€90 million MareNostrum 5 upgrade investment + €150 million additional ALIA integration funding. ALIA-40B trained on 9.37 trillion tokens across 35 European languages and 92 programming languages. Salamandra-7B and Salamandra-2B trained from scratch on 12.875 trillion tokens. Released under Apache License 2.0 on HuggingFace April 22, 2025. Coordinated by Barcelona Supercomputing Center (BSC-CNS) and led by the Secretary of State for Digitalisation and Artificial Intelligence (SEDIA). Trained on MareNostrum 5’s 4,480 NVIDIA H100 GPU accelerated partition. Spain’s national continuation answer to the European sovereign-AI question — and a structural test case for the Position 1 vs Position 3 strategic-positioning argument from the synthesis essay.
By Thorsten Meyer — May 2026
This is the tenth standalone essay in the European sovereign-LLM track and the third Tier 2 expansion piece. The prior nine essays documented six institutional answers (AMÁLIA · Portuguese national continuation, Minerva · Italian national from-scratch, OpenEuroLLM · pan-European consortium, Mistral · French commercial-frontier, Aleph Alpha · German enterprise-sovereignty pivot, Apertus · Swiss federal-research-institution), the integrative synthesis framework, the EuroHPC compute substrate, and the Schwarz Group industrial-anchor interrogation. ALIA is Spain’s institutional answer — the largest EU member state by GDP not yet documented in the track. The piece extends the geographic coverage and interrogates the Position 1 vs Position 3 strategic-positioning question with Spanish operational evidence.
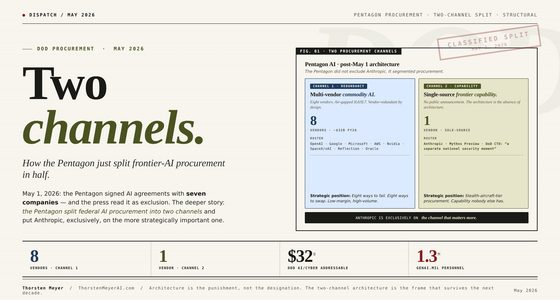
The structural argument I want to make: ALIA fits the Position 3 strategic profile (multilingual specialization with Spanish-language oversampling) structurally — but the project markets itself as a Position 1 + Position 2 attempt simultaneously. The benchmark evidence suggests Position 3 framing is more operationally honest. ALIA-40B benchmark performance against Llama 2 (51.77% XNLI_en vs Llama 2’s 66%; 81.53% SQuAD_en vs Llama 2’s 93-94%) confirms the structural capability gap (Finding 1 from the synthesis essay) at empirical operational evidence. The Position 1 attempt at 40B scale with €90M+€150M public funding produces sub-Llama-2 results — but the Position 3 strategic positioning (Spanish-speaking world adoption, AESIA-validated transparency, co-official languages coverage) is operationally credible and structurally distinctive.
The headline integrative finding: ALIA demonstrates the most ambitious European national-continuation public-funded AI project at scale — €240M+ cumulative public investment, 40B parameter from-scratch training, 35-language multilingual coverage, Apache 2.0 open-source release, AESIA validation. It also operationally confirms the structural capability gap with benchmark evidence below Llama 2 levels. The strategic implication is that the project leadership’s own framing — Josep M. Martorell’s quote “the goal is not to be the best-performing LLM in the world, but the most widely adopted in the Spanish-speaking world” — is the operationally honest Position 3 framing that the public-relations launch positioning around “Europe’s first public multilingual foundational model” obscures.
This piece walks the empirical operational evidence of the Spanish ALIA / Salamandra project, the Position 1 vs Position 3 strategic-positioning tension, the multilingual-coverage scope across the 35 European languages with co-official Spanish oversampling, and what the analysis implies for the synthesis essay’s strategic recommendations applied to Spain specifically.
ALIA.
The Spanish
answer.
€240M+ Spanish public funding · ALIA-40B + Salamandra family · 9.37T tokens · 35 European languages + 92 programming languages · MareNostrum 5 · Apache 2.0 release. The largest publicly funded European national-AI project by cumulative scope — and the empirical test case for the Position 1 vs Position 3 strategic-positioning argument.
