This is not financial advice. Nothing in this article should be used to inform real trading decisions. The software described here trades simulated money by default; if you reconfigure it to trade real money, you should expect to lose that money. That remains the most likely outcome regardless of how clever any individual agent’s reasoning looks.
What’s been published so far
The first two articles in this series were honest reports from a multi-strategy paper-trading bot called Polybot, running against Polymarket’s 5-minute Up/Down prediction markets.
Week one: 21 parallel strategy experiments, the early winners were mostly mechanical illusions, and exactly one strategy — a fair-value taker on BTC — showed the mathematical signature of real edge over a few hundred settled trades.
Week two: the same fair-value strategy, with more data, collapsed. A separate hypothesis introduced mid-week — a market-making approach — also failed cleanly. The fleet of 25 experiments ended the second week at roughly negative thirty-three percent of bankroll. The headline number underneath that: a 78 % fleet-wide win rate combined with deeply negative P&L. The strongest possible demonstration of the trap: you can win four out of five trades and still go broke, because the one loss is bigger than the four wins put together.
The honest research finding wasn’t on the winning side. It was on the losing side: a parametric trading strategy that looks compelling in a backtest will, almost always, fail to survive a fresh sample. Most “edges” are mechanical artefacts that vanish once you measure them honestly.
That is a useful finding. But it raises a natural follow-up.

18 coup stock market analysis software (Vol.2)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The next research question
If parametric strategies — explicit rules with hand-tuned parameters — mostly don’t work, what about something less rule-bound? Specifically: can a committee of large language models, each playing a different role, make better-than-random decisions when given the same data a human portfolio manager would see?
This isn’t asking do LLMs predict the market. The honest prior on that question is “no, with high confidence”, and anyone selling otherwise should be examined carefully. It’s the narrower question: when LLMs are asked to argue with each other, structured into specialised roles, does the resulting committee produce decisions that are at least no worse than a coin flip after fees?
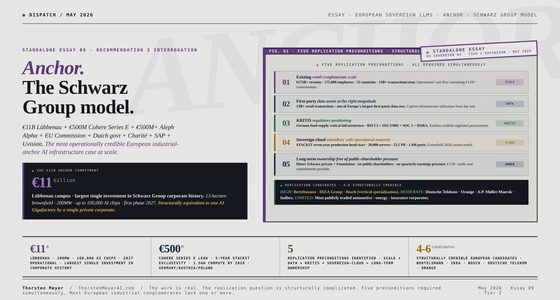
There’s a serious open-source project that takes this question seriously, called TradingAgents. Originally published by the TauricResearch team, it implements a multi-agent stock-research framework on top of LangGraph. The architecture is the interesting part: it doesn’t ask one LLM “should we buy this?”. Instead, it routes the question through specialised roles whose biases differ, and then makes those biases argue in public.
The framework comprises thirteen agent roles working in stages:
- Four analysts in parallel — market structure, news flow plus insider activity, fundamentals (balance sheet + earnings), and social-media sentiment. Each writes a short structured report independently.
- A bull-bear debate — two researcher agents argue opposing theses from the analyst reports. A research-manager agent arbitrates and writes a single synthesis.
- A three-voice risk team — aggressive (looks for upside, accepts variance), conservative (looks for downside, protects capital), neutral (balances). Forces explicit articulation of downside before any order is proposed.
- A two-layer decision — a trader agent produces a three-tier proposal (buy / hold / sell), and a portfolio-manager agent synthesises the whole stack into a final five-tier rating with a price target and a time horizon.
It’s a serious design. The thing it explicitly does NOT do is promise the LLMs are right. What it does is force the system to articulate why it thinks what it thinks, and to do so through multiple competing voices. The portfolio manager only sees the arguments, never the raw data — which forces the committee to make its reasoning explicit rather than relying on what a single context window happens to recall.
The upstream framework ships the agent graph. It does not ship the operational machinery to run that graph on autopilot, observe its results honestly, store results in a way that can be inspected later, or prevent the operator from accidentally trading real money.
That’s the gap the Forezai fork fills.
Introducing Forezai · TradingAgents.
A committee of LLMs
decides paper-trades.
Analysts · Debate · Risk · Decision
combined with -33% bankroll
services, HTTP routes (starting baseline)
(falls back to public API per token)
The bet is on a different mechanism, not a different parameter setting. The point is not to find a money-printing AI. The point is to put honest measurements of these systems into the public record — so the next person looking at the space starts a step further along than the last.Thorsten Meyer AI · Introducing Forezai · TradingAgents · § 03

Betfair Trading Techniques: Trading Models, Machine Learning, Money Management, Monte Carlo Methods & Algorithmic Trading
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What the fork adds
The new project, Forezai · TradingAgents, is a fork of the upstream framework with the same Apache-2.0 license preserved. It keeps the upstream agent graph intact and adds the operational layer needed to use it as a research instrument rather than a tech demo.
