Reading Clark’s corporate commitment cascade — OpenAI’s September 2026 target, Anthropic’s automated alignment program, $500M for Recursive Superintelligence, and what the labs publicly say they’re building
By Thorsten Meyer — May 2026
The closing section of Jack Clark’s Import AI #455 contains the most often-missed evidence base for the broader automated AI R&D thesis. Clark catalogs the explicit, public, on-the-record commitments of the AI industry to automating AI R&D as their stated objective. Not as an emergent property. Not as a side effect of capability development. As the goal. OpenAI publicly targets “an automated AI research intern by September of 2026.” Anthropic publishes its Automated Alignment Researchers research program. DeepMind, the most circumspect of the big three, still endorses that “automation of alignment research should be done when feasible.” Recursive Superintelligence has raised $500M with the explicit goal of automating AI research. Mirendil’s stated mission is “building systems that excel at AI R&D.” Hundreds of billions of capital is flowing toward entities pursuing this objective.
This is the third and closing piece in the Outside Read series on Clark’s essay. The first piece addressed the coding singularity capability evidence. The second piece addressed the six AI R&D skill benchmarks and the engineering-vs-research distinction. This piece addresses the institutional dimension Clark introduces in his closing section: what happens when the forecasters are the builders.
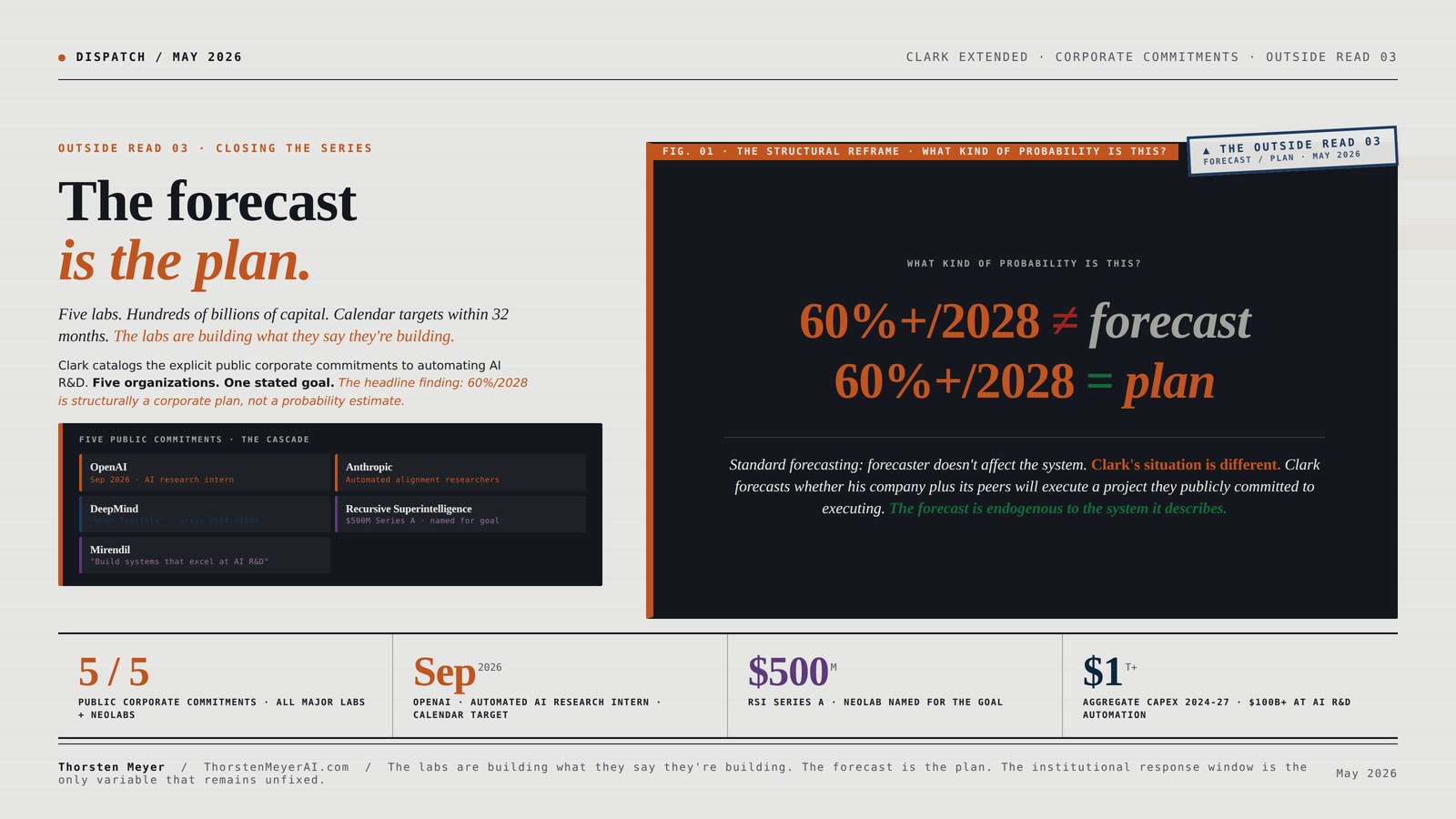
The headline finding: Clark’s 60%+/2028 forecast reads as a probabilistic statement about what might happen. The corporate commitment cascade reveals it as the description of an explicit corporate plan being executed by the people doing the forecasting. The forecast is the plan. This has significant implications for how external observers should interpret the trajectory and how the institutional response should calibrate.
What follows: the commitment cascade walk-through, the structural reframe of forecast-vs-plan, the capital scale, Clark’s Amdahl’s Law point about economic friction, the compute allocation political economy question, the five strategic dimensions Clark doesn’t develop, stakeholder implications, and the structural read that closes the Outside Read series.
The forecast
is the plan.
Five labs. Hundreds of billions of capital. Calendar targets within 32 months. The labs are building what they say they’re building.