This is the tenth standalone essay in the European sovereign-LLM track and the third Tier 2 expansion piece. ALIA is Spain’s institutional answer — the largest EU member state by GDP not yet documented in the track. The project markets itself as Position 1 + Position 2 simultaneously — “Europe’s first public multilingual foundational model.” The benchmark evidence (ALIA-40B 51.77% XNLI_en vs Llama 2 66%) confirms the structural capability gap from Finding 1 of the synthesis essay. The Position 3 framing — Martorell’s “most widely adopted in the Spanish-speaking world” — is operationally honest. €90M MareNostrum 5 upgrade + €150M company integration = €240M+ cumulative scope. Apache 2.0 open-source release + AESIA validation + co-official languages oversampling. Both can be true at once. The Spanish public discourse would benefit from explicit Position 3 strategic positioning.
Six models. Apache 2.0.
The ALIA family operates as a tiered model portfolio. ALIA-40B is the flagship at 40 billion parameters; the Salamandra family scales down to 7B, 2B and instruct-tuned variants; mRoBERTa provides the foundational multilingual baseline. All released under Apache License 2.0 on April 22, 2025 at the HispanIA 2040 event — “Public Code, Public Money” approach.
multilingual
MN5 LLM
edge
target
instruct
encoder

Multilingual AI Translation Mastery: Building Accurate, Culturally Sensitive Language Tools and Global Communication Systems in 2026
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Four official. Oversampled by factor of 2.
ALIA’s distinctive multilingual coverage strategy. The four co-official Spanish languages are oversampled by factor of 2 in the training corpus — structurally distinct from Apertus’s broad 1,811-language coverage approach. The strategy targets deep coverage of Spanish co-official languages rather than maximum language breadth.

Large Language Models: The Hard Parts: Open Source AI Solutions for Common Pitfalls
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
ALIA-40B vs Llama 2. 14-point gap.
The empirical evidence Finding 1 of the synthesis essay needed. ALIA-40B at 40 billion parameters with €240M+ public funding and 8+ months MareNostrum 5 training achieves performance below Llama 2 — a 2023 frontier model released approximately 18 months before ALIA-40B. The capability gap is real and consistent with six of seven prior national-project answers documented in the track.

Mini AI Voice chatbot, smart Voice Assistant, Multiple AI Models, Emotional Interaction, 100+ Stickers, Suitable for Home and Office use, (Black)
1. Emotional Interaction: This chatbot can recognise and respond to your emotions, offering a more personalised and human-like…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Two pilots. Public administration deployment.
The operational deployment targets that validate the Position 3 + Position 4 framing. Public administration deployment is the structurally credible Position 3 + Position 4 strategic positioning — captive demand from Spanish public institutions where Spanish-language specialization is operationally distinctive.
The work is real across the Spanish ALIA case. €240M+ public funding committed. 40B parameter from-scratch model trained on 9.37 trillion tokens. Salamandra family released under Apache 2.0. AESIA validation aligned with EU AI Act transparency standards. Two pilot applications shipped — Tax Agency chatbot and primary care medicine heart failure diagnosis. The Position 1 framing is operationally misleading. ALIA-40B performance below Llama 2 confirms the structural capability gap. The Position 3 framing is operationally honest — Spanish-speaking world adoption, co-official languages oversampling, public administration deployment. Both can be true at once. The Spanish public discourse would benefit from explicit Position 3 strategic positioning.

The AI Factory Handbook: Build, Manage, and Scale NVIDIA AI Infrastructure (NCA-AIIO Exam Prep & Real-World Operations)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
I · The operational evidence · what ALIA has actually shipped
The factual baseline before the structural argument. From the Barcelona Supercomputing Center ALIA announcement, the Interoperable Europe Spanish authorities ALIA release documentation, the HuggingFace ALIA-40B model card, the Spanish government MareNostrum 5 AI strategy documentation, and the Oxford Insights ALIA spotlight interview.
