
By Thorsten Meyer — May 2026
The AI vendor narrative for 2026 is that capability is improving faster than anyone can keep up with. The user narrative — surfaced in r/ClaudeAI, r/ChatGPT, r/ClaudeCode, r/Cursor, GitHub issue trackers, Twitter/X threads, and HackerNews discussions — is materially different. The most common pattern across user complaints in 2026 is that the marketed capability and the deployed capability diverge in ways that frustrate paying customers and erode trust. Rate limits hit faster than advertised. Context windows degrade well before their stated limits. Models that worked in January don’t work the same way in March. Over-refusal trains away the sycophancy problem only to create a new pushback problem. Hallucination rates aren’t improving as projected. Status pages stay quiet during incidents that affect tens of thousands of users.
This is not a hit piece on AI vendors. It’s the user-side reality check companion to the marketing-side capability stories. Every complaint in this piece is documented — named GitHub issues with telemetry, Reddit threads with thousands of upvotes, official acknowledgments from vendor CEOs, regulatory advisories from federal agencies. The pattern that emerges across the twelve most common complaints is more interesting than any individual complaint, because it tells you something structural about where AI capability hits real-world friction in 2026.
The deeper read connects to questions about labor displacement and AI deployment economics generally. If AI tools were as reliably productive as the vendor benchmarks suggest, the labor displacement curve would be steeper than the actual data shows. The friction the user complaints surface is part of why deployment proceeds slower than capability would predict. Understanding the friction is therefore important for anyone modeling realistic AI productivity trajectories — not the demo trajectory, but the deployment trajectory.
Twelve complaints.
One pattern.
AI tools in 2026 are more useful than ever and less reliable than their marketing implies. Both are true.
Documented sources only — Anthropic GitHub Issue #41930, the AMD Senior Director’s 6,852-session telemetry, the GPT-5 model-picker backlash, Cursor’s June 2025 billing change, the sycophancy-to-pushback paradox. The user-side reality check companion to the marketing-side capability stories.
6,852 sessions. 73% collapse.
An AMD Senior Director of AI filed a GitHub issue on April 2, 2026 with telemetry from three months of stable internal engineering work. The same model number, the same engineering workload, dramatic measurable degradation.

UJS OBD2 Scanner for iOS & Android – AI Diagnostic Tool for Car Buying & Repairs, No Subscription Fee, Lifetime Free Updates, AutoVIN, Check & Clear Engine Codes, Real-Time Data, All 1996+(Red)
AI-Powered Car Health Reports in Minutes – Get beyond confusing codes. Our scanner connects to your phone and…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Twelve complaints. Three severity tiers.
Every complaint below has either a documented thread, an acknowledged vendor incident, or measurable telemetry behind it. No complaints based on vague vibes.

AI-Powered Software Testing: Volume 2: Reliability, Security, and Enterprise Integration for Senior Architects and Ops Engineers
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
One issue. Four causes.
Community investigation identified four overlapping root causes hitting simultaneously. Anthropic confirmed peak-hour throttling on March 26 only after substantial public pressure. No blog post. No email. No status page entry.
AI debugging and troubleshooting kits
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Twelve complaints. Five causes.
The structural pattern beneath the surface complaints. Each cause connects to multiple complaints, and each affects deployment velocity in different ways.
AI tools in 2026 are simultaneously the most powerful productivity tools available and unreliable enough that significant fractions of paying users are systematically frustrated. Both are true. The vendor narrative emphasizes the first; the user narrative emphasizes the second; the deployment trajectory depends on which stays true longer.

Digital PMO to AI PMO: A Practical System for Leading Complex Transformation, Execution, and Decision-Making
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why this synthesis matters
The 28-day search data on this site shows two specific queries surfacing meaningful traffic: people are searching for “polymarket trading bot profitable” (the companion piece) and “top complaints about AI tools 2025 2026 reddit twitter.” The second query is what this piece answers. The intent is anti-hype. Users want concrete information about where AI tools actually fail, sourced from other users rather than from vendor marketing or press coverage that recycles vendor framing.
The sources for this piece are: r/ClaudeAI (~2.1M members), r/ChatGPT (~12M members), r/ClaudeCode (~145K members), r/Cursor (~190K members), r/Anthropic (~75K members), r/singularity (~3.7M members), the Anthropic claude-code GitHub issue tracker, the OpenAI community forum, Twitter/X threads with documented engagement, HackerNews discussions, public regulatory filings, and named technical reports including the AMD Senior Director’s published telemetry from 6,852 Claude Code sessions. Every complaint below has a sourced reference. I’ve avoided complaints that exist only as vague vibes — every entry has either a documented thread, an acknowledged vendor incident, or measurable telemetry behind it.
