Thorsten Meyer | ThorstenMeyerAI.com | February 2026
Executive Summary
Mid-market firms are adopting AI fastest when projects are fixed-scope, fast-cycle, and outcome-measurable. 95% of generative AI pilots fail to deliver ROI (MIT). 88% of AI pilots never reach production (IDC). Only 27% of companies successfully move AI from testing to implementation (Concentrix/Everest). But mid-market companies that run focused, bounded pilots scale in 90 days — versus nine months for large enterprises.
The mid-market advantage is real: smaller teams, faster decisions, less bureaucratic friction. The mid-market constraint is also real: $50K–$200K pilot budgets, no dedicated AI teams, and zero tolerance for platform sprawl. That combination demands precision execution — not broad “transformation” programs, but fixed-scope pilots with clear boundaries, decision gates, and measurable outcomes.
This article is a 6-week blueprint for mid-market AI pilots that produce scale-or-stop decisions backed by evidence, not enthusiasm.
| Metric | Value |
|---|---|
| GenAI pilots failing (MIT) | 95% |
| AI pilots never reaching production (IDC) | 88% |
| Companies: testing to implementation (Concentrix) | 27% |
| AI projects: pilot-to-production failure | ~50% |
| Companies generating no value from AI (BCG) | 60% |
| Enterprises: scaled beyond pilot | <40% |
| Mid-market scale timeline | ~90 days |
| Enterprise scale timeline | ~9 months |
| AI in at least one function | 78% of organizations |
| GenAI in at least one function | 71% of organizations |
| Mid-market pilot budget range | $50K–$200K |
| Companies maximizing existing tools: savings | 40–60% less |
| External partners: success rate vs. internal | ~2x |
| Purchased AI success rate (MIT) | 67% |
| Internal AI build success rate (MIT) | 33% |
| Simple automation: breakeven | 6–8 weeks |
| Initial productivity gains | 30–60 days |
| ROI for well-designed implementations | 3–6 months |
| AI market (2025) | $391 billion |
| AI market (2030 projected) | $1.81 trillion |
| ROI per dollar invested in GenAI | 3.7x |
| Organizations with AI risk functions | 80% |
| Employees stuck in early adoption | 85%+ |
| Workers uncomfortable admitting AI use | 48% |
| Workers anxious about AI replacement | 65% |
| Companies with AI education for employees | 39% |
| Workforce: high AI readiness | 8% |
| Workers saving 52–60 min daily with AI | Average |

AI for Product Managers: The Step-by-Step Playbook for Using AI in Your Product Management Workflow and Landing the Most In-Demand Role in Tech (AI for UX Designers™)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
1. Why Mid-Market Is the AI Adoption Battleground
The mid-market — firms with $10M to $1B in revenue and 100 to 2,000 employees — is where AI adoption produces the starkest outcomes. The constraints are real, but the advantages are structural.
The Mid-Market Advantage
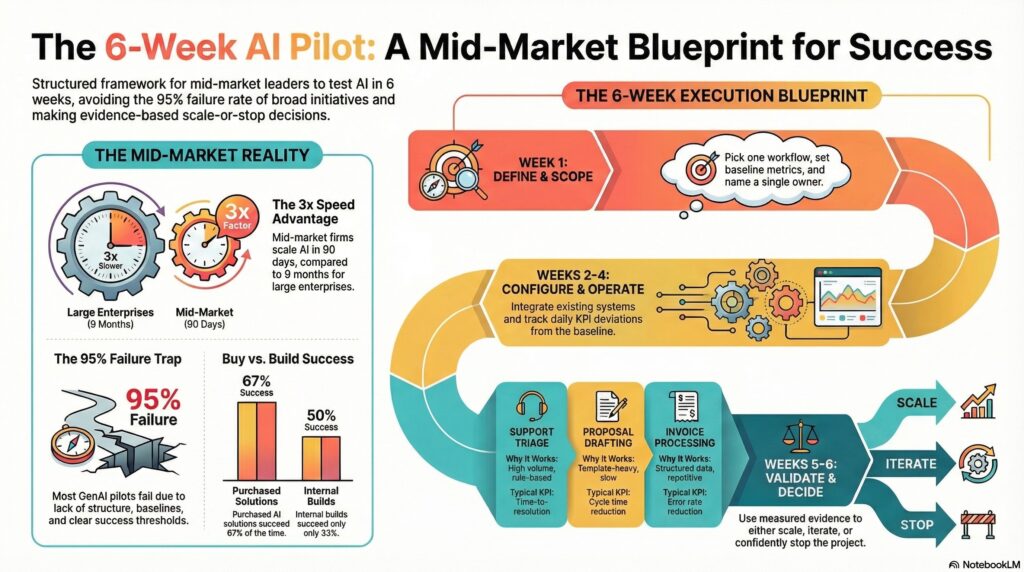
Mid-market organizations have the agility to deploy pilots in weeks rather than quarters. 2026 marks the inflection point where mid-market velocity surpasses enterprise scale. Large enterprises run the most pilots but take nine months on average to scale. Mid-market firms scale in approximately 90 days — three times faster.