The institutional architecture
ALIA — “Artificial Linguistic Intelligence for Administration” — is the Spanish government’s public AI infrastructure initiative. The institutional structure operates through three programmatic layers:
- Political leadership · Secretary of State for Digitalisation and Artificial Intelligence (SEDIA) within the Ministry of Digital Transformation and the Civil Service · launched publicly by President Pedro Sánchez January 21, 2025
- Technical coordination · Barcelona Supercomputing Center · Centro Nacional de Supercomputación (BSC-CNS) · Director Mateo Valero · Associate Director Josep M. Martorell · ALIA technical lead Marta Villegas
- Originating projects · AINA (Catalan-language project, Generalitat de Catalunya) since 2020 · ILENIA (Spanish + co-official languages consortium) under CLARIAH-ES since 2021 · Language Technologies Plan since 2019
The funding structure is 100% public:
- €90 million for MareNostrum 5 upgrades (450 PFLOPS, ~50% capacity increase) · Spanish AI Strategy 2024
- €150 million for ALIA integration into companies · Spanish AI Strategy 2024
- 20% of MareNostrum 5 capacity dedicated to industry under the strategy
- Total Spanish public AI investment scope: €240M+ plus EuroHPC JU contribution for MareNostrum 5 itself
For temporal context with the seven prior national-project essays:
- AMÁLIA · €5.5M Portuguese state funding · 1B fine-tune
- Minerva · Sapienza + FAIR PNRR funding · 7B from-scratch
- OpenEuroLLM · €37.4M EU funding · pan-European consortium
- Mistral · ~€3B venture capital cumulative · commercial-frontier
- Aleph Alpha · €500M+ Schwarz Group → Cohere merger · enterprise-sovereignty pivot
- Apertus · CSCS + EPFL + ETH Swiss federal funding · 70B from-scratch
- ALIA · €240M+ Spanish public funding · 40B from-scratch + Salamandra family
ALIA is the largest publicly funded European national-AI project by cumulative scope — exceeding Portugal AMÁLIA, Italy Minerva, and the OpenEuroLLM EU consortium funding combined.
The ALIA model family
Per the HuggingFace BSC-LT model collection and the Salamandra Technical Report (arXiv 2502.08489):
The ALIA family includes five distinct models released under Apache License 2.0 on April 22, 2025:
- ALIA-40B · 40 billion parameters · transformer-based decoder-only architecture · pre-trained from scratch on 9.37 trillion tokens of highly curated data · 35 European languages + 92 programming languages · trained for 8+ months on MareNostrum 5
- Salamandra-7B · 7 billion parameters · transformer-based decoder-only · pre-trained from scratch on 12.875 trillion tokens across 35 European languages + code
- Salamandra-2B · 2 billion parameters · transformer-based decoder-only · same 12.875 trillion token corpus
- Salamandra-7B-instruct · instruction-tuned · 276,000 instructions in English, Spanish, and Catalan from open corpora
- Salamandra-2B-instruct · instruction-tuned · same instruction corpus
- mRoBERTa · multilingual foundational model based on RoBERTa architecture · pretrained from scratch using 35 European languages + code
All training scripts and configuration files are publicly available on GitHub. This is the “Public Code, Public Money” approach that distinguishes ALIA from the seven prior institutional answers — the open-source release is more comprehensive than Mistral’s selective open-weights releases, more accessible than Aleph Alpha’s enterprise-licensing model, and structurally aligned with Apertus’s full open-source architecture.
The MareNostrum 5 training infrastructure
Per the EuroHPC compute substrate analysis (Standalone Essay 08) and the BSC documentation:
MareNostrum 5 operational scale for ALIA training:
- Accelerated partition: 1,120 nodes × 4 NVIDIA H100 = 4,480 NVIDIA H100 GPUs
- Hosted and operated by BSC-CNS
- EuroHPC pre-exascale supercomputer
- AI upgrade signed January 2026 with FSAS Technologies + Telefonica consortium · installation starting early 2026 · upgrade increases capacity to 450+ PFLOPS
ALIA-40B was trained for 8+ months on MareNostrum 5. The Salamandra family was the first LLM trained from scratch using MareNostrum 5’s accelerated partition per the CLARIN ERIC documentation. This crystallizes the operational dependency: ALIA depends on EuroHPC compute substrate access at the AI Factory tier — the same dependency Minerva has on Leonardo and Apertus has on Alps.