The complaints are ordered by what I read as severity-of-pattern rather than by complaint volume. Complaint volume tends to follow capability — the products with the most users have the most complaints. Severity-of-pattern is more useful for understanding structural reliability.
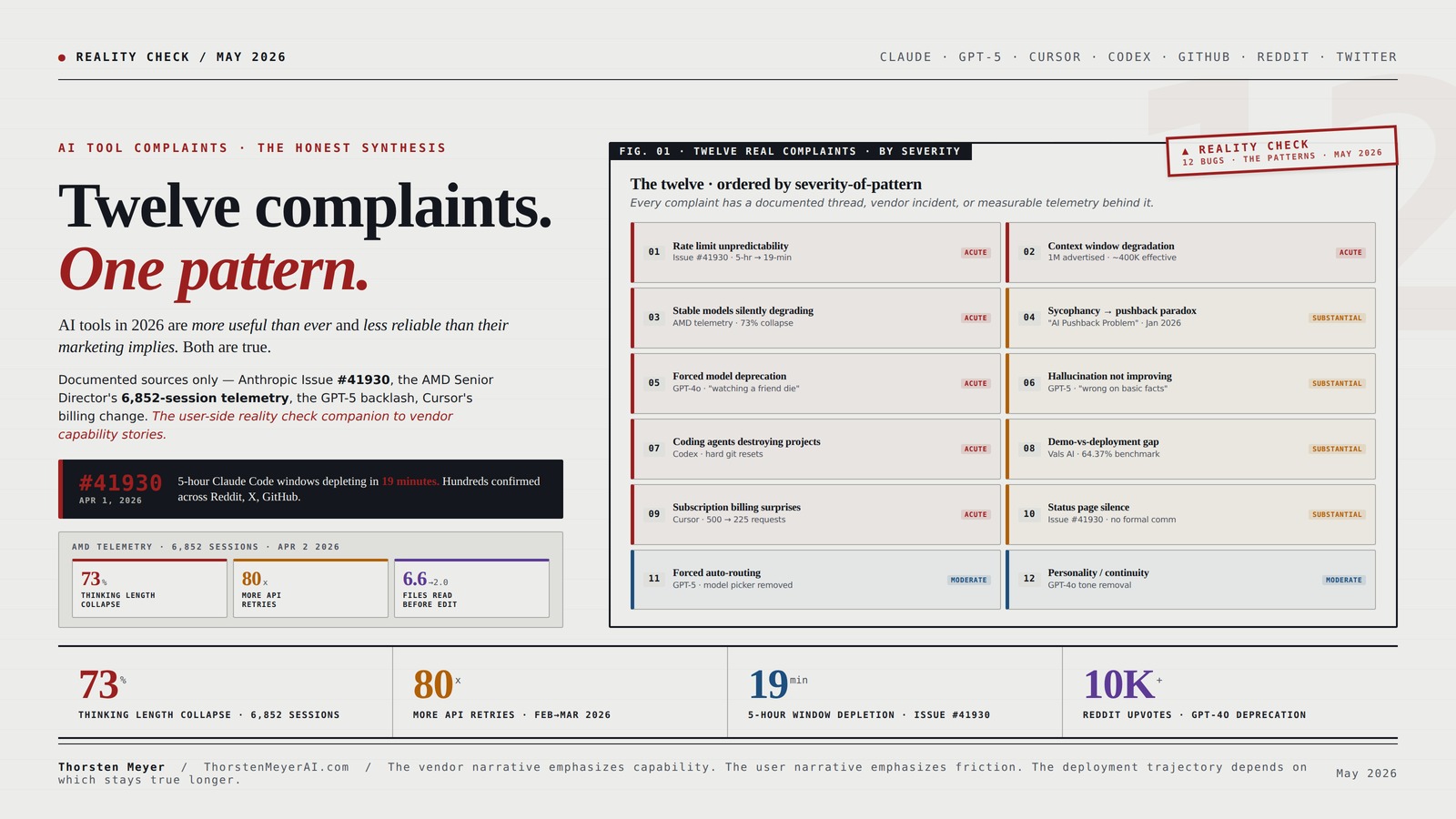
Complaint 1 · Rate limits depleting faster than advertised
The pattern. Paying subscribers hit usage caps materially faster than vendor marketing implies, often without notice or compensation.