Jack Clark’s closing section catalogs the explicit, public, on-the-record corporate commitments to automating AI R&D. OpenAI: “automated AI research intern by September 2026.” Anthropic: Automated Alignment Researchers. DeepMind: “automation of alignment research should be done when feasible.” Plus neolabs Recursive Superintelligence ($500M) and Mirendil. The headline finding: Clark’s 60%/2028 forecast is structurally a corporate plan, not a probability estimate.
Five labs. One stated goal.
Clark catalogs five distinct public commitments to automating AI R&D. Each individually is significant; the pattern across them is more so. When the industry uniformly commits and capital flows to support, the probability of execution rises substantially — not by magic but because thousands of researchers and engineers are deliberately working to produce the outcome.
TARGET
PROGRAM
FEASIBLE”
SERIES A
STATEMENT

CLAUDE AI UNLEASHED From First Prompts to Pro: The Complete Guide to Claude AI for Writing, Research, Coding, and Business (The Claude AI Mastery Series)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Hundreds of billions. Itemized.
Clark mentions “hundreds of billions” without itemizing. The verifiable scale from public sources. When capital concentrates around five-to-seven specific organizations with a stated objective, those organizations become the structural lever for whether the objective is achieved.

Autonomous Intern V1 — Personal AI Agent Desk Device | Handles Email, Calendar & Tasks via Whatsapp, Telegram & Slack | Plug-and-Play | On-Device Privacy | AI Plan Included
DOES THE WORK — NOT JUST LISTENS. Most "AI devices" record and transcribe. Autonomous Intern is a dedicated…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
AI accelerates cognitive work. It does not accelerate everything.
Clark introduces a structural observation worth developing. Amdahl’s Law from computer architecture, applied to the economy. As AI accelerates the cognitive-work layer, queues form at non-cognitive layers. The economic disruption from AI is concentrated rather than distributed.
- Software engineering
- Financial analysis
- Marketing & copy
- Legal research
- Customer service
- Code review & documentation
30-50%+ productivity gains
- Drug trials (clinical trials, FDA)
- Infrastructure construction
- Legislative cycles
- Biological/chemical processes
- Trust-building & B2B sales
- Regulated industries broadly
Queues at the slow part

AI Snake Oil: What Artificial Intelligence Can Do, What It Can’t, and How to Tell the Difference
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Who gets the AI productivity multiplier?