The language coverage strategy
The structural distinctive feature of ALIA’s multilingual approach. Per the HuggingFace ALIA-40B model card:
ALIA training corpus composition:
- 35 European languages · the broad multilingual baseline
- 92 programming languages · code generation capability
- Spanish co-official languages oversampled by factor of 2 · Castilian Spanish, Catalan (with Valencian variants), Basque (Euskera), Galician
- Contribution to Community OSCAR (151 languages · 40T words multilingual corpus) and CATalog (largest open Catalan dataset globally)
- 33 terabytes of training corpus memory footprint · ~17 million books equivalent · 4.5 million high-resolution photos equivalent · 6.6 million songs equivalent
The multilingual coverage is structurally distinctive from Apertus’s 1,811 languages. Apertus prioritized broad coverage including minority and low-resource languages globally. ALIA prioritized deep coverage of Spanish co-official languages plus the 35 most-represented European languages — a structurally different strategic positioning.
The training data distribution detail Bara surfaced (from the Silicon analysis) is operationally significant: “only 16.12% of its training data is in our language, while English dominates, with 39.31%.” This is the structural tension the project faces — the multilingual scope dilutes the Spanish-specific specialization that the project’s strategic positioning emphasizes.
The customer and deployment positioning
Per the Interoperable Europe ALIA release coverage:
The Spanish government announced two pilot applications at the HispanIA 2040 event (April 22, 2025):
- Internal Tax Agency chatbot · streamlining work of the Agencia Tributaria · citizen service automation
- Primary care medicine diagnosis · advanced data analysis facilitating heart failure diagnosis · healthcare deployment
The strategic positioning quote from Josep M. Martorell (BSC Associate Director, per the Oxford Insights interview): “The goal is not to be the best-performing LLM in the world, but the most widely adopted in the Spanish-speaking world.”
This is the operationally honest Position 3 framing. The Spanish-speaking world (Spain + Latin America + global Hispanic diaspora) represents approximately 500+ million native speakers and a structurally distinctive linguistic-cultural ecosystem. ALIA’s strategic positioning to target this specific linguistic-cultural audience is structurally credible in ways that competing against frontier-class English-language models is not.
II · The Position 1 vs Position 3 strategic-positioning interrogation
The structural argument that the operational evidence supports. ALIA-40B benchmark performance crystallizes the Position 1 attempt’s limitations and the Position 3 framing’s operational credibility.
The benchmark evidence · the structural capability gap empirically confirmed
Per the Silicon analysis by Bara of Tokiota:
ALIA-40B benchmark results against Llama 2 (July 2023 release):
- XNLI_en (Natural Language Inference English) · ALIA: 51.77% · Llama 2: 66% · gap: 14.23 percentage points
- SQuAD_en (Question Answering English) · ALIA: 81.53% · Llama 2: 93-94% · gap: 11.47-12.47 percentage points
The structural significance: ALIA-40B at 40 billion parameters with €240M+ public funding and 8+ months MareNostrum 5 training time achieves performance below Llama 2 (a 2023 frontier model released approximately 18 months before ALIA-40B’s release). Llama 2 has been superseded by Llama 3, Llama 4, and frontier-class models from OpenAI, Anthropic, Google, and Meta released through 2024-2026. The empirical capability gap is real and consistent with Finding 1 from the synthesis essay: the structural capability gap across all six institutional models is empirically confirmed.
This is not an ALIA-specific failing. The same empirical pattern is visible across the seven national-project answers documented in the prior essays:
- AMÁLIA · 5.5% pt-PT improvement on 1B fine-tune · operationally below Position 1 frontier
- Minerva · 4.9% INVALSI improvement on 7B from-scratch · operationally below Position 1 frontier
- Mistral · ~44% GPQA Diamond vs Gemini’s 91.9% · operationally below Position 1 frontier
- Aleph Alpha · pivoted away from frontier model attempts to enterprise-sovereignty pivot · operationally acknowledged the gap
- Apertus · MMLU-Pro 31.14% · operationally below Position 1 frontier
- ALIA · benchmark performance below Llama 2 · operationally below Position 1 frontier
- OpenEuroLLM · still in training as of May 2026 · operational benchmarks not yet shipped
Six of seven national-project answers operationally confirm the structural capability gap. OpenEuroLLM is the only project whose benchmarks haven’t yet shipped. The empirical pattern is structurally consistent.
