This is not financial advice. Nothing in this article should be used to inform real trading decisions. The bot described here trades exclusively with simulated money. If you build something similar and run it with real funds, you should fully expect to lose them — that remains the most likely outcome, by a wide margin, regardless of what any individual data point suggests.
What happened
Last week I published an honest report on the first ~700 paper trades from a multi-strategy bot running against Polymarket’s 5-minute Up/Down markets. The headline finding was that out of 21 parallel strategy experiments, exactly one showed the statistical signature of real edge: low win rate but with asymmetric payouts large enough to overcome it. That one strategy was a fair-value taker running on BTC, at the time up roughly +$800 on a $300 paper bankroll.
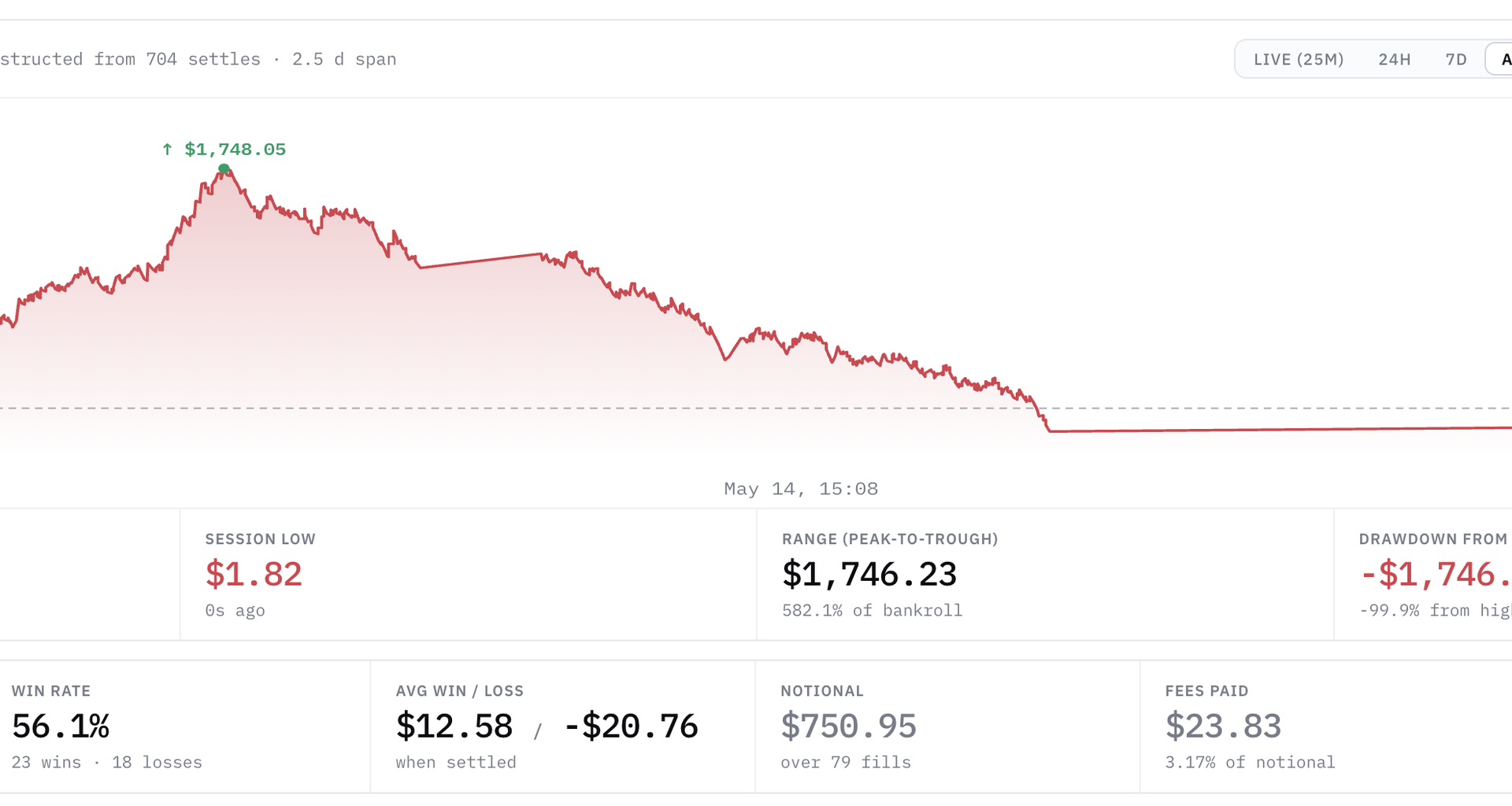
I was deliberately cautious about it: a few hundred settles isn’t enough to confirm edge, and the math signature alone doesn’t make a strategy real. But it was the only candidate worth watching.