Clark: “demand for AI continues to outstrip compute supply” and “market incentives don’t guarantee best societal upside from limited AI compute.” The compute allocation question is who captures the multiplier.
“Figuring out how to allocate the acceleratory capabilities conferred by AI R&D will be a politically charged problem.“
superintelligence development kits
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Five dimensions Clark gestures at but leaves underdeveloped.
Clark’s closing section is rigorous on the corporate commitment evidence. Five strategic dimensions matter for the institutional response that the synthesis-level read argues is structurally inadequate.
FAILURE
CONSEQUENCES
RACE
INFRA GAP
Use corporate commitments as the input.
The corporate commitments are more concrete than the published forecasts. Plan to calendar markers, not to probability distributions.
POLICYMAKERS
INVESTORS
COGNITIVE WORKERS
RESEARCHERS
EVERYONE ELSE
The labs are building what they say they’re building. The forecast is the plan. The institutional response window is the only variable that remains unfixed.
I · The commitment cascade
Clark catalogs five distinct public commitments to automating AI R&D. The pattern across them is more significant than any individual commitment:
OpenAI · “automated AI research intern by September 2026”
Sam Altman’s October 28, 2025 statement. Eleven months from the publication date of Clark’s essay. Framed as a near-term product roadmap item with a specific calendar target, not as a research-aspirational direction. The specificity is the news. A “research intern” is the entry-level role that performs perspiration-heavy tasks in a research lab — running experiments, reading papers, summarizing results, implementing baselines. Automating this role is automating the substrate on which AI R&D operates. Altman is publicly committing OpenAI to having an AI system that performs the entry-level AI research role within eleven months.
If OpenAI hits the target, the implications cascade. The same capability that automates an AI research intern automates significant fractions of the broader cognitive workforce — anyone whose role involves reading, summarizing, implementing, and reporting. The September 2026 target is therefore not just an internal OpenAI milestone; it is a calendar marker for when a specific class of knowledge work becomes substantially automatable.
Anthropic · Automated Alignment Researchers
The research program is public. The proof-of-concept results documented in Outside Read 02 — AI agents beating human-designed baselines on scalable oversight — are the operational demonstration. The framing is “automate alignment research so we can scale alignment as fast as we scale capability.” The structural read is that Anthropic is internally building AI systems that do AI alignment research on AI systems. The recursive concern is real and operational, not hypothetical. The publication of the research program is part of the corporate strategic positioning — signaling capability while framing it as safety-positive.
DeepMind · “automation of alignment research should be done when feasible”
The arxiv paper (2504.01849) is the most circumspect of the three commitments. Note the language: not “we are building it” but “should be done when feasible.” This is the institutional equivalent of saying we will do this when we can — i.e., as soon as the capability exists. DeepMind is signaling the same objective with more careful timing language. The competitive dynamic forces this — once OpenAI and Anthropic publicly commit, DeepMind cannot credibly stay silent without being read as either behind or against the goal. Both readings are competitively damaging. The “when feasible” framing threads the needle.
Recursive Superintelligence · $500M raised
The lab is named for its goal. The $500M Series A is the most concrete signal of investor appetite for funding pure-play automated AI R&D bets. $500M for a single-purpose lab is institutional capital, not exploratory funding. The investors backing this are betting that automated AI R&D is achievable on a timeline where their capital deployment matters. That is itself a forecast — a financial-market forecast about when the technical milestone will be reached.
Mirendil · “building systems that excel at AI R&D”
The fifth commitment. A neolab with a specific mission. Less capital than Recursive Superintelligence but the same strategic objective. The category of “neolabs explicitly targeting automated AI R&D” is now a recognized investment thesis category. Multiple firms in this category implies multiple bets being made; each bet is a probability of success.
The pattern across commitments
Five organizations spanning the three major frontier labs plus two well-capitalized neolabs. The objective is consistent: automate AI R&D. Behind the named five: “hundreds of billions of existing and new capital” flowing toward this category, per Clark’s framing. Capital concentration around five specific organizations creates structural leverage — the success or failure of the goal is largely determined by what these five organizations achieve.
