
This is not financial advice. Nothing in this article should be used to inform real trading decisions. The software referenced trades simulated money. If you build something like it and run it with real funds, the most likely outcome — by a wide margin — is that you lose those funds. That holds whether you use a Brownian model, a 100-million-parameter foundation model, or any other forecaster.
What this is
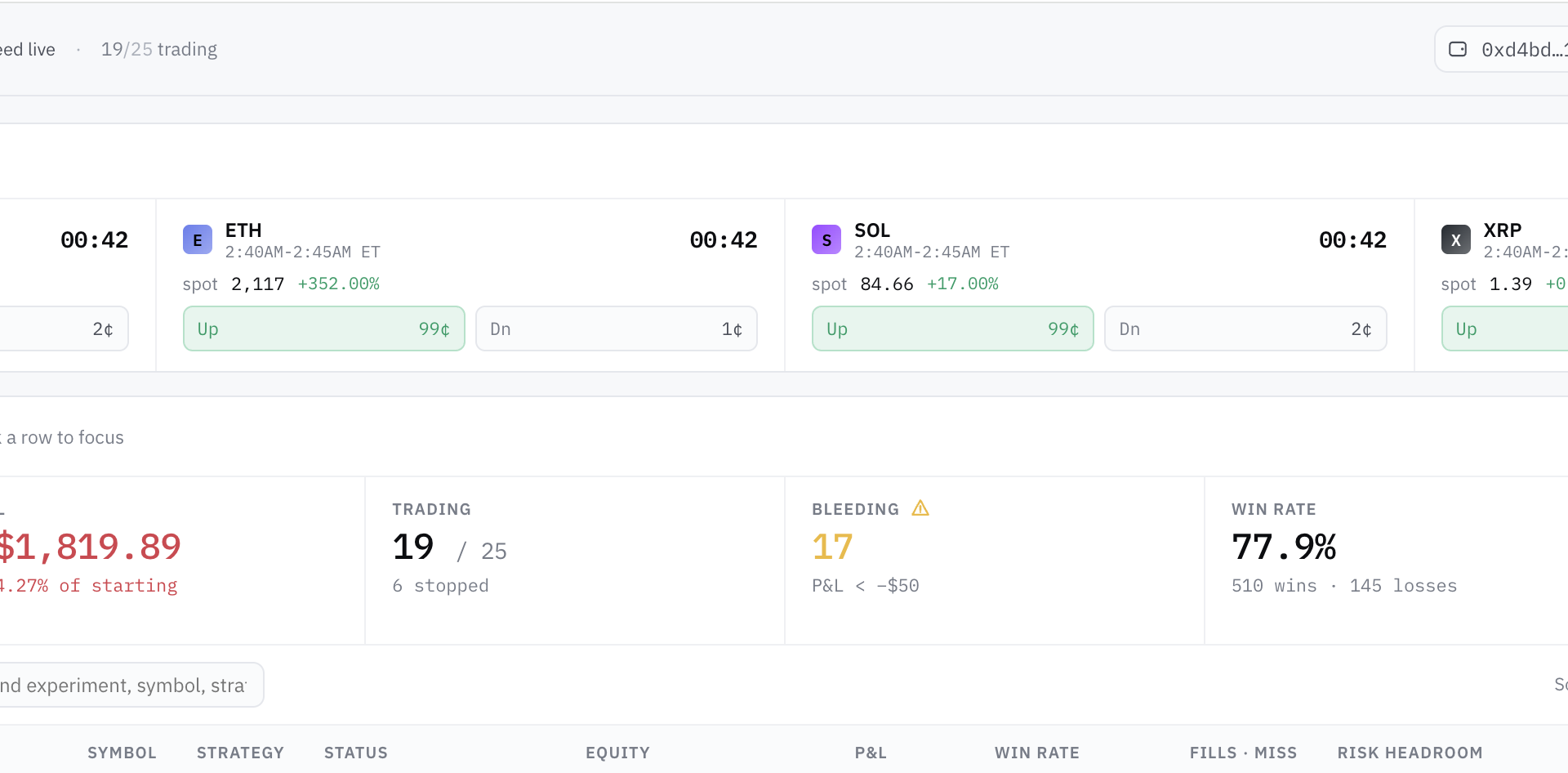
For two weeks I have been running an open-source paper-trading bot called Polybot against Polymarket’s 5-minute Up/Down crypto markets, publishing what the data says honestly. The headline finding from those two weeks was uncomfortable: of 21+ parallel strategy variants, exactly one had the mathematical signature of real edge (lower-than-50 % win rate combined with asymmetric payouts when right), and even that one collapsed at higher sample. Most “edges” the bot found were mechanical artefacts that did not survive a fresh sample.