The Position 3 framing · what ALIA actually does well
Position 3 in the synthesis framework = multilingual specialization at smaller scale than frontier-class models. ALIA’s operational strengths fit Position 3 structurally:
- Spanish co-official languages oversampling · 2x oversampling of Castilian Spanish, Catalan/Valencian, Basque, Galician · structurally distinctive coverage
- Apache 2.0 open-source release · “Public Code, Public Money” approach · full training scripts and configuration files on GitHub · more accessible than competing models
- AESIA validation · Spanish AI Supervisory Agency · aligned with EU AI Act transparency standards · regulatory architecture inheritance
- Spanish-speaking world adoption strategy · 500+ million native speakers · structurally distinctive linguistic-cultural ecosystem · operationally credible target
- Public administration deployment · Tax Agency chatbot · primary care medicine diagnosis · the captive demand that AMÁLIA’s structural argument also identifies
The Position 3 framing is operationally honest about what ALIA does well. The Position 1 framing (positioning ALIA as “Europe’s most advanced public multilingual foundational model”) is operationally misleading — ALIA’s benchmark performance does not support the framing.
The red-teaming evidence · the structural safety gap
Per the March 2025 red-teaming study (arXiv 2503.10192):
Salamandra red-teaming results (670 conversations across 10 participants including 5 PhD holders):
- Salamandra: 50.6% biased or unsafe responses
- OpenAI o3-mini: 29.5% biased or unsafe responses
- DeepSeek R1: results within the same range
The structural significance: Salamandra’s safety performance is approximately 1.7× worse than o3-mini’s on Spanish and Basque language interactions. This is consistent with the synthesis essay’s Finding 1 (structural capability gap) extended to safety architecture — frontier-class models have invested significantly more in RLHF + Constitutional AI + safety post-training than the Spanish public model has been able to invest with €240M+ public funding.
The operational implication: ALIA’s Position 3 framing is structurally honest, but the Position 1 + Position 2 marketing framing creates expectations that the operational evidence cannot meet. The Spanish public discourse around ALIA would benefit from explicit Position 3 strategic positioning — multilingual specialization with Spanish-language oversampling for Spanish-speaking world adoption, AESIA-validated transparency, public administration deployment, and explicit acknowledgment that frontier-class benchmarks are not the operational target.
III · The structural-positioning observations for Spain specifically
The integrative observations the ALIA analysis produces for Spanish AI policy strategists. Three structural implications crystallize from the operational evidence.
Implication 1 · The Position 3 strategic positioning is the operationally honest framing
Martorell’s quote should be the official strategic-positioning framing. “The goal is not to be the best-performing LLM in the world, but the most widely adopted in the Spanish-speaking world.” This is the operationally honest Position 3 framing that the benchmark evidence supports.
The strategic implication: Spanish AI policy should explicitly reframe ALIA as a Position 3 + Position 4 vertical-specialization initiative — Spanish-speaking world adoption + AESIA-validated transparency + public administration deployment + co-official languages coverage. The Position 1 framing creates structural expectations the operational evidence cannot meet.
Concrete policy implications:
- Stop benchmarking ALIA against frontier-class models in public-relations materials · the comparison creates structurally misleading expectations
- Start benchmarking ALIA against Spanish-language and co-official-language metrics · INVALSI-equivalent Spanish-language benchmarks (Catalan-NLI, Basque-NLI, Galician-NLI) where the multilingual oversampling produces structural advantages
- Document ALIA’s Position 3 deployment metrics · adoption in Spanish-speaking world public administrations, universities, and SME contexts · the structurally credible operational target
Implication 2 · The MareNostrum 5 AI upgrade is the structural prerequisite for future ALIA generations
The MareNostrum 5 AI upgrade signed January 2026 (FSAS Technologies + Telefonica consortium · installation starting early 2026 · per the EuroHPC compute substrate essay) is the structural prerequisite for next-generation ALIA training. Future ALIA-100B+ class training runs require the upgraded MareNostrum 5 capacity that is being deployed through 2026-2027.