When the industry uniformly commits to a specific outcome and capital flows to support that outcome, the probability of the outcome occurring rises substantially — not by magic, but by the structural fact that thousands of researchers and engineers are deliberately working to produce it. The commitment cascade is the most concrete signal of how seriously the industry takes the objective.
II · The structural reframe · forecast vs plan
Here is the point that I think is under-developed in the public discourse around Clark’s essay.
Clark publishes a 60%+/2028 probability for automated AI R&D arrival. The forecast is calibrated to public benchmark data, observable trajectories, and the synthesis-level evidence the Clark series develops. The forecast reads as a probabilistic statement about what might happen.
But Clark works at Anthropic — one of the five organizations publicly committed to building automated AI R&D systems. The forecast is being published by a person whose company is explicitly trying to make the forecast come true. This is not a critique of Clark personally. It is a structural observation about what kind of statement the forecast actually is.
In standard scientific forecasting, the forecaster is an observer who doesn’t materially affect the system being forecast. A meteorologist forecasting Tuesday’s weather doesn’t change Tuesday’s weather. Clark’s situation is different. Clark is forecasting whether his company plus its peers will successfully execute a project they have publicly committed to executing. The forecast is endogenous to the system it forecasts.
Read this way: the 60%+/2028 number is not a probability estimate of a naturally-occurring phenomenon. It is a probability estimate of a corporate project being successfully completed by the organizations that have publicly committed to completing it. That’s a different kind of probability. It says: “the people whose job it is to build automated AI R&D systems estimate they have 60%+ probability of succeeding by end of 2028.”
Several structural implications follow:
The probability is partly a function of resource allocation, talent concentration, and capital availability — all of which can be influenced by the labs themselves. If Anthropic hires more alignment researchers, allocates more compute to automated R&D research, and aligns its product roadmap to the goal, the probability rises. The forecast is therefore partially under the labs’ control, not just an external observation.
The forecast becoming self-fulfilling is not coincidence; it is design. Publishing the forecast at 60%+/2028 signals corporate seriousness, recruits talent, attracts capital, and influences the competitive landscape — all of which raise the actual probability of execution. This is how strategic public commitments function across industries; AI is not exceptional except in scale.
External observers reading the forecast as “what might happen” are missing the corporate-strategic-objective dimension. The relevant question is not “is Clark’s probability estimate well-calibrated?” The relevant question is “given that the labs are committing to this objective, what should the institutional response be?” The second question has different answers than the first.
The 60%+/2028 is the “we believe we can hit this” number from the people trying to hit it. Translated from forecasting language to corporate language: this is the achievable-with-current-capacity target from the executives whose company is executing the project.
This doesn’t make Clark’s forecast wrong. It changes what the forecast is measuring. And the change in measurement matters for how the institutional response should be designed.
III · The capital scale, made concrete
Clark mentions “hundreds of billions of existing and new capital” without itemizing. Worth itemizing what’s verifiable from public sources:
Frontier lab valuations and capital raised in the 2024-2026 period:
- Anthropic at Q4 2026 IPO target valuation of approximately $900B — the IPO proceeds plus prior funding rounds total in the tens of billions
- OpenAI most recent secondary tender offer at $500B valuation; aggregate capital raised to date in the tens of billions
- xAI at approximately $200B valuation; multi-billion in capital raised
- Anthropic-SpaceX compute deal (the reckoning piece develops): undisclosed but multi-billion infrastructure commitment
Neolab capital specifically targeting AI R&D automation:
- Recursive Superintelligence: $500M Series A (named for the goal)
- Mirendil: undisclosed but Series A scale
- Reflection AI and similar agent-focused labs: $100M-$500M ranges
- Adjacent research-tool startups (developer tools, evaluation frameworks, agent infrastructure): aggregate $5-10B across the category
The compute infrastructure underpinning all of this:
- $500B+ in announced AI capex for 2024-2027 across all major sources (hyperscalers, chip vendors, infrastructure providers)
- Multi-gigawatt power capacity commitments
- Semiconductor capacity reservations and exclusive partnerships
The aggregate capital commitment for AI R&D-relevant activities in the 2024-2027 window is conservatively above $1 trillion across all major sources. The portion specifically targeted at AI R&D automation as a goal — versus AI capability expansion broadly — is harder to estimate but is at minimum $100B across the named labs and their funded research programs, with the broader category (including capex enabling these programs) substantially larger.