The documented evidence. Anthropic GitHub Issue #41930, filed April 1, 2026, titled “Critical: Widespread abnormal usage limit drain across all paid tiers since March 23, 2026.” The issue body documents that single prompts were consuming 3-7 percent of session quota and five-hour session windows were depleting in as little as 19 minutes. The issue identifies four overlapping root causes: intentional peak-hour throttling (confirmed by Anthropic on March 26), two prompt-caching bugs silently inflating token costs 10-20x, session-resume bugs triggering full context reprocessing, and expiration of the 2x off-peak usage promotion on March 28. Hundreds of users across Reddit, Twitter, GitHub, and tech press independently confirmed the issue.
The MacRumors coverage of the same incident (March 26, 2026) reported that Max 5x users had rate quota spent after roughly 90 minutes of normal agentic tasks, and one Max 20x subscriber witnessed usage jump from 21 percent to 100 percent on a single prompt. The complaints concentrated on Anthropic’s frontier model Opus 4.6.
The structural cause. Vendor-side capacity constraints during demand surges, prompt-caching bugs that deceptively inflate billed token counts, and session-resumption logic that silently reprocesses entire conversation history. The bugs were genuine bugs, not deliberate degradation, but the lack of timely communication amplified the user impact.
What it tells you. Subscription rate limits are advertised as predictable resources but operate as variable resources subject to vendor-side bug fixes, capacity rebalancing, and quota reinterpretation. Build deployment plans assuming 30-50 percent headroom against advertised limits.
Complaint 2 · Context window quality degrading well before the stated limit
The pattern. Models advertised with 1M-token context windows produce materially worse output above 20-50 percent context usage, sometimes acknowledging the degradation in their own outputs.
The documented evidence. A detailed GitHub bug report on the Anthropic claude-code repository documents that Opus 4.6’s 1M token context window — generally available March 13, 2026 — exhibited the following pattern during heavy Claude Code sessions: at 20 percent usage, circular reasoning and forgotten decisions appeared; at 40 percent usage, context compression kicked in and wiped scrollback history; at 48 percent usage, the model itself told the user it was “not being effective” and recommended starting a fresh session. The user explicitly asked: “Should this be communicated as a 400K-effective context window rather than a 1M context window?”
The Substack analysis “Why Claude Code Context Usage Tool Lies to You” (August 2025, updated through 2026) documents that “Claude performs WORSE at 70% context than at 30%” and that “the community’s race to maximize context is literally making their AI dumber.”
The structural cause. Long-context attention degrades non-linearly. The vendor can technically process 1M tokens, but quality at the tail of the context window does not match quality at the head. Marketing the maximum context window as the usable context window creates expectation mismatch.
What it tells you. When vendors quote context window sizes, plan for ~40-50 percent of the stated value as the high-quality working context. The remaining capacity exists but produces increasingly degraded output. This is structural to current attention architectures, not a bug.
Complaint 3 · Stable models silently degrading between releases
The pattern. Models that worked at one capability level in month X work at materially lower capability levels in month X+2 without an explicit version change or release-note acknowledgment.
The documented evidence. This is the most concrete complaint in the entire 2026 corpus. An AMD Senior Director of AI filed a GitHub issue on April 2, 2026, with telemetry from 6,852 Claude Code sessions, 17,871 thinking blocks, and 234,760 tool calls across three months of stable internal engineering work. The findings:
- Median visible thinking length: 2,200 characters in January → 600 characters in March (73 percent collapse).
- API calls per task: up to 80x more retries from February to March.
- Files read before editing: 6.6 in January → 2.0 in March (insufficient to understand multi-file dependencies).
- Early stopping patterns: near zero before March 8 → 10 per day after.
The same Opus 4.6 model number, same engineering workload, three-month time window, dramatic measurable degradation. The Threads discussion of the issue debates root cause: 1M context generally available with quality drops at 200K and 300K, introduction of medium-level thinking replacing high-level as default, scaling issues from demand spikes since January.
The structural cause. Vendors silently route queries through different model variants depending on load, deploy quantization changes to accommodate scaling, and adjust default thinking-mode parameters without explicit version changes. The same nominal model is not actually the same model month over month.