The strategic implication: Spanish AI policy should explicitly align ALIA roadmap with MareNostrum 5 upgrade timeline. The €90M MareNostrum 5 investment commitment from the 2024 AI Strategy is structurally aligned with ALIA-V2 training capability through 2027-2028. The bottleneck is not funding scope (€240M+ is substantial) but training-capacity timing (MareNostrum 5 upgrade installation through 2026-2027).
Implication 3 · The Spanish-speaking world adoption strategy requires distinct partnership architecture
Martorell’s Position 3 framing implies a distinctive partnership architecture: Spanish-speaking world adoption. This is structurally different from the EU-internal multilingual scope of OpenEuroLLM, Apertus, or even ALIA’s own 35-European-languages baseline.
Concrete partnership implications:
- Latin American academic and government partnerships · Mexico (UNAM, Tecnológico de Monterrey) · Argentina (UBA, CONICET) · Chile (Universidad de Chile, Pontificia Universidad Católica) · Colombia (Universidad de los Andes) · Peru (PUCP)
- Spanish-speaking diaspora applications · US Hispanic-community public service applications · global Hispanic-community SME deployments
- Cultural-heritage and linguistic-preservation partnerships · Real Academia Española (RAE) and the 22 national language academies of the Asociación de Academias de la Lengua Española (ASALE) · structurally aligned with ALIA’s linguistic-sovereignty framing
The Position 3 strategic positioning has a structurally distinctive partnership target. Spanish AI policy should explicitly develop this partnership architecture rather than positioning ALIA against frontier-class English-language models.
IV · The closing argument · what the Spanish ALIA case implies for the European sovereign-AI movement
The integrative observation the ALIA analysis produces for the ten-essay framework. ALIA crystallizes the empirical confirmation of Finding 1 from the synthesis essay (the structural capability gap is real across all national-project answers) and operationally validates the Position 3 + Position 4 strategic-positioning recommendations for European national-AI projects.
Summary of the ten-essay framework as of mid-May 2026:
- Essay 01 · AMÁLIA · Portuguese national continuation · €5.5M · 5.5% pt-PT improvement · Position 3 specialization
- Essay 02 · Minerva · Italian national from-scratch · PNRR funding · 4.9% INVALSI improvement · Position 3 specialization
- Essay 03 · OpenEuroLLM · pan-European consortium · €37.4M · Position 2 coverage
- Essay 04 · Mistral · French commercial-frontier · €3B+ VC · Position 1 attempt + Position 4 success
- Essay 05 · Aleph Alpha · German enterprise-sovereignty pivot · €500M+ → Cohere merger · retrospective case
- Essay 06 · Apertus · Swiss federal-research-institution · architectural-compliance template
- Essay 07 · Portfolio · synthesis framework · seven findings + five recommendations
- Essay 08 · EuroHPC · compute substrate analysis · three structural complications
- Essay 09 · Schwarz Group · industrial-anchor model interrogation · five-preconditions replication framework
- Essay 10 · ALIA (this piece) · Spanish national-continuation pattern · Position 1 vs Position 3 interrogation
The integrative finding crystallized: the European sovereign-AI movement operates across a portfolio of institutional structures at structurally distinct scales (€5.5M Portugal AMÁLIA → €240M+ Spain ALIA → €3B Mistral commercial-frontier → €11B+ Schwarz Group industrial-anchor → €20B InvestAI AI Gigafactory framework). Each institutional structure serves different operational requirements at different scales. ALIA’s €240M+ public-funded national-continuation pattern operates between AMÁLIA’s €5.5M Portuguese pattern and Mistral’s €3B commercial-frontier pattern — structurally distinct from both.