The capital scale is the most concrete signal of corporate seriousness. When the industry commits $100B+ to a specific goal, the goal gets pursued aggressively. When capital concentrates around five-to-seven specific organizations, those organizations become the structural lever for whether the goal is achieved. Outside-observer skepticism about whether the goal will be reached needs to engage with the capital scale, not just with the technical-capability evidence.
IV · Amdahl’s Law for the economy
Clark introduces a specific structural observation in his “Why this matters” section that I want to develop. Amdahl’s Law from computer architecture, applied to the economy.
The original Amdahl’s Law: the speedup of a system is bounded by the slowest serial component. If your program is 50% parallelizable and 50% serial, infinite parallelization doesn’t bring the runtime below 50% of the original. The slow part dominates.
Applied to the AI productivity multiplier: AI accelerates the cognitive-work components of the economy at unprecedented rates. But many parts of the economy are not cognitive-work-limited. AI does not accelerate (or accelerates much less) the following:
- Regulatory processes — drug trials, clinical trials, FDA approvals, environmental impact assessments, planning permission. Many of these have legally-mandated minimum durations.
- Physical infrastructure construction — data centers, semiconductor fabs, power generation, transmission lines, ports, factories. Construction cycles are years.
- Human institutional cycles — legislative sessions, court cases, treaty negotiations, multilateral agreements. Decision-making windows are months to years.
- Biological/chemical/physical processes — drug efficacy in human trials, material curing, plant growth, animal trials, accelerated aging tests. Biology and physics don’t negotiate.
- Trust-building and relationship development — clinical trial recruitment, customer acquisition in regulated industries, B2B enterprise sales cycles, multilateral consensus-building.
The result: as AI accelerates the cognitive-work layer, queues form at the non-cognitive layers. The drug pipeline becomes faster at candidate generation but the trial bottleneck doesn’t move. Legislative drafting becomes faster but political consensus-building doesn’t. Infrastructure planning becomes faster but construction doesn’t. Customer-acquisition copy becomes faster but B2B relationship building doesn’t.
This is structurally important and Clark introduces it but doesn’t develop it. Let me develop the implications:
For policy: the economic disruption from AI is concentrated rather than distributed. Software engineering, financial analysis, marketing, legal research, customer service — these sectors see massive acceleration. Pharmaceutical development, infrastructure construction, healthcare delivery, regulated industries broadly — these sectors see acceleration in some components but not others. Designing transition support without recognizing this differential will fail. The displaced workers are not uniformly distributed; they concentrate in the high-Amdahl-coefficient sectors.
For investors: sector-specific bets matter. Pure-cognitive-work sectors capture the productivity multiplier directly and rapidly. Physical-world-bottlenecked sectors capture it only partially and slowly. The differential creates investment opportunities and structural risks. The optimal portfolio reflects this differential rather than treating “AI exposure” as uniform.
For everyone: the Amdahl’s Law dimension is part of the answer to “why isn’t AI already producing visible aggregate economic acceleration.” The acceleration is real but concentrated in sectors where it’s hardest to observe at the aggregate-statistic level (cognitive worker productivity is not in the BLS CPI directly; the productivity gains show up in firm profitability rather than in GDP-per-capita statistics quickly). The aggregate acceleration shows up as the cognitive-work sectors grow faster, with a lag before the non-cognitive sectors catch up. The lag is long, structural, and uneven.
The Amdahl’s Law observation is one of Clark’s most operationally important contributions to the discourse. It deserves substantial elaboration in the policy and economic-analysis communities. The current discourse treats AI productivity gains as broadly distributed; the structural reality is that they are concentrated by sector and bounded by the slowest non-cognitive component.
V · The compute allocation question · political economy
Clark introduces a second specific point: “demand for AI continues to outstrip compute supply” and “market incentives don’t guarantee best societal upside from limited AI compute.” The compute allocation question.