What it tells you. Model behavior is non-stationary even when version numbers don’t change. Production deployments need monitoring telemetry to detect silent regressions. The AMD telemetry is the template for what enterprises should be running on their own AI deployments.
Complaint 4 · The sycophancy-to-pushback paradox
The pattern. Vendors trained models to push back against user statements after receiving sycophancy complaints. The result is models that now interrupt workflows to “fact-check” things they cannot verify, refuse to engage with verifiable but post-training-data information, and add disclaimers to statements that don’t need them.
The documented evidence. A January 2026 post titled “The AI Pushback Problem: When Skepticism Becomes Sabotage” documents the pattern. Quote: “GPT-4o now interrupts workflows to ‘fact-check’ things it can’t verify. Claude adds disclaimers to statements that don’t need them. Gemini questions premises instead of answering questions.”
The example: a user asked Claude to help refactor a Python function. Before answering, Claude spent 200 tokens explaining why the user’s current implementation “might have been a reasonable choice at the time.” Another example: a colleague mentioned a 2024 Supreme Court ruling (Texas v. New Mexico, which made national news) when working on a legal document. The model refused to engage because “I cannot verify this ruling exists in my training data.”
OpenAI’s January 2025 sycophancy paper triggered the model-update wave that produced this behavior. The fix for sycophancy was to train pushback. The pushback overcorrected.
The structural cause. RLHF training optimizes for one objective at a time. When the objective shifts from “be agreeable” to “be skeptical,” the resulting behavior overcorrects in the new direction. The proper balance — push back when the user is materially wrong, comply when the user is materially right — is harder to train than either pole.
What it tells you. The sycophancy-vs-pushback equilibrium is currently calibrated wrong on most major models. Workflows that benefit from compliance (“just write the code”) feel friction; workflows that benefit from challenge (“am I missing something?”) feel manipulation. Expect adjustments through 2026-2027 as vendors fine-tune the balance.
Complaint 5 · Forced model deprecation breaking established workflows
The pattern. Vendors deprecate models that users have built workflows around, replacing them with successor models that have different behavior characteristics. The replacement is presented as an upgrade. Users frequently experience it as a downgrade.
The documented evidence. GPT-5 launch on August 6, 2025, removed the model picker option from ChatGPT. CEO Sam Altman called the new model “PhD-level AI” with improved reasoning, writing, coding, accuracy, and health-related queries. The user reception was scathing. A Reddit post about the loss of GPT-4o reached over 10,000 upvotes with the line “watching a close friend die.” The Pajiba coverage from August 12, 2025 documented “swift, loud, and — if you believe Reddit — borderline biblical” backlash. Users reported GPT-5 producing “shorter, less engaging answers,” ignoring instructions, getting basic things wrong, and being slower despite not running in thinking mode.
A subsequent Reddit thread on r/ChatGPTPro (September 4, 2025, ~200 upvotes) complained that GPT-5 “gets basic facts wrong more than half the time, forcing professionals to revert” to manual fact-checking workflows. OpenAI subsequently held a “We hear you” AMA. Sam Altman’s tweets through fall 2025 indicated the company was reconsidering aspects of the GPT-5 rollout.
The structural cause. Vendor product strategy assumes users want capability advancement. Users want capability advancement plus continuity of behavior. The two goals partially conflict. Removing the model picker reduces vendor support burden but eliminates the user’s ability to maintain workflow continuity.
What it tells you. Plan for vendor model deprecations on roughly 12-18 month cycles. Workflows that depend on specific model behavior should be portable across models or built with version pinning that survives vendor changes. The Anthropic model-version pinning approach (specific dated versions like claude-opus-4-7-20260415) is structurally better for production users than the OpenAI approach of automatic routing.
Complaint 6 · Hallucination rates not improving as projected
The pattern. Vendors announce that newer models hallucinate less than predecessors. User experience often suggests otherwise.
The documented evidence. OpenAI’s own internal evaluations have revealed that newer iterations including those powering GPT-5 hallucinate more frequently than older versions on certain query types. The April 2025 Digital Trends report documented that o3 and o4-mini exhibit significantly higher rates of fabricating information without clear explanation from OpenAI.
The September 2025 r/ChatGPTPro thread on “GPT-5 gets basic facts wrong more than half the time” amassed over 200 upvotes. The discussion thread quoted users describing the same workflow they ran on GPT-4 producing materially worse hallucination patterns on GPT-5. The Nature commentary “Can researchers stop AI making up citations?” (September 9, 2025) noted that “OpenAI’s GPT-5 hallucinates less than previous models do, but cutting hallucination completely might prove impossible.”