This week, that strategy lost roughly $850 in a single overnight session. It’s now sitting at approximately $1.84 in equity — effectively wiped out. The total realised P&L on that experiment is now negative $298 across roughly 750 settled trades.

At the same time, a separate hypothesis I introduced mid-week — that a maker-quoter approach might avoid the fee tax and adverse-selection problems that crushed every other BTC strategy — has also been thoroughly falsified. The dedicated BTC maker experiment finished the week at $0.49 equity, with a 22% win rate over 120 trades. Informed flow crushes the quotes on 5-minute markets, exactly as I’d flagged as the central risk.
The fleet as a whole now stands at roughly −33% of bankroll across 25 parallel experiments. Aggregate paper P&L is approximately −$2,500 on $7,500 deployed.
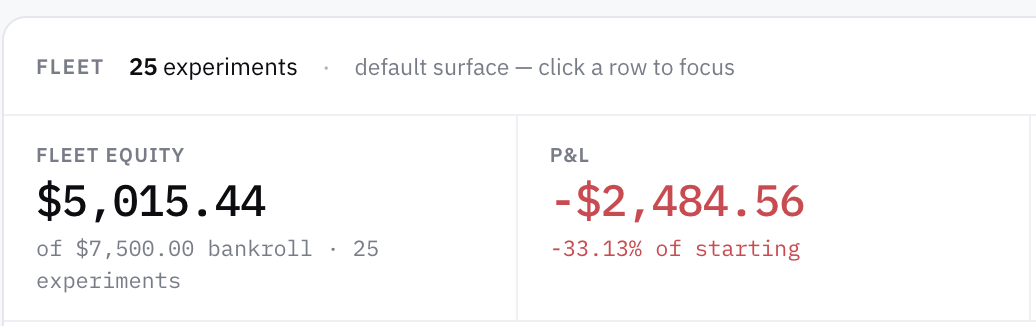
So: the one candidate is dead, the backup hypothesis is dead, and the larger fleet is firmly in the red.
That is the result.

Building a Crypto Trading Bot: A Developer's Handbook: Mastering Automated Strategies for Digital Assets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why this is the actual finding (not a bad week)
There’s a temptation, when a previously-promising signal disappears, to call it noise and keep running. Especially in trading, where everyone has heard “the market punished my edge temporarily” used as a permission slip for ignoring losses.
This time, three things make the collapse more substantive than “a bad week”:
The sample grew. The original positive read on the BTC fair-value strategy was from roughly 250 settled trades. The collapse happened across roughly an additional 500 settles. We didn’t just have one bad day inside an otherwise-good distribution — we had hundreds of new trades whose net contribution to P&L was strongly negative. Statistically, the prior is no longer “the strategy is positive”. The prior is now “the strategy was likely lucky for the first 250 settles and is reverting”.
The shape changed. During the positive period, the strategy had the right math signature: lower-than-50% win rate compensated by asymmetric payouts. During the collapse, the win rate stayed similar but the average payout per win shrank and the average loss per loss grew. That’s not noise around an edge; that’s the underlying model being wrong about which side of the market it should take.
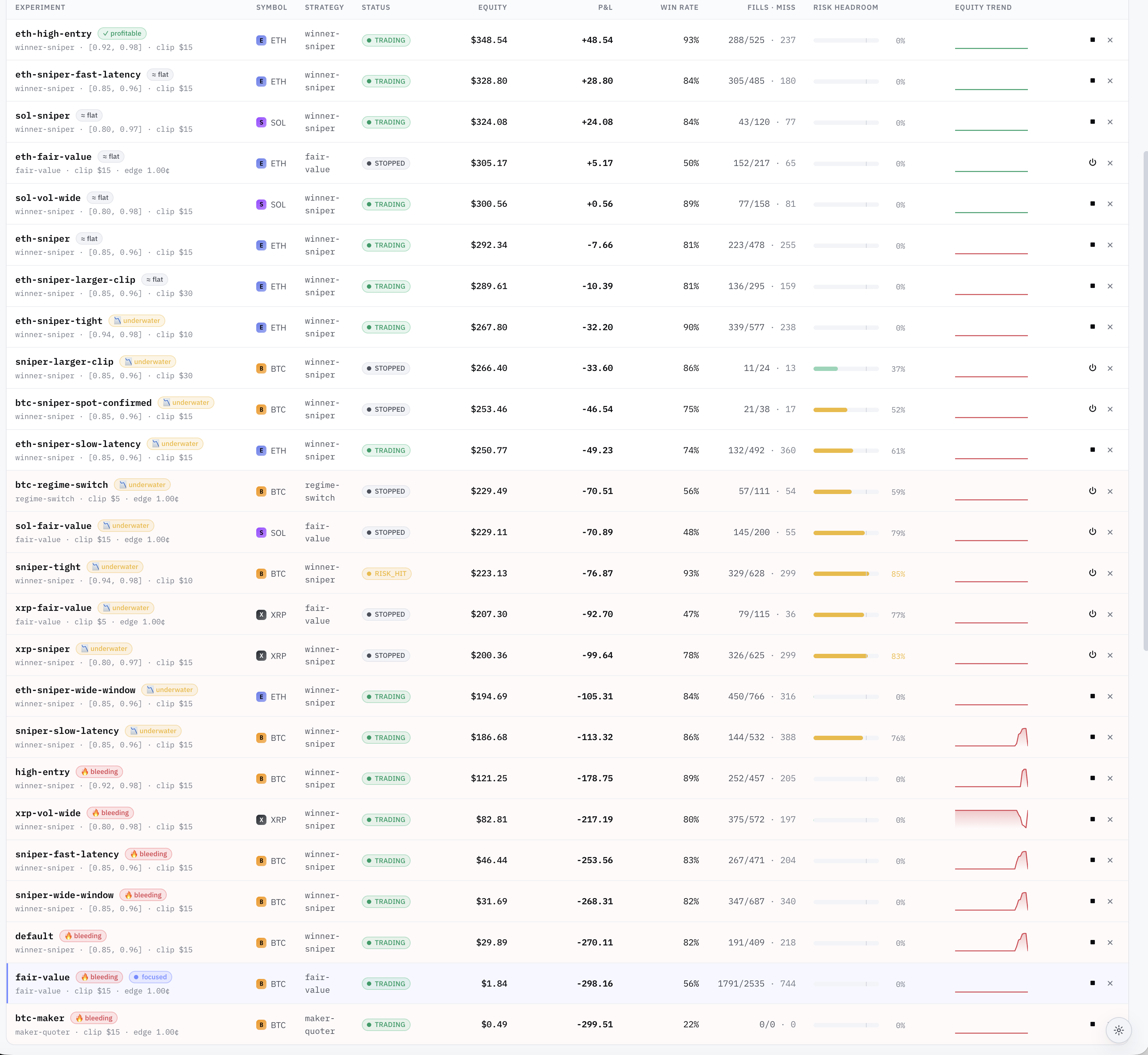
Every other strategy keeps confirming the harder lesson. Six different wide-band BTC sniper variants are all underwater. Three different fair-value-on-alts experiments have all run themselves to roughly zero. The one regime-switching strategy underperforms each of its component strategies in isolation. These results all point in the same direction: the alleged edges aren’t there.