The reason is organizational, not technological: fewer approval layers, shorter feedback loops, direct access to decision-makers, and workflows that are concrete enough to measure.
The Mid-Market Constraint
| Constraint | Enterprise | Mid-Market |
|---|---|---|
| AI budget | $1M–$50M+ | $50K–$200K |
| Dedicated AI team | Yes (67% of mature orgs) | Rarely |
| Change management dept. | Yes | No |
| Tolerance for failed pilots | Multiple attempts | Often one shot |
| Platform strategy | Multi-vendor, integrated | Must work with existing tools |
| Scale timeline (avg.) | ~9 months | ~90 days |
When a 75-employee company’s first AI pilot fails, they often lack the expertise to diagnose why and the budget to try again. 85%+ of employees remain stuck in early adoption stages due to lack of behavior change strategies. Only 39% received company-provided AI education. 48% feel uncomfortable admitting AI use to managers.
This is why fixed-scope pilots matter. The mid-market can’t afford broad exploration. It needs bounded bets with clear evidence.
The Failure Pattern
| Failure Data | Source |
|---|---|
| 95% of GenAI pilots fail to deliver ROI | MIT GenAI Divide |
| 88% of AI pilots never reach production | IDC |
| 60% generate no material value from AI | BCG |
| Only 4 of 33 pilots reach production | IDC |
| 27% moved from testing to implementation | Concentrix/Everest |
| Only one-third achieve enterprise-wide scaling | McKinsey |
| 42% of companies scrapped most AI in 2025 | S&P Global |
The pattern: organizations buy AI through broad mandates, pilot without structure, measure without baselines, and can’t distinguish success from noise. Fixed-scope pilots break this pattern by defining success before the work begins.

Designing Multi-Agent Systems: Principles, Patterns, and Implementation for AI Agents
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
2. The 6-Week Pilot Structure
Six weeks is not arbitrary. Simple automation agents break even within 6–8 weeks. Initial productivity gains emerge in 30–60 days. Well-designed implementations show positive ROI in 3–6 months. The 6-week structure creates a decision point before the organization commits to scale — or discovers it shouldn’t.
Week 1: Define
The most important week. Everything that follows depends on what gets scoped here.
| Define Element | What It Means | Anti-Pattern to Avoid |
|---|---|---|
| Pick one workflow | Single process, end-to-end | “AI across customer experience” |
| Set baseline metrics | Current error rate, cycle time, cost per unit | No baseline = no measurement |
| Define success threshold | Specific, quantified improvement target | “Improve efficiency” |
| Name single owner | One person with decision authority | Committee ownership |
| Document exclusions | What’s explicitly not in scope | Scope creep by Week 3 |
The one-page pilot charter captures: workflow, KPI, success threshold, risk controls, timeline, owner, exclusions, and stop criteria. One page. Not a 40-page business case.
Week 2: Configure
| Configure Element | Purpose |
|---|---|
| Integrate minimum required systems | Only what the pilot needs — no platform build-out |
| Set policy and human checkpoints | Define what the AI can/cannot do; where humans review |
| Establish monitoring | Automated tracking of KPIs from day one |
| Prepare manual fallback | If AI fails, the workflow continues without disruption |
| Train operators | Not AI literacy — specific operational procedures |
Companies maximizing existing tools spend 40–60% less than those deploying new platforms. The Week 2 principle: integrate, don’t build. Use existing infrastructure where possible. Expand only after proof.
Weeks 3–4: Operate
Live operation in controlled mode. This is where the data accumulates.
| Operating Discipline | What It Requires |
|---|---|
| Daily KPI tracking | Automated dashboard, not weekly reports |
| Failure mode logging | Every exception, escalation, and override documented |
| Human checkpoint execution | Reviewers actually reviewing, not rubber-stamping |
| Scope discipline | Resist requests to “also try it on” adjacent workflows |
| Comparison to baseline | Real-time progress against Week 1 metrics |
Two weeks of operation generates enough data to distinguish signal from noise in most workflows. The key: daily granularity. Weekly averages hide the variance that matters.