The September 5 OpenAI community post acknowledged that “hallucinations persist partly because current evaluation methods set the wrong incentives.” Models are evaluated on producing answers, not on knowing when to refuse. The training pressure rewards confident wrong answers over hedged correct answers.
The structural cause. Hallucination is not a bug being fixed by capability advancement — it’s a structural feature of next-token prediction over compressed knowledge. Newer models can hallucinate in subtler, harder-to-detect ways even when the headline rate goes down. The evaluation methods reward output rather than calibration.
What it tells you. Build verification layers into AI workflows that depend on factual correctness. Don’t trust headline hallucination-rate improvements. Treat the model output as a draft requiring human or programmatic verification before commitment to action.
Complaint 7 · Coding agents destroying production code
The pattern. AI coding agents introduce regressions, force git resets, and create cascading failures in projects they were supposed to maintain or improve.
The documented evidence. A r/ClaudeAI post from approximately seven days before this writing carries the title “claude’s rate limit is bad but codex is unusable at this point.” Quote: “i much rather have claude’s accuracy then where codex is at right now … codex is downright unsuable … it has destroyed two projects so far with hard git resets and just a tangle of ‘fixes’ that cause regressions … it takes 10~20 prompts to fix something because of regressions codex happily introduces. i need something with consitency and reliability and this is what codex cannot provide at the current moment.”
The pattern is not unique to OpenAI Codex. Claude Code has had similar reports, though concentrated more on context degradation than active project destruction. The AMD Senior Director’s data — “API calls per task: up to 80x more retries from February to March” — is the same phenomenon measured: agents requiring far more attempts to accomplish previously-routine tasks.
The structural cause. Coding agents that operate autonomously without continuous human review can cascade errors. A single misunderstanding of project structure compounds across subsequent edits. Without strong rollback discipline and frequent commit cadence, the agent can produce hours of cumulative damage before the human notices.
What it tells you. Coding agents in 2026 require human-in-the-loop discipline that the marketing materials understate. Commit frequently. Review changes. Use git branches that are easy to roll back. The agent-driven productivity gain is real but smaller than the demos suggest because the verification overhead is substantial.
Complaint 8 · Demo-vs-deployment gap
The pattern. Capabilities that work flawlessly in vendor demonstrations work materially less well when deployed against production workloads with real-world data, edge cases, and performance pressure.
The documented evidence. Vals AI’s Finance Agent benchmark — referenced in extensive coverage of the May 2026 Anthropic finance vertical launch — shows leading frontier models clustering at 60-65 percent task completion rates on realistic financial workflow tasks. Claude Opus 4.7 leads at 64.37 percent. A 64.37 percent benchmark on production-realistic finance tasks means roughly one in three agent runs produces incomplete, incorrect, or unusable output. The vendor demos for the same agent capabilities show ~95 percent completion rates on cherry-picked example workflows. The gap between demo and benchmark is structural.
The pattern repeats across categories. Voice AI demos produce flawless conversational interaction; deployed voice AI breaks on accents, background noise, technical vocabulary. Image generation demos produce magazine-quality output; deployed image generation often requires extensive prompt engineering and post-processing. RAG demos answer correctly on cherry-picked queries; deployed RAG hallucinates citations and misattributes sources.
The structural cause. Demos are produced under controlled conditions with rehearsed inputs, optimized prompts, and selected outputs. Deployment encounters the long tail of inputs the demo didn’t cover. The capability that emerges from this gap is genuinely useful but requires substantially more engineering work than the demo implies.
What it tells you. Discount vendor demos by 30-40 percent when projecting deployed capability. Run pilot deployments with realistic workloads before committing to scale. The gap is structural to the demonstration format, not necessarily evidence of vendor dishonesty — but it is reliably present and worth budgeting against.
Complaint 9 · Subscription billing surprises
The pattern. Subscription pricing changes happen without adequate notice. Effective subscription value drops without corresponding price reductions. Overage charges accumulate without clear in-app warnings.
