There is a particular kind of claim that deserves to be read slowly, because it is easy to dismiss as hype and easy to over-read as doom, and both reactions miss what is actually being said. Anthropic’s new piece from The Anthropic Institute, When AI builds itself, makes one of those claims: that AI is already, measurably, accelerating the development of AI — and that if a single remaining bottleneck gives way, the technology could begin improving itself in a loop that runs at the speed of compute rather than the speed of human work.
The phrase for that loop is recursive self-improvement, and the piece is careful in a way worth honoring up front. We are not there yet, the authors write, and it is not inevitable. But it could arrive sooner than most institutions are prepared for. What makes the argument unusual is that it isn’t built on speculation about future systems. It’s built on data — public benchmarks, and a stack of previously unreported numbers from inside Anthropic itself — about what AI is doing to AI development right now. This is a slow walk through that evidence: what it shows, where it’s soft, what the authors think it means, and the genuinely hard question it leaves open.
When AI builds itself
Anthropic is delegating a growing share of AI development to AI. Taken far enough, that points to a system that designs its own successor — recursive self-improvement. Not here yet, not inevitable. But the case isn’t speculation: it’s data on what AI is doing to AI development right now.
The curve that hasn’t bent
METR tracks the length of tasks AI can reliably complete on its own. That horizon is doubling roughly every four months — up from every seven. Anyone can check this in public data.
Task horizon — how long a job AI can handle solo
Each model handles dramatically longer tasks than the one a year before. The line keeps going up.

AI-Assisted Coding: A Practical Guide to Boosting Software Development with ChatGPT, GitHub Copilot, Ollama, Aider, and Beyond (Rheinwerk Computing)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Two kinds of work, one persistent gap
Building a frontier model splits into engineering and research. Across both, the pattern is the same — and so is the one thing AI still can’t do well.
Code, infrastructure, training
Claude can take an underspecified problem and find a method. Humans supply the goal; they no longer need to supply the method.
Which experiments, what they mean
Claude can match or outperform skilled humans at executing a well-specified experiment. But choosing which experiment still needs a human.
The same ladder Anthropic employees climb with experience
![Claude AI for Beginners Bible: [5 in 1] The Ultimate Guide to Automate Your Work, Save Hours Every Week, and Use AI for Real-World Results](https://m.media-amazon.com/images/I/415+fSJacsL._SL500_.jpg)
Claude AI for Beginners Bible: [5 in 1] The Ultimate Guide to Automate Your Work, Save Hours Every Week, and Use AI for Real-World Results
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Watch the human share shrink, rung by rung
Walk up the four stages of AI development. At each, the human/AI split shifts — and the real internal numbers show exactly where AI has reached parity, gone superhuman, or still trails. Tap a rung.
The human role across the development loop
The doing now costs almost nothing in human time. What’s left is the deciding.

Learning Resources STEM Simple Machines Activity Set
- Explores Simple Machines & Concepts: Hands-on STEM activities with levers and pulleys
- Supports Science & STEM Learning: Guided experiments and open-ended activities
- Suitable for Kids 5+ Years: Designed for early elementary science exploration
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Agents ran an open research project end to end
April 2026: the first demonstration of Claude running an open-ended research project from hypotheses to findings — on a real AI-safety problem.
Can a weaker model reliably supervise a stronger one?
Agents were left to solve it: proposing hypotheses, testing them, sharing findings across parallel agents, iterating. Measured against the gap between a “floor” (weak supervisor alone) and “ceiling” (strong model trained on correct answers).
(humans: ~23% in a week)
· ~$18,000 compute
the agents themselves