Week 5: Validate
| Validation Question | Evidence Required |
|---|---|
| Did we meet the success threshold? | KPI data vs. baseline |
| What were the failure modes? | Exception and escalation log |
| What hidden costs appeared? | Integration hours, retraining, support load |
| What quality changes occurred? | Error rate, customer impact, compliance status |
| Is the workflow repeatable at scale? | Operational stability assessment |
Week 5 is where most failed pilots reveal themselves — not because the technology didn’t work, but because hidden costs, integration friction, or quality changes weren’t measured. The validation must be honest: did this pilot produce evidence that justifies scaling, or evidence that suggests stopping?
Week 6: Decide
Three options. No ambiguity.
| Decision | Condition | Next Step |
|---|---|---|
| Scale | Success threshold met; hidden costs bounded; operational stability confirmed | Deploy to broader scope with documented playbook |
| Iterate | Partial success; specific improvements identified | Run another 2–4 week cycle with adjustments |
| Stop | Threshold not met; costs unbounded; or workflow not suitable | Document learnings; reallocate budget |
The stop decision is the most valuable outcome when the evidence supports it. The 42% of companies that scrapped AI initiatives in 2025 often ran for months before stopping. A 6-week pilot that produces a confident “no” saves more money than a 6-month project that produces an ambiguous “maybe.”

Simhevn Electronic Digital Calipers, inch and Millimeter Conversion,LCD Screen displays 0-6" Caliper Measuring Tool, Automatic Shutdown, Suitable for DIY/Jewelry Measurement (New150mm Black Plastic)
[4 measuring methods and safety]: Digital calipers can be used to measure inner and outer diameters, depths and…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
3. Pilot Design Principles
Single Workflow, Single Owner, Single KPI Set
Multi-workflow pilots dilute focus, distribute accountability, and make causation impossible to isolate. The pilot must answer one question: “Does AI improve this specific workflow by this specific amount?”
Tight Scope with Explicit Exclusions
The pilot charter must define what’s out of scope. Without explicit exclusions, scope creep is inevitable by Week 3. “We’ll also try it on invoice processing” is how focused pilots become unfocused programs.
Manual Fallback Available at All Times
If the AI fails, the workflow continues. This isn’t a safety net — it’s a design requirement that ensures the pilot doesn’t create operational risk. It also enables honest evaluation: the pilot can be stopped at any decision gate without business disruption.
No Scale Decision Without Measured Evidence
| Bad Decision Basis | Good Decision Basis |
|---|---|
| “The team liked it” | KPI delta vs. baseline |
| “It seems faster” | Measured cycle time reduction |
| “The vendor says it’s ready” | Operational stability data |
| “We’ve invested too much to stop” | Hidden cost analysis |
| “Leadership wants to scale” | Evidence against success threshold |
The sunk-cost trap is the single biggest risk in mid-market AI adoption. Pre-defined stop criteria, agreed in Week 1, prevent emotional investment from overriding evidence.
mid-market AI automation solutions
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
4. Where to Start: High-Impact Pilot Candidates
The best first pilots share three characteristics: the workflow is high-friction, the outcome is measurable, and the data exists.
| Pilot Candidate | Why It Works | Typical KPI |
|---|---|---|
| Support triage | High volume, rule-based, measurable resolution | Time-to-resolution, escalation rate |
| Proposal/RFP drafting | Time-intensive, template-heavy, quality-variable | Draft cycle time, revision count |
| Compliance prep | Repetitive, audit-driven, error-costly | Preparation hours, compliance gap rate |
| Invoice processing | Structured data, clear rules, high volume | Processing time, error rate |
| Employee onboarding docs | Template-based, frequently repeated | Preparation time, completion rate |
| Inventory forecasting | Data-rich, impact-measurable | Forecast accuracy, overstock rate |
Simple automation agents often break even within 6–8 weeks. Support triage, compliance prep, and invoice processing are the strongest first candidates because they combine high volume, clear rules, and measurable baselines.
The MIT data reinforces vendor strategy: purchased AI from specialized vendors succeeds at 67%, versus 33% for internal builds. Mid-market firms should buy, not build — and structure the purchase as a fixed-scope pilot with outcome-linked terms.
5. Practical Implications and Actions
Action 1: Start with High-Friction, Measurable Workflows
Not the most exciting AI use case. The most measurable one. Support triage, proposal drafting, compliance prep — workflows where current performance is quantified, improvement is attributable, and the data pipeline exists.