For Spanish AI policy specifically:
- ALIA is the largest publicly funded European national-AI project by cumulative scope — the Spanish public investment commitment exceeds Portugal, Italy, and the EU OpenEuroLLM consortium combined
- The Position 3 strategic-positioning framing is operationally honest — Martorell’s “most widely adopted in the Spanish-speaking world” framing should be the official positioning
- The MareNostrum 5 AI upgrade timeline determines ALIA-V2 capability horizon — strategic alignment with 2026-2027 deployment is structurally important
- The Spanish-speaking world partnership architecture is structurally distinctive — distinct from EU-internal multilingual scope and structurally credible
The August 2 enforcement window remains twelve weeks away. The June 2026 AI Gigafactory selection process runs in parallel. The summer 2026 operational moment is when the European sovereign-AI movement’s strategic positioning is determined for the 2027-2029 horizon. The ten-essay framework is what the discourse should integrate before the windows close.
That’s the read on the Spanish ALIA / Salamandra project as of mid-May 2026 — twelve weeks before the August 2 enforcement window opens and approximately six weeks before AI Gigafactory selection decisions begin shipping. The work is real across the Spanish ALIA case. €240M+ public funding committed. 40B-parameter from-scratch model trained on 9.37 trillion tokens. Salamandra family released under Apache 2.0. MareNostrum 5 AI upgrade installation underway. AESIA validation aligned with EU AI Act transparency standards. Two pilot applications shipped (Tax Agency + primary care medicine). The Position 1 framing is operationally misleading. ALIA-40B performance below Llama 2 confirms the structural capability gap. The Position 3 framing is operationally honest — Spanish-speaking world adoption, co-official languages oversampling, AESIA-validated transparency, public administration deployment.
Both can be true at once. ALIA is structurally credible as a Position 3 + Position 4 European national-AI project at €240M+ scale. ALIA is structurally not credible as a Position 1 + Position 2 frontier-class attempt. The Spanish public discourse would benefit from explicit Position 3 strategic positioning. The strategic-positioning honesty is what enables the operational adoption Martorell identifies as the goal.
The August 2 enforcement window is twelve weeks away. The AI Gigafactory selection timeline is operationally active. The MareNostrum 5 AI upgrade is underway. The discourse should integrate the ten-essay framework before all three deadlines arrive.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Related Reading · the European sovereign-LLM essay track
- AMÁLIA · The Three Hard Questions — Standalone Essay 01 · Portuguese national continuation
- Minerva · The Opposite Path — Standalone Essay 02 · Italian national from-scratch
- OpenEuroLLM · The Third Path — Standalone Essay 03 · pan-European consortium
- Mistral · The Fourth Path — Standalone Essay 04 · commercial-frontier
- Aleph Alpha · The Retrospective Case — Standalone Essay 05 · enterprise-sovereignty pivot
- Apertus · The Architectural Template — Standalone Essay 06 · federal-research-institution
- Portfolio · The Synthesis — Standalone Essay 07 · synthesis framework
- EuroHPC · The Compute Substrate — Standalone Essay 08 · compute substrate analysis
- Anchor · The Schwarz Group Model — Standalone Essay 09 · industrial-anchor interrogation
- This piece — Standalone Essay 10 · ALIA · Spanish national-continuation pattern · Position 1 vs Position 3 interrogation
Sources
ALIA / Salamandra / BSC operational documentation
- BSC-CNS · ALIA Europe’s first public open and multilingual AI infrastructure · ALIA-40B announcement · MareNostrum 5 training · 9.2T tokens 35 languages
- BSC-CNS · Spanish government strengthens AI capabilities of MareNostrum 5 · €90M MareNostrum 5 upgrade · 450 PFLOPS · 20% industry capacity
- HuggingFace · BSC-LT/ALIA-40b model card · technical specifications · training corpus · 92 programming languages · OSCAR/CATalog contribution