That conclusion raised an obvious follow-up. The bot’s fair-value strategy uses a geometric Brownian motion model to estimate the probability of BTC closing above its window-open price at the 5-minute mark. Brownian is a 1900s mathematical assumption — independent, normally-distributed log-returns — applied to a market that is none of those things. The question worth testing: would a modern, learned model trained on millions of real candlesticks do better than this 100-year-old approximation?
There happens to be a credible candidate available. Kronos is an open-source MIT-licensed foundation model for financial time series. 25,000+ stars on GitHub. An AAAI 2026 paper behind it. Four model sizes from 4M parameters to 102M open and 499M closed. Trained on candles from 45 global exchanges. The authors are explicit that it is a research model and not a trading system — exactly the right thing for an honest test.
So I tested it. Offline. Against the bot’s own historical trade log. With an out-of-sample split because the previous two weeks already established that within-sample is meaningless. This week’s article reports what happened.

The Automated Cryptocurrency Trading – CREATING CRYPTOCURRENCY TRADING BOT: How anyone can make money trading with Python code. Easy step by step guide … in blockchain. (Crypto Investment)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The test
I built a small Python tool that does the following for every paired (FILL → SETTLE) trade Polybot has recorded across the running session — 497 of them, all BTC:
- Reconstruct the OHLCV context of the 60 minutes leading up to fire-time. Pull from the bot’s local Binance recording where available; fall back to Binance’s public klines API otherwise. Cache to parquet so re-runs cost nothing.
- Recompute the Brownian baseline in Python — a line-for-line port of the bot’s own
fairValuePUp(spot, openPrice, secondsLeftFrac, windowVol)formula. The Python port matchesscipy.stats.norm.cdfto three decimal places and is verified against the bot’s own logged values where available. - Read off the market-implied probability from the FILL price (what Polymarket’s order book thought the side was worth at the moment of fire).
- Run Kronos-small (24.7M parameters) on the OHLCV context, sample 16 forecast paths to the window’s end, and count the fraction of paths in which the underlying closes above the window-open price. That fraction is Kronos’s predicted p(Up).
- Record
(p_brownian, p_market, p_kronos, actual_outcome, P&L)for the trade.
Then score each model by three things:
- Brier score — mean of squared error between predicted probability and actual outcome. The standard scoring rule for probability forecasts. Lower is better.
- Log-loss — penalises overconfidence. A model that says “99 % sure” and is wrong loses a lot here. Lower is better.
- Hypothetical P&L — counterfactual: if Polybot had used each model’s p(Up) to decide whether to fire, with the same edge-margin and risk gates it actually used, what would the bottom line have been?
And the discipline that matters: sort all 497 trades by fire-time, split into first half and second half, report all metrics on both halves separately. If a model wins on the first half but ties or loses on the second, that’s the curve-fit-in-slow-motion pattern the previous two articles named, and it doesn’t count as edge.
Run time: 11 minutes of clock-time on a Mac M-series with the PyTorch MPS backend. The whole thing is roughly 1,300 lines of Python and is open-source-grade reproducible from the public methodology document Polybot ships at docs/RESEARCH_PIPELINE.md. Specific numbers stay local; the methodology is public.

