; assume the buyer is X and tell me what to test next.” The skill respects explicit overrides; it pushes back only on implicit ones.
4. What you’ll get back
Every full answer comes in six parts:
- Verdict. One line: worth doing, test first, change, defer, or drop.
- Why. Two to four sentences of business logic. No hedging.
- Evidence read. Strongest and weakest parts of the case, mapped to a rung (1–8) on the Buyer Evidence Ladder.
- Proof test. A specific 1- to 7-day experiment with sample size, channel, ask, and threshold.
- Keep / change / kill thresholds. The result that means continue, adjust, or stop — written before the test runs.
- Three actions for today. Concrete, executable in the next 24 hours.
If you want a tighter answer, ask for “verdict and three actions only.” If you want depth, ask for “the full Worth Filter score and per-dimension reasoning.”
5. The weekly cycle
The skill is designed for a weekly rhythm. The recommended pattern:
- Monday, 15 minutes: Pull the kept commitments from last Friday’s review. Confirm the scoreboard number and the three actions. Send the first buyer-facing message of the week before opening any other tab.
- Wednesday, 5 minutes: Mid-week reality check. Did the proof tests produce evidence? If not, what’s the smallest action that would?
- Friday, 20 minutes: Run
/weekly-review. Five questions: what number moved, what proof landed, what got killed, where calibration was off, what decision is being postponed. Output: next-week plan with three actions and one stop.
If you can only do one of these, do Friday. The retrospective is the part that compounds.
6. Logging decisions and tracking calibration
Every keep/change/kill verdict belongs in the decision journal. The skill ships a YAML schema for entries:
id: 2026-04-28-cohort-presale
decision: "Run the 6-week positioning cohort"
verdict: test # keep | change | kill | test
category: pricing # validation | prioritization | pricing | hire | partnership | offer | channel | other
buyer: "Past clients + warm referrals"
prediction:
outcome: "5+ paid deposits by Friday May 8"
confidence: 0.60 # in 0.10 increments, required at decision time
kill_criterion: "0-1 deposits → cohort cancels"
deadline: 2026-05-08
status: open # open | hit | missed | drifted
outcome: null # filled at deadline
lesson: null # filled at deadlineStore entries wherever fits your workflow — Notion, Obsidian, a markdown file, a spreadsheet. The format is what matters: confidence is required at decision time, and the outcome and lesson get filled at the deadline. Skip those and the entry becomes decision debt.
After 10+ entries in a category, the skill will start citing your hit rate inline. If you predicted 80% confidence on validation calls and hit 42% of them, the skill will say so and discount your next 80% claim accordingly. The calibration is a mirror, not a scolding.
7. Crisis mode
If you mention runway under 90 days, missed payroll, a lost biggest customer, or invoke /crisis-mode, the skill compresses the output:
- Verdict. One line.
- Three actions for today, with hour-level deadlines.
- The dollar threshold below which the business closes.
Worth Filter scoring tables, the Evidence Ladder, and the full Main Output Shape are skipped — in crisis, they’re themselves busywork. The skill operates with shorter horizons: named buyer = an existing paying customer who can re-buy in 48 hours; one number = cash collected this week; proof test = inside 7 days, not “up to 7.”
8. Common pitfalls
- “Looks promising, here’s a roadmap.” If you ever see this kind of answer, the skill isn’t loaded properly. Reinstall, or restart the session and explicitly invoke the skill by name.
- The skill keeps asking clarifying questions. Means you’re starting too broad. State assumptions explicitly so it can proceed: “Assume buyer is X, scoreboard number is Y. Now answer.”
- The skill softens. Re-prompt: “Cite the rung of evidence. State the kill criterion in writing. No hedging.”
- The verdict feels harsh. The verdict is a reading of evidence, not a judgment of you. Capture the learning, log the kill, redirect capacity to the next bet.
Install
Compatible with Claude Code, Codex / OpenAI, and Cursor. Distributed as a versioned package (current release: v1.0.0, AGPL-3.0).
Download the package — outcome-first-decisions.zip
Install into your agent’s skills directory:
# Claude Code
mkdir -p ~/.claude/skills && unzip outcome-first-decisions.zip -d ~/.claude/skills/
# Codex / OpenAI
mkdir -p ~/.codex/skills && unzip outcome-first-decisions.zip -d ~/.codex/skills/
# Cursor
mkdir -p ~/.cursor/skills && unzip outcome-first-decisions.zip -d ~/.cursor/skills/Once installed, invoke with: Use the outcome-first-decisions skill to validate this idea. Or use one of the slash commands listed above.
By Thorsten Meyer. Latest release: v1.0.0.