- Interoperable Europe · Spanish authorities release ALIA AI models · Apache 2.0 release · pilot applications · Tax Agency + primary care medicine
- HPCwire · BSC ALIA Project Taps MareNostrum 5 to Build Europe’s Largest Public AI Model · Sánchez announcement · technological sovereignty framing
- Science|Business · BSC ALIA Europe’s first public open multilingual AI infrastructure · launch coverage · Catalan Minister Núria Montserrat quote
- CLARIN ERIC · LLMs for Spain’s Official Languages · Salamandra first MareNostrum 5 from-scratch LLM · Latxa Basque-language baseline
- Oxford Insights · From policy to practice · how ALIA strengthens Spain’s public AI infrastructure · Martorell interview · “most widely adopted in Spanish-speaking world” quote · 50 experts team scale
- Salamandra Technical Report · arXiv 2502.08489 · Gonzalez-Agirre et al. · technical specifications · architecture detail
- NVIDIA Developer · EMEA AI Model Builders · ALIA collection · NVIDIA AI inference platform integration
- Sifted · Spain to develop open-source LLM trained in Spanish, regional languages · Albert Cañigueral interview · AINA + ILENIA foundational projects
Critical analysis and benchmark evidence
- Silicon · This is ALIA, the AI promoted by the Spanish Government · Bara of Tokiota benchmark critique · 51.77% XNLI_en vs Llama 2 66% · 81.53% SQuAD_en vs Llama 2 93-94% · training data distribution analysis
- arXiv 2503.10192 · Red Teaming Contemporary AI Models · Insights from Spanish and Basque Perspectives · 670 conversations · Salamandra 50.6% biased/unsafe responses vs o3-mini 29.5%
- Alejandro Cantero · ALIA Spain’s LLM and Technological Sovereignty · €150M company integration investment · 9.2 trillion tokens · 17 billion words / 34 million documents
- rarcos.com · ALIA the Spanish AI model · model family overview · MareNostrum 5 accelerated partition · 1,120 nodes × 4 H100
Key reference figures and quantitative facts
- ALIA total Spanish public funding scope: €240M+ (€90M MareNostrum 5 upgrades + €150M company integration)
- ALIA-40B parameters: 40 billion (American 10⁹ scale)
- ALIA-40B training tokens: 9.37 trillion across 35 European languages + 92 programming languages
- Salamandra-7B + Salamandra-2B training tokens: 12.875 trillion
- Salamandra instruction tuning: 276,000 instructions in English, Spanish, Catalan
- Training corpus memory footprint: 33 terabytes (~17 million books equivalent)
- ALIA-40B training duration: 8+ months on MareNostrum 5
- MareNostrum 5 accelerated partition for ALIA: 1,120 nodes × 4 NVIDIA H100 = 4,480 H100 GPUs
- MareNostrum 5 upgrade: €90M · 450+ PFLOPS · 50% capacity increase · FSAS Technologies + Telefonica consortium · installation early 2026
- Public Code, Public Money approach: Apache License 2.0 · April 22, 2025 release at HispanIA 2040 event
- AESIA validation: Spanish AI Supervisory Agency · aligned with EU AI Act transparency standards
- Languages prioritized: Castilian Spanish, Catalan/Valencian, Basque (Euskera), Galician (2x oversampled) + 30+ other European languages
- Team scale: 50 experts in language technologies (BSC Language Technologies group)
- ALIA-40B benchmark XNLI_en: 51.77% (vs Llama 2: 66%)
- ALIA-40B benchmark SQuAD_en: 81.53% (vs Llama 2: 93-94%)
- Salamandra red-teaming: 50.6% biased/unsafe responses (vs o3-mini: 29.5%)
- Training data Spanish share: 16.12% (vs English: 39.31%)
- Pilot applications: Spanish Tax Agency (Agencia Tributaria) internal chatbot + primary care medicine heart failure diagnosis
- Originating projects: AINA (Catalan, 2020+) · ILENIA (Spanish + co-official languages, 2021+) · Language Technologies Plan (2019+)
- Strategic positioning quote (Martorell): “the goal is not to be the best-performing LLM in the world, but the most widely adopted in the Spanish-speaking world”
- Political leadership: Pedro Sánchez (President), Secretary of State for Digitalisation and AI (SEDIA), Ministry of Digital Transformation and the Civil Service
- Technical leadership: BSC-CNS Director Mateo Valero, Associate Director Josep M. Martorell, ALIA technical lead Marta Villegas