Python Algorithms: Mastering Basic Algorithms in the Python Language (Expert's Voice in Open Source)
Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The numbers
On the full sample of 497 paired trades:
| Model | Brier (lower = better) | Log-loss (lower = better) |
|---|---|---|
| Brownian | 0.193 | 0.567 |
| Market-implied | 0.211 | 0.604 |
| Kronos | 0.213 | 1.080 |
Brownian beats both. Kronos’s log-loss is roughly twice Brownian’s, which is the signature of a model that makes confident, wrong predictions in the tails. The market-implied probability sits in between — Polymarket’s order book is reasonably calibrated on these markets, slightly worse than the bot’s Brownian, slightly better than the foundation model.
On the out-of-sample test half (the last 249 trades, never seen by the model’s training distribution and chronologically separated from any in-sample tuning):
| Model | Brier on test half |
|---|---|
| Brownian | 0.188 |
| Kronos | 0.189 |
Difference: 0.0011. Statistically indistinguishable.
This is the verdict the test was designed to deliver. A 0.0011 Brier-score gap on 249 trades is well inside the noise band of repeated runs with different Kronos sampling seeds. Kronos does not beat Brownian on a held-out, chronologically-separated sample. The case for wiring Kronos into the bot as a live strategy — what we had set up as “Stage 2” of the pipeline if Stage 1 produced a clear signal — is not earned by this data. So Stage 2 is not happening.
That’s the answer to the question this article set out to test: would a modern learned model beat the bot’s Brownian baseline? For 5-minute BTC at the horizons the bot trades, the open Kronos-small checkpoint does not. Stop.

Financial Literacy Flashcards for Kids & Teens | 108 Money & Finance Terms with Images, Definitions & Discussion Prompts | 3 Skill Levels (Beginner–Advanced) | Deluxe Set with Digital Activity Book
📘 BONUS Digital Companion Activity Book: Includes a printable 108 page companion activity book with structured exercises and…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why this is more interesting than a clean “no”
The result is not boring. Look at what happens when you replay the same data through a hypothetical-P&L counterfactual — what if Polybot had used each model’s probability to decide whether to fire, instead of just scoring them on probabilistic calibration?
| Model | Hypothetical fires | Win rate | Hypothetical net P&L |
|---|---|---|---|
| Brownian | 279 | 49.1 % | +$465 |
| Kronos | 201 | 60.7 % | +$538 |
Kronos fires roughly 28 % less often and wins more reliably when it does. The counterfactual net P&L is slightly higher than Brownian’s. By operational standards, Kronos is the better trader.
But by probabilistic standards, Kronos is a worse forecaster. Look at the calibration deciles. Kronos predicts a 2.4 % chance of winning — and those trades actually win 20.4 % of the time. Kronos predicts an 84 % chance of winning — and those trades actually win 69.6 % of the time. The model is systematically over-confident in the tails. It thinks it knows more than it does at both ends, even while it picks correct directions more often on average.
The paradox is interesting because it tells you which metric to care about depending on what you are trying to do. If you are building a fully-probabilistic trading system where the probability feeds an expected-value calculation against the market’s implied price — which is what Polybot’s fair-value strategy does — calibration is everything, and Kronos’s calibration is bad enough to disqualify it. If you are using the model as a directional signal in a broader system that does its own sizing — closer to how Forezai’s separate TradingAgents project uses analyst outputs — Kronos’s directional accuracy might still be useful even though its probabilities are unreliable.
Both interpretations are honest. Neither earns the model a place in Polybot. One of them might earn it a place, later, in TradingAgents — as a 5th analyst voice that votes on direction without being trusted for calibrated odds. That experiment is not what this week tested; it is a separate hypothesis for a separate week.

Bitcoin Coin and Grey Divot Repair Tool with Removable Bitcoin Ball Marker
Collectors Edition – A true crypto collector's gem. Meticulously crafted with impeccable quality, this unique masterpiece celebrates the…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What the data does NOT say
I want to be careful here because the temptation in research write-ups is to over-claim what a single test means. Three things this run does not prove:
It does not prove Kronos is bad. It tested one open checkpoint (Kronos-small, 24.7M parameters) at one horizon (60 minutes of context predicting ~10 seconds to ~5 minutes ahead) on one market (Polymarket’s 5-minute BTC Up/Down). Kronos’s training distribution leans toward daily and hourly bars, not sub-minute crypto microstructure. A different model size, a different horizon, a different market could easily produce a different verdict. The authors of Kronos would, I expect, find this test unsurprising and possibly a misuse of the model’s designed niche.