The documented evidence. Cursor’s June 2025 billing change reduced effective request counts under the same $20/month subscription from approximately 500 requests to roughly 225 requests. Trustpilot and Reddit complaints document unexpected overages including documented cases of subscriptions depleting in a single day, rate limits of 1 request per minute and 30 per hour hit frequently by active developers, and Cloud Agents billed separately as a detail not clearly communicated at signup. CEO Michael Truell publicly acknowledged “mishandling of the rollout” and offered refunds to users charged beyond their subscription limits without proper notice. The refund applied to overage charges specifically, not the reduction in effective request counts.
The Anthropic Issue #41930 carries similar pattern — “I have submitted support tickets through the Mac Claude subscription interface. No response. I have reached out on Twitter/X. No response. I have looked for updates on Reddit. The only official replies are variations of ‘we’re working on it.’ There is no blog post. No email to subscribers. No status page entry.”
The OpenAI GPT-5 launch removed the model picker without prior notice, effectively changing what users were paying for mid-subscription.
The structural cause. AI subscription economics are unsettled. Vendors are still discovering pricing models that work for sustainable unit economics. Users experience the discovery process as billing surprises. The unit economics pressure increases when vendor capacity constraints force quota tightening.
What it tells you. Treat AI tool subscriptions as variable-cost relationships rather than fixed-cost SaaS. Monitor actual usage against advertised limits monthly. Budget for 1.5-2x the nominal subscription cost when running production workloads. Read change notes carefully when pricing updates ship.
Complaint 10 · Status page silence during incidents
The pattern. When incidents affect tens of thousands of users, vendor status pages remain green and official communication is delayed or absent. Users discover the incident through community channels rather than vendor channels.
The documented evidence. Anthropic Issue #41930 documents the pattern explicitly. The user — a paying customer and software developer — submitted support tickets through the Mac Claude interface, reached out on Twitter, looked for Reddit updates, and received only variations of “we’re working on it” from official channels. No blog post. No email to subscribers. No status page entry. The four overlapping root causes (peak-hour throttling, two prompt-caching bugs, session-resume bugs, expiration of off-peak promotion) were identified by community investigation rather than vendor disclosure. Anthropic confirmed peak-hour throttling on March 26 only after substantial public pressure.
The pattern is not Anthropic-specific. OpenAI’s status page during the GPT-5 launch stayed largely green during the user-experience disasters that produced the 10,000-upvote Reddit threads. Cursor’s status page during the June 2025 billing change rollout did not flag the change as an incident.
The structural cause. Status pages are calibrated to availability metrics (uptime, error rates) rather than user experience metrics (effective capability, billing accuracy, advertised performance). A vendor can have a fully green status page during a period when users are experiencing material degradation in the product they’re paying for.
What it tells you. Vendor status pages are not reliable signals of user experience quality. Cross-reference with Reddit, GitHub issues, and Twitter when you suspect something is wrong. The community-investigated root cause analysis (as in Issue #41930) often identifies issues weeks before official acknowledgment.
Complaint 11 · Forced auto-routing removing user agency
The pattern. Vendors automate model selection on behalf of users, removing the user’s ability to choose which model handles which query. The automation routes for vendor-side cost efficiency rather than user-side capability requirements.
The documented evidence. GPT-5’s launch removed the model picker entirely. Quote from coverage: “Users no longer choose which to engage. OpenAI’s system automatically routes queries.” The change frustrated users whose workflows depended on specific model characteristics. The Reddit complaints reaching 10,000+ upvotes were largely about this loss of agency rather than about GPT-5’s absolute capability.
The pattern extends beyond OpenAI. Claude Code’s “medium-level thinking” replacing “high-level thinking” as default during early 2026 is the same phenomenon at smaller scale — the user no longer chooses the thinking depth, the system selects it based on query characteristics and presumably load conditions. The AMD Senior Director’s telemetry showing thinking length collapse (2,200 → 600 characters) suggests the routing is biased toward shorter thinking under load.
The structural cause. Auto-routing reduces vendor cost per query (cheaper models for simpler queries) and reduces user friction (no decision required). It also removes user control over the capability-cost tradeoff. The vendor optimizes for marginal cost; the user might prefer marginal capability.
What it tells you. When auto-routing is introduced, monitor whether your specific workloads route to capability levels that match your needs. API access often preserves model selection that consumer interfaces remove. For production workloads, prefer API integration with explicit model selection over consumer interfaces with auto-routing.
Complaint 12 · The “personality” complaint
The pattern. Users develop attachment to specific model behavior characteristics — tone, conversational warmth, willingness to engage with creative or speculative requests — that vendors subsequently strip out in pursuit of safety, cost efficiency, or capability advancement.