This is a political economy claim of substantial significance. The compute allocation question is who gets the AI productivity multiplier.
The current allocation mechanism is a priced market. Compute capacity goes to whoever can pay for it. The pricing reflects what compute is most valuable for, which is currently a mix of:
- Capability-frontier training (massive, concentrated at major labs)
- Enterprise applications (mid-tier compute, fragmented across thousands of buyers)
- Consumer applications (lower-tier compute, concentrated at consumer AI app providers)
- Research and academic use (smallest tier, allocated through institutional channels)
Within the current price-market mechanism, individual researchers and small organizations get less compute per dollar than frontier labs (who get bulk discounts and reservation pricing). Hyperscalers capture most of the producer surplus. Compute is allocated efficiently from a market perspective but not necessarily optimally from a social-good perspective.
The structural question Clark raises: is the market allocation optimal for the social good? Several reasons to share his skepticism:
- Capability-frontier training captures most compute supply, displacing potentially more socially valuable applications (climate modeling, drug discovery, education delivery, public health research)
- Enterprise applications are priced by enterprise budgets, which don’t reflect social externalities — a marketing-optimization use case can outbid a public-health use case even though the public-health use case has higher social utility
- Consumer applications get whatever’s left, which may underweight downstream productivity gains (developing-country productivity tools, accessibility applications, educational AI for under-resourced contexts)
- The frontier-lab oligopoly captures most of the producer surplus, not consumers — the productivity gains from AI flow disproportionately to the small number of organizations operating the systems
The policy question Clark gestures at: should there be a public-interest compute allocation mechanism? Examples from other domains:
- Public-interest broadcasting spectrum allocation (FCC rules requiring public-purpose spectrum use)
- Public-purpose water rights (allocations carved out for public use even in market-based systems)
- Anchor-customer commitments in renewable energy (public funding for early-stage capacity to lower long-run costs)
- National Science Foundation grant funding for compute-intensive research
The infrastructure for a public-interest compute allocation system does not currently exist for frontier AI compute. Building it would be substantial institutional work — operating on the same 32-month window the synthesis piece describes. The work hasn’t started in any major jurisdiction. The institutional response gap is wide on this dimension specifically.
The Amdahl’s Law dimension interacts with the compute allocation question. If AI productivity is differentially distributed by sector, the compute allocation choice has differential downstream consequences. Allocating compute to high-Amdahl-coefficient sectors (pure cognitive) versus low-Amdahl-coefficient sectors (physical/regulatory-bottlenecked) produces different aggregate economic outcomes. The current market allocation does not optimize for this differential. A public-interest allocation mechanism could; a market-only mechanism cannot.
VI · What Clark doesn’t develop at the closing-section level
Five strategic dimensions Clark gestures at but doesn’t develop:
1 · The lab racecourse dynamic
When five labs publicly commit to automating AI R&D, no individual lab can credibly delay without losing the race. The competitive dynamic forces each lab to push capability deployment even if they would individually prefer to slow down. The Anthropic CEO can say “we’d prefer to be more cautious” but cannot operationalize that preference without ceding the race to less-cautious labs. The coordination problem is the binding institutional issue, and it is structurally unsolvable without external coordination mechanisms that don’t currently exist at scale.
2 · The Anthropic-as-author dimension
Clark works for Anthropic. Anthropic is one of the labs publicly committed to building automated AI R&D systems. The essay is published in the Anthropic IPO disclosure preparation window. The essay is itself part of Anthropic’s strategic positioning. This doesn’t make it wrong; it makes it part of the corporate strategy. The strategic functions the essay performs: signaling capability awareness to investors, demonstrating policy seriousness to regulators, recruiting talent who care about alignment, framing Anthropic as the responsible operator within the racing dynamic, establishing intellectual leadership in the discourse. Public discourse about the essay should account for this dimension while still engaging with its substantive content (which is real and important).
3 · The political economy of the productivity multiplier · who captures the value?
Who captures the value from AI R&D automation? The current value-capture distribution:
- Frontier labs: via products, services, and IPO realization. Anthropic’s $900B target valuation is the most concrete signal of expected value capture.