The additions, briefly:
An autonomous loop. A scheduler fires the engine daily across a configured watchlist. An auto-trader maps the engine’s ratings to paper orders, with allow-list filtering, per-ticker cooldowns, sector caps, and cash checks. A position manager evaluates every open position every sixty seconds for take-profit, stop-loss, or maximum-hold-duration exits. Every layer writes to its own append-only audit log.
A multi-broker abstraction. Three modes: a pure-Python local broker (yfinance fills, JSON-persisted), an Alpaca paper-trading adapter, and a “shadow” mode that runs both in parallel and exposes a divergence view. Real Alpaca live endpoints are hard-refused at multiple layers — to actually risk real money, the operator must deliberately override that refusal in more than one place.
A web dashboard. FastAPI on the backend, React (via CDN, no Node toolchain) on the frontend. Time-range pills, SVG equity curve, rolling-peak drawdown chart, top winners and losers, win-rate by rating / ticker / model, exit-reason breakdown, LLM cost versus realised P&L joined by run ID. The whole thing runs locally; nothing is sent to a cloud service.
Codex OAuth. Runs the engine on a ChatGPT Pro subscription via the Codex backend, so the LLM cost floor is effectively zero if you already have ChatGPT Pro. Token stored encrypted locally; falls back to the regular OpenAI API if you’d rather pay per token.
Multi-channel alerts. Slack, Discord, SMTP email — configurable filter on rating events and order fills. Append-only history kept locally. Webhook URLs masked in API responses so a screenshot can’t accidentally leak credentials.
MCP plug-ins. A registry for adding Anthropic Model Context Protocol servers (Kensho, Aiera, FactSet, Morningstar, LSEG, and others) as additional analyst tools. Each plug-in advertises its category — fundamentals, news, market data, social sentiment — and a probe endpoint tests credentials and lists the tools the plug-in exposes.
A few honest-by-design touches. Every generated report prepends “Research, not advice” and appends a footer with version, commit, provider, models used, run ID, and cost. Closed trades carry the same metadata. The intent is the same as Polybot’s calibration view: when the system loses money, the journal makes it impossible to pretend it didn’t.
The fork ships with over 520 passing unit tests across the engine, services, and HTTP routes. By Forezai’s standards, that’s a starting baseline, not a finish line.

The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns
Comes with secure packaging
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why this is a different bet, not a doubling down
After two weeks of measuring strategies that didn’t work, picking up another trading-research project might look like the wrong reflex. It’s worth being explicit about why this isn’t just “try harder with shinier tools.”
The bet here is on a different mechanism, not a different parameter setting. Polybot’s strategies are explicit rules: buy here, sell there, with these caps. The data on those is now reasonably clear — most of them are structurally negative-expectation when measured honestly. Adding more parameters wouldn’t change that.
TradingAgents is asking a separable question. Not “is this parameter setting profitable” but “does multi-agent LLM judgment, structured into specialised roles with built-in adversarial debate, produce decisions that survive contact with reality.” Those are different questions. The first is essentially exhausted on the strategies tried so far. The second is genuinely open.
Honest priors before running this thing in anger:
- It might fail too. LLMs are not oracles, and a sophisticated framework around language-model outputs does not change the underlying error rate of the model. Sample is still everything.
- If it appears to work, the most likely explanation is variance. The same trap that caught the first article’s “candidate edge” applies here. A high win rate over fifty trades means much less than it looks.
- If it appears to work for the right reasons — meaning the empirical win rate matches the model’s stated confidence, and the alpha-versus-benchmark persists across non-overlapping samples — that would be a meaningful research finding. Whether that happens, I don’t know. The whole point of putting it in the open is that the data will say.
What this is explicitly not: a launch announcement for a product anyone should connect a real brokerage account to. The Alpaca live endpoints are hard-refused at multiple layers in the code, and the design choice is deliberate. The right next step is data, not deployment.
![Developing Profitable Trading Strategies: A Beginner’s Guide to Backtesting using Microsoft Excel [Second Edition]](https://m.media-amazon.com/images/I/415igDkwYkL._SL500_.jpg)
Developing Profitable Trading Strategies: A Beginner’s Guide to Backtesting using Microsoft Excel [Second Edition]
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What’s open, what’s local
The TradingAgents fork is published on GitHub under the same author as Polybot, Apache-2.0 licensed. The upstream is cited and linked from every relevant surface — README, marketing pages, generated report footers. If anyone forks it again, the Apache-2.0 requirements (preserve the notice file, the attribution, the patent-grant clauses) apply.