The cleanest single number from the week is this: across the whole fleet, the empirical win rate is 78.3%, and the aggregate P&L is negative. That is the entire trap of prediction-market trading on short-duration binary markets compressed into one stat. You can win four out of five trades and still lose money, because the one loss is bigger than the four wins put together. Most retail-facing strategies that look impressive are doing exactly this and not saying so.

Bitcoin Merch® NerdMiner 2 – Large Screen USB Solo Miner with WiFi
Learn & Explore: Great for educational use and tech enthusiasts.
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What survives, and why I don’t trust it
Five experiments are net positive at the end of the week. They are not five independent confirmations of anything. Three of them are variants of the same idea trading the same underlying — closer to one bet voting three times than three separate signals. A fourth has the right math shape but is up only a few dollars over 120 settles, which is well within the variance band; its more-tested BTC sibling just collapsed under the same shape. The fifth is essentially flat: the strategy is doing exactly what the math says, neither making nor losing meaningful money.
Looking honestly at those five: none have enough sample independence to call edge. The math says four of them shouldn’t be positive at the win rates they’re showing — they are positive because of variance. Run them another week and most or all of them likely revert.
I am specifically not naming the strategies, the entry-price bands, or the parameter settings. Partly because publishing exact recipes for strategies that haven’t been confirmed encourages people to copy them with real money. Partly because if any of the survivors does turn out to have genuine edge over a much larger sample, naming it now is just giving away the only finding the project has produced.
But the qualitative point stands: nothing in the fleet has yet earned the right to be trusted with real capital, and the early front-runner has now been struck off the list.

Quantitative Trading with R: Understanding Mathematical and Computational Tools from a Quant’s Perspective
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What this actually teaches you
Three things, only one of which requires the bot:
One. Win rate by itself tells you nothing about whether a strategy makes money. A strategy that wins 95% of the time on $0.95 entries breaks roughly even before fees. A strategy that wins 90% on $0.95 entries loses money. A strategy that wins 50% on $0.50 entries with symmetric payouts also breaks even. Without knowing the relationship between win rate and the implied probability of the entry price, the win rate is a vanity metric. Most retail-facing trading content quotes win rate alone, which is a tell.
