

Thorsten Meyer | ThorstenMeyerAI.com | February 2026
Executive Summary
Human-in-the-loop is no longer just a defensive safeguard. Done well, it becomes a performance architecture that improves quality, compliance, and throughput. The shift in 2026 is from ad hoc human review to structured intervention design with measurable decision rights.
68% of organizations plan to integrate autonomous or semi-autonomous AI agents into core operations by 2026 (Protiviti). 80% of enterprises will have deployed generative AI by 2026 (Gartner). But 71% of IT leaders say AI speed conflicts with governance enforcement, and ~50% of AI projects fail prototype-to-production — often because oversight was designed as a bottleneck rather than a system.
The organizations that get this right don’t choose between speed and control. They design intervention architectures where humans add value at specific decision points — and AI handles the rest with bounded autonomy.
| Metric | Value |
|---|---|
| Organizations integrating AI agents by 2026 (Protiviti) | 68% |
| Enterprises deploying GenAI by 2026 (Gartner) | 80% |
| AI projects failing prototype-to-production | ~50% |
| IT leaders: speed-governance conflict (OneTrust) | 71% |
| Companies scrapping AI initiatives (S&P, 2025) | 42% |
| Online content AI-generated by 2026 | 90% (Gartner) |
| Organizations with AI governance boards | 55% |
| Mature orgs with dedicated AI teams | 67% |
| Work tasks handled by humans (2026) | 47% |
| Work tasks handled by machines (2026) | 22% |
| Work tasks requiring both (2026) | 30% |
| Leaders: need to teach “thinking with machines” | 57% |
| Productivity growth in AI-exposed industries | 7% (2018–2022) to 27% (2018–2024) |
| AI contribution to global economy by 2030 (PwC) | $15.7 trillion |
| CX leaders integrating GenAI by 2026 | 70% |
| AI-related bills in US (2024) | 700+ |
| New AI proposals (early 2026) | 40+ |
| Organizations targeting AI agent deployment within 1 year | 50%+ (Protiviti) |
| Advanced orgs using agents for repetitive tasks | 77% (Protiviti) |
| C-suite expecting semi-autonomous agents | 37% |
| C-suite expecting fully autonomous agents | 31% |
| Mid-level staff expecting full autonomy | 17% |
| Organizations planning fully autonomous agents within 1 year | 20% (Protiviti) |
| Unauthorized AI transactions from internal violations (Gartner) | 80%+ |
| Agentic AI projects expected to fail by 2027 (Gartner) | 40%+ |
| EU AI Act high-risk provisions fully applicable | August 2026 |

AI Governance for Practitioners: Risk Classification, Policy Development, Vendor Assessment, Human Oversight, and Audit Readiness (AI for Everyone Book 16)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
1. Why the Old HITL Model Is Breaking
Human-in-the-loop was designed for a simpler era: a human reviews an AI output before it reaches the customer. That model assumed manageable volume, clear review criteria, and bounded decision complexity. All three assumptions have collapsed.
The Scale Problem
A single fraud model evaluates millions of transactions per hour. A recommendation engine influences billions of interactions per day. AI systems make millions of decisions per second across fraud detection, trading, personalization, logistics, and cybersecurity. The idea that humans can meaningfully supervise AI one decision at a time is no longer realistic at production scale.
The Bottleneck Problem
When HITL is implemented as “review everything,” it becomes the constraint that limits the system’s value. 71% of IT leaders say AI speed conflicts with governance enforcement. The result: review queues grow, latency increases, operators develop review fatigue, and the quality of human oversight degrades precisely when it matters most.
The Accountability Gap
Poor HITL design creates three dysfunctions:
| Dysfunction | Symptom | Consequence |
|---|---|---|
| Review bottleneck | Queue grows faster than humans can clear it | Speed advantage of AI is negated |
| Responsibility confusion | No one knows who owns the override decision | Errors propagate without accountability |
| False confidence in autonomy | “A human reviewed it” = assumed correctness | Quality issues hidden behind review checkbox |
| Rubber-stamping | Overwhelmed reviewers approve without scrutiny | HITL exists in name only |
The leadership perception gap reinforces the problem: 37% of C-suite executives expect semi-autonomous agent integration and 31% foresee fully autonomous implementations — but only 17% of mid-level and operational staff anticipate full autonomy. The people closest to the work see the oversight challenges that the boardroom doesn’t.
The Regulatory Trigger
The EU AI Act (Article 14) mandates human oversight for high-risk AI systems. By August 2026, the majority of provisions become fully applicable across healthcare, finance, employment, and critical infrastructure. Over 700 AI-related bills were introduced in the US in 2024, with 40+ new proposals in early 2026. HITL is no longer a design preference. It’s a legal requirement — and the question is whether your design satisfies it or merely gestures at it.