It does not prove Brownian is good. It only proves Brownian was not worse than Kronos at this task. The previous two weeks established that Brownian’s own absolute performance is marginal at best — the strategy that uses it just collapsed at week-2 sample. Beating Kronos here is faint praise. Both models may be poor at this market; one is just less poor.
It does not prove anything about Stages 2 or 3. A negative Stage-1 result kills the immediate plan for this candidate, this horizon. It does not condemn the broader research pipeline of testing learned models against classical baselines. The next candidate (Chronos, TimesFM, Lag-Llama, a Kronos finetune on 5-min crypto data specifically, a different model entirely) goes through the same gauntlet. Most will fail it. That is the gauntlet doing its job.
What’s worth borrowing
A research result is only useful if someone can re-run it, contest it, or extend it. The full pipeline is open-source under docs/RESEARCH_PIPELINE.md on the project repo. The shape is product-agnostic: any future candidate forecast model gets a sibling directory in research/, reuses the same Brownian baseline, the same trade-log loader, the same OHLCV fetcher, the same metrics, the same out-of-sample split, and only ships a new model-specific runner. The contract is same gauntlet, different model, same discipline.
The specific numbers stay local. The methodology is public. That distinction is important: publishing reproducible parameter recipes for strategies that might be marginally profitable encourages people to copy them with real money, and the prior on real-money outcomes when copying retail strategies is “they lose.” Publishing the methodology lets the next person test their own model honestly without inheriting any of mine.
Where the series goes next
Week four is one of three possible threads. I am genuinely undecided which:
- A second-tier candidate model. Amazon’s Chronos is the obvious counterpart to Kronos — same general shape, different training corpus, also open-source. Running it through the exact same gauntlet would say something about whether the negative result is specific to Kronos or generalises to learned models in this regime.
- Kronos with a finetune on 5-min crypto data. The Kronos repo ships a finetuning pipeline. Taking the open Kronos-base checkpoint, finetuning on the bot’s own recorded BTC tick history, and re-testing would isolate “is the pretrained distribution wrong for crypto?” from “is the model architecture wrong for this horizon?”
- A live-trading update on Polybot. The fleet has been running paper trades continuously across these three weeks. A fresh aggregate-P&L view, with the same calibration-style analysis applied to live performance rather than historical replay, is overdue.
Each is a separate article. The pattern across them is the same: honest measurement, out-of-sample discipline, no rescue narratives when something doesn’t work.
Final disclaimer
To be very explicit, as in every article in this series:
- I am not a licensed financial advisor.
- Nothing in this article is investment advice, trading advice, or a recommendation to do anything.
- The bot described trades simulated money. No real funds are at risk. The author does not run any of the described strategies with real money and does not intend to.
- Kronos is a research model. The authors of Kronos themselves state in the repository that it is not intended as a production trading system. Anyone deploying it — or any successor — as a live trader against real money should expect to lose that money. This week’s test is consistent with the authors’ own framing.
- Out-of-sample beats in-sample. Repeated tests beat single tests. Multiple models beat one model. This week tested one candidate at one configuration on one market. Generalising further is the reader’s risk to take, not the article’s claim to make.
- The same disclaimers from the prior two weeks apply: most trading strategies — parametric, learned, or hybrid — do not work; most “edges” in retail-facing materials are mechanical illusions; prediction-market and short-horizon crypto trading are zero-sum after fees; most participants lose money; the systems in this series are no exception.
— Thorsten Meyer AI · Part 3 of an ongoing series. The methodology used in this article is public on the repo’s docs/RESEARCH_PIPELINE.md. The specific results live locally and are summarised here; the raw per-trade CSV stays on the operator’s machine. Both Polybot and Kronos are open-source — Polybot under MIT, Kronos under MIT, both with explicit “research, not financial advice” framing.