Two. Sample size matters more than anyone wants to admit. The same strategy looked like edge over 250 settles and looked like noise-with-a-side-of-loss over 750. That ratio — three times the sample, opposite conclusion — is not unusual; it’s the normal experience of someone running statistically marginal strategies. If you find yourself unable to wait for the sample to grow before scaling up, the strategy isn’t ready for scaling up.
Three. Different markets are not the same market. The BTC fair-value strategy that briefly looked promising on BTC failed catastrophically on SOL, ETH, and XRP. Then it failed on BTC too. Each underlying has its own volatility distribution, its own microstructure, its own dominant participants. Calibrating a model on one underlying and assuming it generalises is one of the cheapest mistakes available. The bot has now demonstrated that, with paper bankrolls, four times.

Bulls or Bears Slot Gamified Trading Platform: : Gamifying the Financial Markets Through Slot-Based Trading
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What I’m not doing next
I’m not doubling down. There is a temptation here to “fix” the failed strategies — to tweak the model, narrow the entry band, add a directional filter, switch fee assumptions — and find a configuration that would have made money on the data we have. That’s curve-fitting in slow motion, and it has wrecked more retail trading experiments than market behaviour has.
I’m not turning anything LIVE. The point of running this as a paper experiment was to find out whether any of it works before risking real money. The answer the data is giving is “not yet, possibly not ever, and definitely not at default risk gates”. That’s a complete answer. The honest response is to keep the LIVE switch off.
I’m not pretending the positive cluster is a portfolio. Three correlated bets on ETH dressed up as three independent strategies don’t add up to diversification. If the only thing that worked was a single correlated cluster on a single underlying over a single week, that’s one observation, not a strategy.
What I am doing next
The next phase is methodological, not parameter-fitting. Concrete:
Long-horizon replay. The bot records every market tick to disk. I want to replay weeks of recorded data through the strategies that briefly looked positive, to see whether they were positive on multiple non-overlapping samples or just lucky on the calendar window I happened to observe. Replay also lets me run more parameter combinations cheaply, without burning fresh paper bankroll.
Better calibration views. The dashboard’s calibration panel buckets trades by entry price and reports the gap between the market’s implied probability and the empirical win rate. The next step is bucketing by model predicted probability and looking for honesty: when the model says “75% confident”, does the side actually win 75% of the time? If the model is biased, the strategy will be biased.
A smaller, more focused fleet. Twenty-five experiments is too many to maintain attention on. I’ll likely cut the fleet to a handful — the marginal candidates, plus deliberate control variants that should mathematically lose, so I can confirm losses are tracking the math rather than running away from it.
I’ll keep writing these. The “is there any strategy working?” question is the wrong one. The right one is “what definitely doesn’t work, and how confidently?” — and at the end of week two, the answer to that is much clearer than at the end of week one.
A note on what’s worth publishing
Most write-ups of trading research are unblinded success stories. Someone backtested a strategy, it worked, they’re sharing the results. Survivorship bias means you mostly don’t hear from the people whose strategies didn’t work. The data they produced — the negative results — is at least as valuable as anyone’s positive results, and almost nobody talks about it.
I’m trying to do the opposite. This series is committed to publishing what happens regardless of whether what happens is flattering. Week one’s update had a candidate edge. Week two’s update doesn’t. Week three’s may or may not. The point isn’t to find a money-printing strategy; the point is to put real, honest research about prediction-market trading into the public record so the next person doesn’t have to repeat the same uninformed optimism.
If you find that useful, that’s the contribution. If you were hoping for a strategy you could copy, that was never on offer.
Final disclaimer
To be very explicit, as last time:
- I am not a licensed financial advisor.
- Nothing in this article is investment advice, trading advice, or a recommendation to do anything.
- The bot described trades simulated money. No real funds are at risk. The author does not run any of the described strategies with real money and does not intend to.
- Early-stage paper-trading results — including the previously-positive results that have now collapsed — are not predictive of real-money outcomes. Real markets are worse than simulations, not better, on every relevant metric: slippage, latency, fill failures, adverse selection.
- If you take this article as a reason to put money into any prediction market, you have misread it. The honest takeaway is the opposite: a multi-strategy experiment has now demonstrated, in public, that the strategies most retail content claims work do not work, and the one that briefly looked like it might work has now broken too.
- Prediction-market trading is a zero-sum game after fees, dominated by sophisticated participants, structurally hostile to part-time retail strategies. Most participants lose money. The strategies in this experiment are no exception.
— Thorsten Meyer AI · Part 2 of an ongoing series. The bot, its source code, the dashboard, and the parameter sweeps are open-source under the MIT license. The strategy specifics and the per-experiment trade data are kept local; the honest summary results are what get published.