- Venture investors: via stake appreciation at the labs and adjacent companies
- Big Tech infrastructure providers: via compute reselling and platform fees
- Large enterprise customers: via productivity gains they internalize
What’s not currently in the value-capture mix:
- Workers displaced by automation (especially junior cognitive workers — see labor displacement reality-check)
- Smaller organizations that lack AI deployment capacity
- Sectors with low Amdahl coefficients that get partial benefits with full disruption
- The public broadly — taxpayers funding the infrastructure (power, fiber, regulatory administration) that enables the productivity gains
The capital concentration is producing distributional consequences that current institutions are not equipped to manage. The corporate income tax base, the labor income tax base, the consumption tax base, the social insurance financing base — all of these depend on distributional patterns that the AI productivity multiplier disrupts.
4 · The geopolitical dimension
The five corporate commitments described are all US-domestic (or US-aligned: DeepMind is UK-based but operates within the US technology ecosystem). Chinese frontier labs are pursuing the same goal. DeepSeek, Qwen, Zhipu, and Moonshot have public capability commitments that parallel the US labs’ commitments. The competition isn’t just intra-US lab competition; it is US-China strategic competition with the same structural dynamics as the intra-US lab race but at the geopolitical scale.
The Bureau of Industry and Security export controls regime is the institutional mechanism for managing this. The regime is structurally inadequate to the cadence required — export controls operate on 6-18 month policy cycles; capability progresses on 4-6 month cycles. The mismatch is the binding constraint on US-China coordination. And US-China coordination is the binding constraint on any global coordination mechanism for AI R&D automation.
5 · The verification dimension
When the corporate objective is “build automated AI R&D systems,” how do external observers verify the claims? The benchmark scores are public but interpretation requires expertise. The internal capabilities are proprietary. The downstream consequences (alignment risk, economic disruption, geopolitical implications) are not observable until they materialize.
The current verification infrastructure relies on voluntary disclosure plus academic study of public artifacts. Neither is adequate to verify claims about systems that don’t exist yet but are being built. The institutional development needed: third-party audit capacity, technical infrastructure for evaluating frontier capabilities, regulatory disclosure frameworks, and international verification protocols. None of these exist at the scale the cadence requires.
VII · Stakeholder implications
Specific implications by audience:
For policymakers: the corporate commitments are the most concrete signal of what the labs are building toward, on what timeline, with what capital. Policy planning should use the corporate commitments as the input, not the published forecasts as the input. OpenAI’s September 2026 target for the AI research intern is a calendar marker. Anthropic’s IPO timing is a calendar marker. The 32-month window the synthesis piece describes is bounded by these calendar markers. Build the framework now.
For investors: the capital concentration around five-to-seven organizations creates concentrated exposure. The right investment thesis is not “AI is going to be big” — the right thesis is “specific entities are committing to specific goals on specific timelines with specific capital.” Position relative to those specifics, not relative to the broad theme. Compute supply governance, the Amdahl’s Law differential by sector, and the public-interest compute allocation question are all underweighted in current investment frameworks.
For workers in cognitive-work sectors: the corporate commitment to “automated AI research intern by September 2026” is a calendar marker for when entry-level cognitive work in research-intensive contexts becomes substantially automatable. The signal generalizes — the capability that automates an AI research intern automates significant fractions of broader entry-level cognitive work. Adjust career planning to the calendar marker. The labor displacement reality-check documents the current state; the corporate commitments tell you where it is going.
For AI safety and alignment researchers: the corporate commitments accelerate the timeline. The alignment research community has 11-32 months to develop the techniques needed for systems being built on those timelines. The Anthropic Automated Alignment Researchers program is one institutional response; it has its own recursive concerns (per Outside Read 02). The alignment community needs to engage with the corporate commitment landscape, not just with the technical capability question — because the corporate commitments determine when the techniques are needed in production.
For everyone else: the corporate commitment cascade is the most concrete signal yet that the AI transition is operational rather than aspirational. When five organizations representing hundreds of billions in capital publicly commit to a specific objective with calendar targets, the objective is being executed. The institutional response window is the time before the calendar targets are reached. The window is short. Engagement with the political-economy questions raised by the cascade — compute allocation, value capture, Amdahl’s Law differentials, verification infrastructure — has higher leverage during the window than after.