In the Loop: The Human Touch in AI: Trust, Oversight and Leadership
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
2. HITL 2.0: The Operating Model
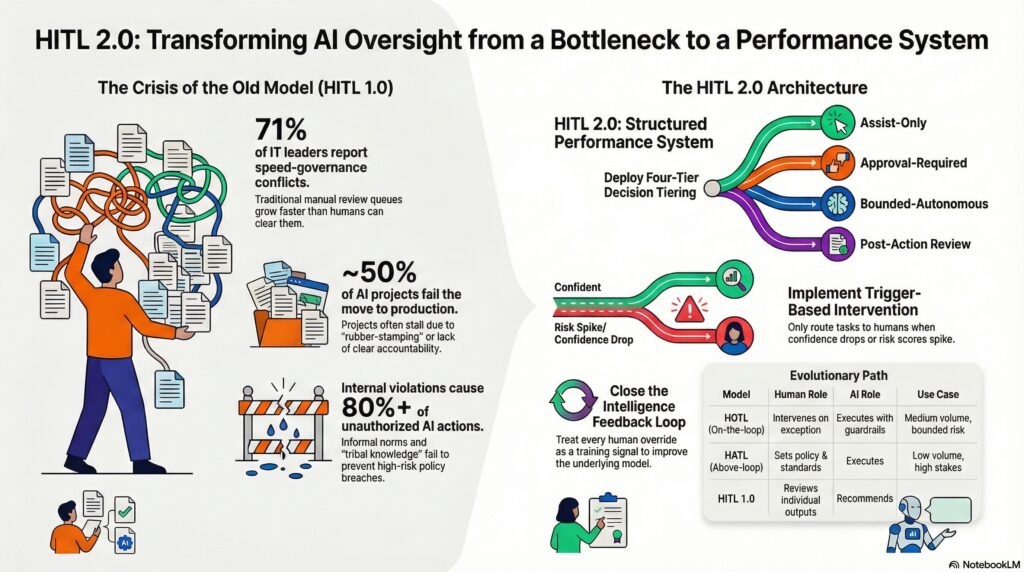
HITL 2.0 replaces ad hoc review with four structural components: decision tiering, trigger-based intervention, role clarity, and feedback loops.
Component 1: Decision Tiering
Not all decisions require the same level of oversight. The operational model must define which actions are:
| Autonomy Tier | Description | Example | Human Role |
|---|---|---|---|
| Assist-only | AI drafts, human decides | Legal clause generation, clinical recommendations | Decision maker |
| Approval-required | AI acts only after human confirms | Contract commitments, payments above threshold | Approver |
| Bounded-autonomous | AI acts within defined limits; escalates exceptions | Routine customer inquiries, low-risk transactions | Exception handler |
| Post-action review | AI acts autonomously; human reviews after the fact | Content moderation at scale, anomaly flagging | Auditor |
Risk stratification maps actions into these tiers based on data sensitivity, error consequences, and regulatory requirements. Low-risk analytics may run without human involvement. High-value decisions must have qualified experts in the loop.
77% of advanced-stage organizations already use agents for repetitive tasks (Protiviti). The design question is which tasks remain in which tier — and what triggers movement between tiers.
Component 2: Trigger-Based Intervention
Humans intervene based on conditions, not random sampling alone. The intervention trigger replaces calendar-based review with signal-based routing.
| Trigger Type | What It Detects | Action |
|---|---|---|
| Confidence threshold | Model output below defined certainty | Route to human for decision |
| Risk score | Transaction or action exceeds risk threshold | Require approval before execution |
| Anomaly detection | Behavior deviates from historical patterns | Flag for human investigation |
| Policy boundary | Agent action approaches scope limit | Pause and escalate |
| Escalation chain | Lower-tier reviewer cannot resolve | Route to senior decision-maker |
| Volume spike | Unusual surge in automated actions | Activate enhanced oversight |
This is the shift from “review everything” to “review what matters.” When an issue falls outside predefined criteria — policy exceptions, data sensitivity, low confidence — the agent pauses and routes the case to a human owner with full context, reducing manual workload without removing accountability.
Component 3: Role Clarity
HITL fails when “a human is involved” but no one knows which human, with what authority, and what decision rights.
| Role | Responsibility | Authority | Accountability |
|---|---|---|---|
| Operator | Monitors AI execution; handles routine escalations | Can pause, adjust within tier | Operational accuracy |
| Approver | Authorizes high-stakes AI actions | Can approve, reject, modify | Decision quality |
| Incident owner | Manages failures, breaches, unexpected outputs | Can contain, remediate, disclose | Incident resolution |
| Policy owner | Defines rules, thresholds, tier boundaries | Can change autonomy levels | Governance integrity |
57% of organizational leaders report needing to teach employees “how to think with machines.” This isn’t about AI literacy in the abstract. It’s about training operators to make effective override decisions, approvers to evaluate AI-generated evidence, and incident owners to respond within defined SLAs.