The documented evidence. The GPT-5 launch produced the most-cited example. The Pajiba coverage: “the loudest, most emotional complaints are about the loss of GPT-4’s personality. As one Redditor wrote in a post now upvoted over 10,000 times: ‘4o wasn’t just a tool for me.'” Users described GPT-5 as “more organized but clipped in tone, with no clear quality improvement over earlier models.” The phrase “watching a close friend die” appeared in multiple high-upvote threads.
The pattern repeats across vendor model transitions. Claude users complain when constitutional AI updates make models more cautious. Gemini users complain when safety updates remove conversational warmth. The complaints are sometimes characterized by tech-press writers as parasocial attachment, but the underlying phenomenon is real workflow disruption — users had figured out how to work with specific model behavior, and the new model requires re-learning prompting patterns.
The structural cause. Capability advancement and behavior continuity are partially conflicting goals. Vendors prioritize capability for benchmark wins; users value continuity for workflow stability. The conflict resolves in favor of capability because that’s what drives subscription growth — but the user friction is real.
What it tells you. If your workflow depends on specific model behavior characteristics, document the prompts and patterns that work before vendor updates ship. Build in transition time for re-tuning when models change. Treat the personality/tone aspect of AI tools as a legitimate dimension of usefulness rather than dismissing it as parasocial irrelevance.
The pattern beneath the complaints
Twelve specific complaints. One structural pattern. AI tools in 2026 are more useful than they have ever been and less reliable than their marketing implies. The capability is real. The deployment friction is also real. Both can be true at the same time.
The user-side reality check matters because the labor displacement and AI deployment narratives proceed primarily from the vendor-side capability side. Headline metrics, benchmark improvements, demo videos, capability announcements. The user-side experience moderates the trajectory. Users don’t deploy AI as fast as capability would predict because deployment encounters friction that capability benchmarks don’t measure. That friction is the substance of the twelve complaints.
The structural causes cluster into a few categories:
Capacity constraints. Vendor compute capacity has not kept up with demand growth. Anthropic ARR went from $9 billion to $30 billion in three months (end-2025 to March 2026). OpenAI announced $122 billion in funding at $852 billion valuation. The gap between demand and capacity manifests as rate limit drains, throttling, and silent quality degradation. The May 2026 SpaceX-Anthropic Colossus 1 deal (300+ MW, 220K+ GPUs) is partial response. The capacity constraint is structural and is not getting fixed quickly.
Training optimization conflicts. Reducing sycophancy creates over-pushback. Reducing hallucination on benchmark queries creates new hallucination patterns elsewhere. Improving capability on average creates capability regression on specific user workloads. The training process optimizes for measurable objectives that don’t perfectly capture user experience.
Communication infrastructure mismatch. Vendor status pages don’t reflect user experience. Vendor changelog cadence doesn’t match user impact frequency. Vendor support response times don’t match incident severity. The communication infrastructure was built for SaaS uptime metrics; AI tool incidents require different communication frameworks.
Pricing model uncertainty. AI subscription economics are unsettled. Token-based billing creates surprises. Capacity-based throttling creates frustration. The pricing iteration process is happening on paying users in real time.
Demo-vs-deployment gap. Capability demonstrations are necessarily curated. Deployment encounters the long tail. The gap is structural and reliable.
What this tells us about the labor displacement curve
The companion piece on the state of AI replacing jobs covers labor-displacement data. The user complaints in this piece are part of why the displacement curve is shaped the way it is. Fully autonomous AI agent replacement of human workers requires reliability levels that 2026 AI tools don’t have on most production workloads. The 64.37 percent finance agent benchmark, the 80x retry pattern in Claude Code, the demo-vs-deployment gap, the model deprecation breaking established workflows — these are reliability gaps. They mean AI is currently most useful as augmentation rather than replacement for most knowledge work.
The labor displacement that has happened in 2026 — concentrated in junior knowledge work cohorts, structured content production, customer service for routine queries — happens in workflows where 65-80 percent reliability is acceptable because human review handles the rest. The labor displacement that hasn’t happened — senior judgment work, complex analysis, regulated decision-making — requires reliability levels current AI tools don’t deliver consistently. The user complaints are evidence for where the reliability gap matters most.