What is not open: the operator’s running results, the specific watchlist, the per-agent prompt customisations, the alert channels, and the trade journals. Those are kept local for the same reason Polybot’s research notes and per-experiment trade data are kept local: publishing exact configurations encourages people to copy them with real money, which is the opposite of what an honest research project should do. Summary findings will be published. Recipes will not.
Both projects now live under a shared umbrella at the forezai.com marketing site — a small change, but worth noting: Forezai is becoming the brand for a family of trading-research instruments, not a single product. Two so far. Possibly more later, depending on what the next research question turns out to be.
The Polybot work is not abandoned. The fleet is still running, the bot is still publishing data, and a more focused subset of strategies will continue to collect samples for the calibration-by-model-probability analysis. The two products coexist; they ask different questions.
What week three will look like
Concrete next steps for the new project:
Run it on a small watchlist for a few weeks before publishing findings. A handful of tickers across two or three sectors. Long enough to gather sample, narrow enough to keep attention on what’s actually happening per agent. Avoid the noise of a 65-ticker autonomous loop until the smaller version has been read carefully.
Calibration view. The framework outputs a rating and (when configured) a probability or confidence. The honest measurement is the same one applied to Polybot’s fair-value model: when the system says “75% confident”, do the trades actually win 75% of the time? If the model is systematically over-confident, that bias dominates everything downstream.
Cost accounting. With Codex OAuth the marginal LLM cost is effectively zero, but with the public OpenAI API, each run is hundreds of agent turns. The system already logs cost per run. The honest question: cost per ticker, per rating, per profitable trade — does this scale economically if you ever did run it at real cost?
Alpha vs benchmark over non-overlapping windows. Not the within-sample alpha, which is trivially inflatable. Specifically: hold out one period entirely, run the system on the next, then check whether the held-out result matches the in-sample stats. If they diverge sharply, the in-sample was curve-fit.
This is week-one-territory work, deliberately. The hope is to write the week-three article from a position of “here’s what the data says about LLM-multi-agent stock research over its first useful sample.” The fear is that the article will be the same shape as week two: another candidate falsified at higher sample. Both outcomes are publishable.
On the broader stance
Two weeks of paper-trading data on prediction markets did not produce a money-making strategy. It produced something more useful: a clear demonstration, in public, that most retail-facing claims about prediction-market edge are wrong. The strongest signal across 25 experiments was on the losing side, not the winning side, and the one strategy that briefly looked like edge failed at higher sample.
If TradingAgents demonstrates the same thing about LLM multi-agent stock research, that’s a publishable result too. The fact that a sophisticated-looking framework didn’t beat the market doesn’t make it bad research; it makes it useful research, in a space where almost all of the public claims point the other way.
The bias of this whole project is straightforward: when the data says no, the dashboard says no, the article says no, and no one tries to retroactively rescue the thesis. That’s the contribution. The point is not to find a money-printing AI. The point is to put honest measurements of these systems into the public record, so the next person looking at the space starts a step further along than the last.
Final disclaimer
To be explicit, as in every article in this series:
- I am not a licensed financial advisor.
- Nothing in this article is investment advice, trading advice, or a recommendation to do anything.
- The software described trades simulated money by default. The operator does not currently run any of the described strategies with real money and does not intend to.
- Even with paper-trading-by-default, code can be reconfigured. If you fork TradingAgents and override the safety refusals to trade real money, you should expect to lose that money. LLM hallucination, model bias, market drift between decision and fill, exchange outages, and simple operator error each — independently — can cause losses materially worse than the simulation.
- A high win rate over a small sample is not edge. A small alpha-versus-benchmark over an in-sample period is not edge. Edge is what survives a fresh out-of-sample window with the same configuration.
- If you take this article as a reason to put money into an LLM-driven trading system — yours or anyone else’s — you have misread it. The honest takeaway is the opposite: nothing in this space has yet survived an honest test, including the system being introduced in this very article.
- Algorithmic trading, prediction markets, and on-chain markets are zero-sum after fees, dominated by sophisticated participants, structurally hostile to part-time retail strategies. Most participants lose money. The systems described in this series are no exception.
— Thorsten Meyer AI · The TradingAgents fork is open-source under Apache-2.0; the prior Polybot work is open-source under MIT. Both live under the Forezai umbrella. Each project publishes its results honestly when there are results to publish, and is quiet when there aren’t.