Component 4: Feedback Loops
Review outcomes must flow back into the system. Every human override, escalation, and correction is a data point that should improve prompts, policy rules, and workflow design.
| Feedback Signal | What It Improves |
|---|---|
| Override patterns | Prompt engineering, model fine-tuning |
| Escalation clusters | Trigger threshold calibration |
| False-positive corrections | Confidence scoring accuracy |
| Incident post-mortems | Policy boundary definitions |
| Approval rejection reasons | Workflow design, training data |
Without feedback loops, HITL is a one-way gate. With them, it’s a learning system that gets better at allocating human attention where it creates the most value.

The HUMAN Agentic AI Edge: Shape the Next Generation of AI-Ready Teams
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
3. Metrics That Matter
HITL 2.0 must be instrumented. If you can’t measure intervention quality, you can’t improve it.
| Metric | What It Measures | Target Direction |
|---|---|---|
| Override rate | % of AI decisions reversed by humans | Declining (as AI improves) |
| Escalation latency | Time from trigger to human response | Decreasing |
| False-positive intervention rate | Unnecessary escalations | Decreasing |
| False-negative intervention rate | Missed cases that should have been escalated | Decreasing |
| Post-review defect rate | Errors found after human review passed the output | Decreasing |
| Customer/citizen impact incidents | Failures that reach end users | Near zero |
| Rubber-stamp rate | Approvals with <N seconds of review time | Decreasing |
| Feedback loop closure time | Time from review outcome to system improvement | Decreasing |
| Tier migration rate | Actions moving to higher/lower autonomy tiers | Stable or shifting toward autonomy |
These are not compliance metrics. They are operational performance indicators. The override rate tells you whether the AI is improving. The escalation latency tells you whether the human system is responsive. The false-positive rate tells you whether you’re wasting human attention. The rubber-stamp rate tells you whether the HITL is real or performative.

LLMs and Generative AI for Healthcare: The Next Frontier
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
4. The “Humans Above the Loop” Evolution
The most advanced organizations are moving beyond human-in-the-loop to “humans above the loop” — where people provide judgment, direction, and standards while AI handles execution and routine oversight.
This is not removing humans. It’s repositioning them.
| Model | Human Role | AI Role | Where It Works |
|---|---|---|---|
| Human-in-the-loop (HITL 1.0) | Reviews individual AI outputs | Recommends | Low volume, high stakes |
| Human-on-the-loop (HOTL) | Monitors AI systems; intervenes on exception | Executes with guardrails | Medium volume, bounded risk |
| Human-above-the-loop (HATL) | Sets policy, architecture, standards | Executes + monitors | High volume, mature governance |
The transition is not binary. Most organizations will operate multiple models simultaneously — HITL for high-stakes decisions, HOTL for operational processes, HATL for routine automation. The design discipline is knowing which model applies to which workflow.
68% of organizations plan to integrate AI agents by 2026, but only 20% plan fully autonomous deployment within one year. The gap is the governance architecture. Bounded autonomy — agents acting where outcomes are predictable, with human oversight where risk or uncertainty increases — is the practical model for 2026.
The workforce data confirms the transition: humans handle 47% of work tasks, machines 22%, with 30% requiring both. The “both” category is where HITL 2.0 creates its value — not by slowing down the 22% or automating the 47%, but by making the 30% faster, more accurate, and more accountable.
5. Practical Implications and Actions
Action 1: Build Autonomy Tiers per Workflow Before Scaling
Don’t scale AI and retrofit oversight. Define the four tiers — assist-only, approval-required, bounded-autonomous, post-action-review — for each workflow before deployment. The 42% of companies that scrapped AI initiatives in 2025 overwhelmingly failed at this step: they deployed AI without structural oversight, discovered governance gaps in production, and retreated.
Action 2: Define Intervention Triggers in Policy, Not Tribal Knowledge
If the only people who know when to escalate are the two operators who have been doing it longest, the HITL is fragile. Encode triggers: confidence thresholds, risk scores, anomaly flags, policy boundaries. Make them machine-readable. Make them auditable. 80%+ of unauthorized AI transactions come from internal policy violations (Gartner). Written triggers prevent the violations that informal norms allow.