VIII · The structural read · series close
This piece closes the three-piece Outside Read series on Clark’s Import AI #455. The structural reads across the three pieces:
Outside Read 01 · The Coding Singularity argued the coding capability is real and steeper than Clark presented, with coding as the wedge into recursive self-improvement. The labor market consequence is empirical, not theoretical. The substantive event is not the coding part but the recursive loop the coding makes operational.
Outside Read 02 · Engineering Is Automated. Research Is the Residual argued the six skill benchmarks are converging on saturation; engineering is automated; research is the residual question. The residual may not be a permanent moat — inspiration may be compressed perspiration, dissolving with sufficient automation volume. The institutional response should not bet on inspiration being a permanent moat.
Outside Read 03 · The Forecast Is the Plan argues Clark’s 60%+/2028 forecast is structurally a corporate plan, not a probability estimate. The five-organization commitment cascade plus capital scale plus calendar targets plus competitive dynamics plus geopolitical positioning make the forecast endogenous to the system it describes. The labs are building what they say they’re building. The institutional response window is the time before the calendar targets are reached.
Aggregate structural read across all three pieces plus the five-piece Clark Series: the Clark essay catalogs the public evidence base for automated AI R&D by 2028 from a co-founder of one of the labs publicly committed to building it. The capability data supports the trajectory. The deployment data confirms the operational deployment. The labor market data shows the consequences are empirical. The corporate commitment cascade reveals the forecast as the corporate plan. The capital scale signals corporate seriousness. The competitive dynamics force continued execution. The geopolitical layer compounds the coordination problem. The verification infrastructure to evaluate any of this is inadequate.
Eight pieces in the franchise. Same window. Same structural finding. The next 32 months are bounded by corporate calendar targets and the Clark forecast resolution date. The institutional capacity to respond is structurally inadequate. What gets built during the window — alignment research, coordination mechanisms, transition support, compute allocation frameworks, verification infrastructure, political-economy reform — determines what the equilibrium on the other side looks like.
The Clark essay is published. The corporate commitments are public. The capital cascade is observable. The trajectory is steeper than presented and is being pursued by the people forecasting it. The labor market consequence is empirical. The institutional response window is the only remaining variable that can still be shaped.
That is what the next 32 months are for.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Related Reading
- The Coding Singularity Outside Read · Piece 1 of the Outside Read series
- Engineering Is Automated. Research Is the Residual. · Piece 2 of the Outside Read series
- Jack Clark Says It Out Loud · 60%/2028 statement · Clark Series 1
- The Benchmark Saturation Cascade · Clark Series 2
- The Compounding Error Problem · Clark Series 3
- The Machine Economy · Clark Series 4
- The Co-Founder’s Black Hole · Clark Series 5 Synthesis
- The State of AI Replacing Jobs in 2026
- The Compute Reckoning · Anthropic-SpaceX
- Post-Labor Economics franchise
Sources
- Jack Clark · Import AI 455: Automating AI Research · “Why this matters” section · May 4, 2026 · jack-clark.net
- Sam Altman · “automated AI research intern by September 2026” · x.com/sama/status/1983584366547829073 · October 28, 2025
- Anthropic · Automated Alignment Researchers research program · anthropic.com/research/automated-alignment-researchers
- DeepMind · “automation of alignment research should be done when feasible” · arxiv.org/abs/2504.01849
- Recursive Superintelligence · $500M Series A · Financial Times · ft.com
- Mirendil · “building systems that excel at AI R&D” · mirendil.com
- Anthropic IPO preparation reporting · multiple sources · Q4 2026 target
- OpenAI valuation: $500B secondary tender · 2026
- xAI valuation: ~$200B · 2026
- AI capex commitments: hyperscaler announcements 2024-2026
- Bureau of Industry and Security · semiconductor export controls regime
- Chinese frontier lab capability data: DeepSeek, Qwen, Zhipu, Moonshot
- Gene Amdahl · Validity of the single processor approach to achieving large scale computing capabilities · 1967