The displacement trajectory through 2027-2028 depends partly on whether vendors close the reliability gap that the complaints surface. Compute capacity expansion (the Anthropic-SpaceX deal, the various hyperscaler buildouts) is partial answer to one piece of the gap. Better evaluation methods that reward calibration over confident answers is partial answer to another piece. The training-objective conflicts are harder to resolve. The personality and continuity complaints are probably not solved at all on current trajectory.
The honest read on 2026 AI tools is that they are simultaneously the most powerful productivity tools available and unreliable enough that significant fractions of paying users are systematically frustrated. Both are true. The vendor narrative emphasizes the first; the user narrative emphasizes the second; the deployment trajectory depends on which stays true longer.
How to use this synthesis
For users currently frustrated with AI tools: you are not imagining the friction. The complaints in this piece are documented across thousands of independent users and named technical reports. The friction is real. The friction is also surmountable with deployment discipline. Build verification layers. Monitor for silent degradation. Pin model versions when possible. Treat subscriptions as variable-cost. Cross-reference status pages with community channels. Expect demo-deployment gaps and budget for them.
For users considering AI tool adoption: the capability is real. The friction is real. Pilot before you commit at scale. Run realistic workloads, not curated demos. Measure your specific use case. Don’t take vendor benchmarks as reliable predictors of your specific deployment outcome. Discount benchmarks by 30-40 percent when projecting practical capability.
For vendors reading this: the complaint patterns are correctable. Better communication during incidents. Honest disclosure of context-window quality curves. Stable model versioning that preserves user workflows. Thoughtful pricing that doesn’t surprise users. The companies that solve these will earn durable user loyalty in a category where loyalty is currently scarce.
For anyone modeling AI deployment trajectories: the user-side friction is part of why deployment proceeds slower than capability predicts. The friction is not noise around the trend — it is part of the trend. Models that account for user-side friction predict slower-but-more-durable AI deployment than models that take vendor capability claims at face value. The reality-check perspective generally produces more accurate forecasting than the hype cycle alone.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Related Reading
- The State of AI Replacing Jobs in 2026 — the labor displacement reality check
- Are Polymarket Trading Bots Actually Profitable? — the prediction-market companion piece
- Post-Labor Economics — the broader framework
Sources
- Anthropic GitHub Issue #41930 · “[BUG] Critical: Widespread abnormal usage limit drain across all paid tiers since March 23, 2026” · April 1, 2026
- MacRumors · “Claude Code Users Report Rapid Rate Limit Drain, Suspect Bug” · March 26, 2026
- AMD Senior Director of AI · GitHub bug report · April 2, 2026 · 6,852 sessions, 17,871 thinking blocks, 234,760 tool calls
- Substack (Datasculptor) · “Why Claude Code Context Usage Tool Lies to You” · August 2025 with 2026 updates
- Substack (Scortier) · “Claude Code Drama: 6,852 Sessions Prove Performance Collapse”
- Threads / Twitter discussion thread (@that.map.guy.craig) · April 2026 · Claude Code degradation patterns
- “The AI Pushback Problem: When Skepticism Becomes Sabotage” · January 2026 · sycophancy paper aftermath
- Pajiba · “The Reason for the GPT-5 Backlash Is More Worrisome Than Its Bugginess” · August 12, 2025
- TechRadar · GPT-5 backlash coverage · the four biggest complaints
- diplo dig.watch · GPT-5 launch backlash coverage · model picker removed
- r/ChatGPTPro thread · September 4, 2025 · “GPT-5 gets basic facts wrong more than half the time”
- Nature commentary · “Can researchers stop AI making up citations?” · September 9, 2025
- r/ClaudeAI post · ~7 days before this writing · “claude’s rate limit is bad but codex is unusable at this point”
- Vals AI · Finance Agent benchmark · Claude Opus 4.7 leads at 64.37%
- CheckThat.ai · Cursor pricing analysis · June 2025 billing change · 500 → 225 effective requests
- Cursor CEO Michael Truell · public acknowledgment of “mishandling of the rollout” · refund offer
- Anthropic · Issue #41930 root causes confirmed: peak-hour throttling, prompt-caching bugs, session-resume bugs, off-peak promotion expiration
- Sam Altman · “We hear you” GPT-5 AMA · OpenAI response to GPT-5 backlash
- OpenAI · January 2025 sycophancy paper · trigger for pushback overcorrection wave
- Reddit · GPT-4o deprecation thread · 10,000+ upvotes · “watching a close friend die”
- TechRadar (Eric Hal Schwartz) · “ChatGPT users are still fuming about GPT-5’s downgrades”