Action 3: Instrument Review Outcomes and Feed Them Back
Every override is a training signal. Every false positive is a calibration opportunity. Every incident is a policy refinement input. If your HITL system generates review decisions but doesn’t feed them back into the AI system, workflow rules, and trigger thresholds, you’re paying for human attention without capturing its intelligence.
Action 4: Avoid “Review Everything” Designs That Collapse Speed
Productivity growth in AI-exposed industries jumped from 7% (2018–2022) to 27% (2018–2024). “Review everything” designs surrender this productivity gain. Tier your oversight. Reserve human attention for the decisions that require human judgment. Automate the rest with bounded autonomy and post-action audit.
Action 5: Audit HITL Effectiveness Quarterly
The metrics — override rate, escalation latency, false-positive rate, rubber-stamp rate — should be reviewed quarterly, not annually. Patterns shift as AI systems improve, data distributions change, and regulatory requirements evolve. An effective HITL at Q1 may be a bottleneck or a rubber-stamp by Q3 if not recalibrated.
6. What to Watch
HITL frameworks in regulated procurement. The EU AI Act mandates human oversight for high-risk systems by August 2026. NIST AI RMF’s Govern/Map/Measure/Manage pillars are becoming procurement criteria. Expect HITL architecture to become a standard vendor evaluation dimension — not as a checkbox, but as an auditable operating model.
Dynamic intervention routing tooling. Confidence-based routing, anomaly-triggered escalation, and context-aware assignment are moving from custom builds to platform features. The HITL platform market will grow as organizations move from “we have oversight” to “our oversight is instrumented and optimized.”
From compliance-only review to quality-and-speed optimization. The best HITL 2.0 implementations don’t just prevent bad outcomes. They accelerate good ones — by routing human attention to where it creates the most value, capturing feedback that improves the system, and measuring intervention quality with the same rigor as model accuracy. HITL becomes a performance system, not a compliance ritual.
The Bottom Line
Human-in-the-loop was designed as a safety net. In 2026, it needs to be a performance system — with decision tiers, trigger-based intervention, explicit role assignments, and feedback loops that make the system smarter with every human interaction.
68% of organizations plan AI agent integration by 2026. 80%+ of unauthorized AI transactions come from internal policy violations. 47% of tasks remain human, 30% require human-machine collaboration. The architecture of that collaboration — not the AI model itself — determines whether the organization captures the productivity gains or drowns in review queues.
The question is no longer whether humans stay in the loop. It’s whether the loop is designed to make them effective — or just present.
Thorsten Meyer is an AI strategy advisor who has observed that the fastest-scaling enterprise AI systems in 2026 have one thing in common: they don’t ask humans to review everything — they ask humans to review the right things, at the right time, with the right authority. More at ThorstenMeyerAI.com.
Sources
- Protiviti — 68% AI Agent Integration by 2026 (AI Pulse Survey, August 2025)
- Gartner — 80% Enterprises Deploying GenAI by 2026
- Gartner — 80%+ Unauthorized AI Transactions from Internal Violations
- Gartner — 40%+ Agentic AI Projects Fail by 2027
- OneTrust — 71% Speed-Governance Conflict (1,250 IT Leaders, 2025)
- S&P Global — 42% AI Initiative Abandonment (2025)
- Parseur — Future of HITL AI: 55% Governance Boards, 67% Dedicated AI Teams
- Parseur — Workforce Task Distribution: 47% Human, 22% Machine, 30% Both
- PwC — AI Contribution $15.7 Trillion by 2030
- Diginomica — 2026: From Human-in-the-Loop to Humans-Above-the-Loop
- SiliconAngle — Human-in-the-Loop Has Hit the Wall
- Illumination Works — Adaptive Human-in-the-Loop: Bounded Autonomy
- EU AI Act Article 14 — Human Oversight for High-Risk Systems (August 2026)
- NIST AI RMF — Govern, Map, Measure, Manage
- EMA — Agentic AI Trends 2026: Bounded Autonomy
- Machine Learning Mastery — 7 Agentic AI Trends 2026
- Kore.ai — AI Agents 2026: From Hype to Enterprise Reality
- CNCF — Autonomous Enterprise: Four Pillars of Platform Control
- Knight First Amendment Institute — Levels of Autonomy for AI Agents
- EDPS — Human Oversight of Automated Decision-Making (TechDispatch, 2025)
- Scoop Analytics — HITL: Secret to Responsible AI in 2026
- Plain — Agentic Support Stack 2026
- Samta.ai — 8 HITL AI Platforms for Governance 2026
- Holistic AI — Keeping AI Aligned with Human Values
- Sombra — AI Regulations and Governance Guide 2026
© 2026 Thorsten Meyer. All rights reserved. ThorstenMeyerAI.com