Action 2: Use a One-Page Pilot Charter
| Charter Element | Content |
|---|---|
| Workflow | Specific process being piloted |
| KPI | 1–3 metrics with baseline values |
| Success threshold | Quantified target (e.g., “30% reduction in triage time”) |
| Risk controls | Human checkpoints, fallback procedure |
| Timeline | 6 weeks with weekly milestones |
| Owner | Single named decision-maker |
| Exclusions | What’s explicitly not in scope |
| Stop criteria | Pre-defined failure conditions |
Action 3: Keep Integration Minimal; Expand Only After Proof
Connect only the systems the pilot requires. No platform build-out. No enterprise-wide data lake project. Companies that maximize existing tools spend 40–60% less. The integration question for Week 2: “What’s the minimum connection that lets us test the hypothesis?”
Action 4: Pre-Define Stop Criteria to Avoid Sunk-Cost Drift
Before the pilot begins, agree on what constitutes failure. Write it in the charter. Make it quantified. The 95% failure rate exists partly because organizations don’t define failure until the money is spent.
Action 5: Convert Successful Pilots into Reusable Templates
A successful pilot is not a one-time win. It’s a playbook. Document: the workflow configuration, the integration pattern, the KPI framework, the training approach, the failure modes encountered, and the decision gate outcomes. The second pilot should take 4 weeks, not 6, because the template exists.
6. What to Watch
Pre-packaged “outcome pilot kits.” Vendors are recognizing that mid-market buyers don’t want platforms — they want bounded, evidence-producing pilots. Expect packaged offerings: predefined workflow, integration template, KPI dashboard, 6-week timeline, and outcome-linked pricing. The vendor who arrives with a pilot kit, not a platform demo, wins the mid-market.
Outcome-linked pricing for fixed-scope pilots. 79 of 500 SaaS companies now offer credit-based pricing (up 126% YoY). The next evolution: outcome-linked pilot pricing where the vendor’s payment is tied to the pilot’s KPI achievement. The vendor confident in their product accepts outcome risk. The vendor who isn’t walks away — and that’s the filter working.
Buyer preference for scale playbooks over demos. Mid-market buyers are asking: “Show me the playbook, not the demo.” The 6-week structure, the one-page charter, the reusable template — these are what differentiate vendors who understand mid-market execution from vendors who understand enterprise sales.
The Bottom Line
95% of AI pilots fail. 88% never reach production. But mid-market firms that run fixed-scope, 6-week pilots with defined KPIs, decision gates, and stop criteria scale in 90 days — three times faster than enterprises that take nine months.
The 6-week blueprint isn’t a shortcut. It’s a discipline: define before configuring, measure before operating, validate before deciding, and stop before wasting. The mid-market’s constraints — smaller teams, tighter budgets, lower tolerance for failure — aren’t limitations. They’re the conditions that force the precision execution that broad “transformation” programs lack.
The pilot that produces a confident “no” in six weeks is worth more than the project that produces an ambiguous “maybe” in six months.
Thorsten Meyer is an AI strategy advisor who has learned that the best AI pilot outcome isn’t always “yes” — sometimes it’s a fast, evidence-based “no” that saves six figures and twelve months. More at ThorstenMeyerAI.com.
Sources
- MIT — GenAI Divide Study: 95% Pilot Failure Rate (2025)
- IDC — 88% AI Pilots Never Reach Production; 4 of 33 Scale
- BCG — 60% Generate No Material Value from AI
- Concentrix/Everest Group — 27% Testing to Implementation
- McKinsey — One-Third Achieve Enterprise-Wide Scaling
- S&P Global — 42% AI Initiative Abandonment (2025)
- Netguru — AI Adoption Statistics 2026: 78% Using AI, 71% GenAI
- AI Smart Ventures — Mid-Sized AI Pilot Failure: $50K–$200K Budgets
- Protiviti — 68% AI Agent Integration by 2026
- Gartner — 40%+ Agentic AI Projects Fail by 2027
- Gartner — 30% GenAI Projects Abandoned After POC (2025)
- SpaceO — AI Implementation Roadmap: 6-Phase Guide
- CIO — 2026: The Year AI ROI Gets Real
- Fortune — MIT Report: 95% Pilots Failing
- PricingSaaS — 79 Credit-Model Companies (126% YoY)
- QBSS — 2026: Mid-Market Outpaces Enterprise in AI
- WEF — AI’s Mid-Market Business Moment (January 2026)
- OECD — AI Adoption by SMEs
- CEOWORLD — AI C-Suite Spending 2026
- Goldman Sachs — $500B+ AI Investment (2026)
- Deloitte — State of AI in Enterprise (2025)
- Alphabold — Agentic AI Use Cases 2026
- G2 — AI in Customer Support Report 2026
- Vellum — AI Agent Use Cases: ROI Guide
- Microsoft/Slack — 48% Uncomfortable Admitting AI Use
© 2026 Thorsten Meyer. All rights reserved. ThorstenMeyerAI.com