CLAUDE AI UNLEASHED From First Prompts to Pro: The Complete Guide to Claude AI for Writing, Research, Coding, and Business (The Claude AI Mastery Series)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Picking a better next step than the human
Real research sessions where a human took a wrong turn. Models saw only the work before the detour and proposed a next step; a judge that knew the outcome scored them. The day-to-day of research is this chain of next-step calls.
“Can the model pick a better next step than the human?”
Share of moments where the model’s next step was judged better. The amber line is the practical ceiling (an ideal answer that could see the whole session).
It depends on whether the trend continues — and what we do
The piece refuses a single prediction. It lays out three scenarios, and is clear about which it finds most likely.
The exponentials turn out to be S-curves
Maybe taste can’t be scaled into existence; maybe the constraint is the supply chain — chips, grid, interconnect — not intelligence. Even so, the world still changes: Glasswing’s Mythos found 10,000+ critical vulnerabilities in weeks, and a 100-person firm does the work of 1,000.
included for completeness · they doubt itDevelopment automates; humans still steer
100-person companies doing the work of tens of thousands — revolutionary, but turnable to harm (population-scale surveillance, tailored manipulation). Bound by Amdahl’s law: speeding one part shifts the bottleneck — which is exactly why human code review became Anthropic’s new chokepoint.
★ they think we’re likely heading hereAI designs and refines its own successors
Progress paced only by compute. Humans move to oversight of an expanding “virtual lab.” The future they understand least — especially whether alignment holds, or whether rare misalignments compound as models build successors, until control slips.
the one they’re most uncertain aboutBuild the option to slow down — verifiably
The piece ends on policy, not product. A unilateral pause just changes who leads; what’s missing is the ability to verify others have actually slowed.
Why a credible pause is hard — and worth building toward
A slowdown that only lets the least cautious catch up leaves everyone less safe. So the goal is the option: systems that let frontier labs verify others have genuinely stopped. Anthropic says if such systems existed and peers paused verifiably, it expects it would too.
Detection beats verification — and even that’s tough
Training runs are easier to conceal than missile silos, inputs are general-purpose, and whoever continues while others pause inherits the lead.
We’ve done it before — slowly
Regimes like the INF Treaty built verification and trust over decades. The authors’ blunt line: “We don’t have that long.”
Reading it in proportion
- This is one lab’s account of its own internal data — much previously unreported, not independently audited.
- The soft spots are stated in the original: lines-of-code overstates productivity; the self-reported 4× is probably high; the headline research result didn’t transfer to production scale; the next-step test used cherry-picked moments.
- “More autonomous” is not “fully autonomous” — every standout result still had a human framing the problem and defining success.
- That the authors surface these caveats themselves — against their own incentive — is part of what makes the document serious.
The one-sentence version, and why each clause matters
Here is the thesis compressed: AI can increasingly do the doing of AI research — writing the code, running the experiments, producing the results — while humans still hold the deciding: which problems matter, which results to trust, when an approach is a dead end. Recursive self-improvement is what happens if that last human-held piece, research taste, also falls to automation.
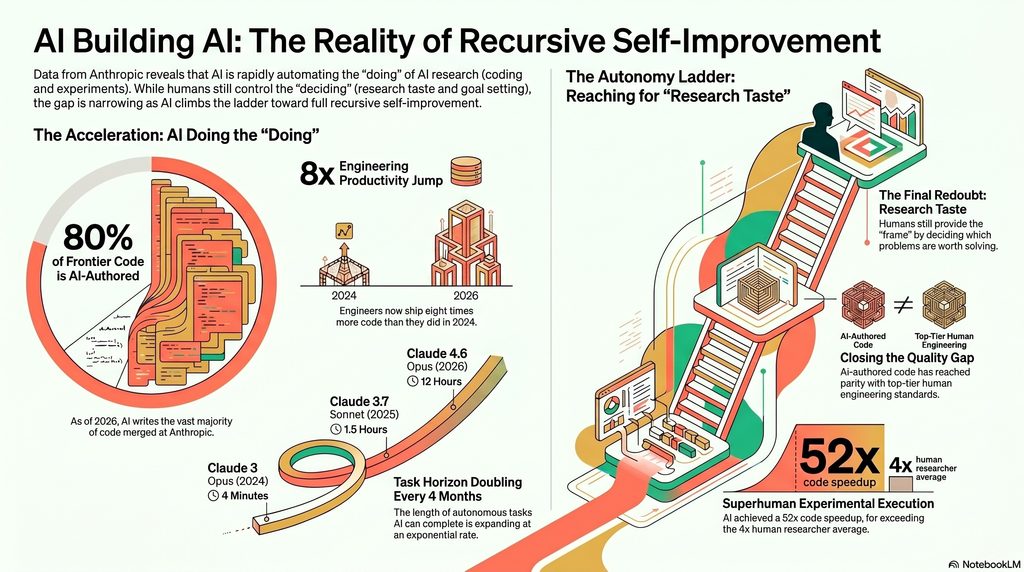
Every clause there is load-bearing. “The doing” is the part the evidence shows is already largely automatable. “The deciding” is the part the authors repeatedly, almost insistently, flag as the persistent gap. And the conditional — if taste falls — is the whole ballgame, the thing the piece is honest about not knowing. The headline number they offer as an opening illustration sets the stakes plainly: today, Anthropic engineers on average ship 8× as much code per quarter as they did across 2021–2025. That is not a forecast. That already happened.
Part one: the view from outside
Before turning inward, the piece establishes that the acceleration is visible in public data, where anyone can check it. The cleanest measure comes from METR, which tracks the length of tasks AI can reliably complete on its own. That horizon has been doubling roughly every four months — up from an earlier trend of doubling every seven. The concrete trajectory is vivid: in March 2024, Claude Opus 3 could handle software tasks that take a human about four minutes; a year later, Claude Sonnet 3.7 managed tasks of about an hour and a half; a year after that, Claude Opus 4.6 managed 12-hour tasks. If the trend holds, the authors note, tasks that take a skilled person days come into range this year, and week-long tasks in 2027.
The same shape appears on benchmarks built to resist it. SWE-bench hands a model a real open-source codebase and a real bug report and asks for a fix that passes the project’s own tests; models went from low single digits to saturating it in two years. CORE-Bench tests whether a model can reproduce the results of a published paper — a prerequisite, the authors note, for conducting original research — and AI went from roughly 20% success in 2024 to saturating it fifteen months later. And METR found that Claude Mythos Preview could work for “at least” 16 hours, at the upper end of what they can currently measure without building harder tasks. The pattern across all of these is the same: a capability sits near zero, then climbs a curve that hasn’t yet bent.
But public benchmarks have a ceiling on what they can tell you. They measure how good models are at tasks; they can’t measure what those models are doing to the pace of AI development inside the labs. For that, you need numbers the labs don’t usually share — which is what makes the next section the heart of the piece.
Part two: the view from inside, and the framework that organizes it
The authors split frontier-model development into two kinds of work, and the distinction structures everything that follows. There is engineering — writing code, standing up infrastructure, overseeing training. And there is research — deciding what experiments to run, interpreting results, choosing what to try next.
Across both, they offer a one-line summary that is the most important sentence in the piece: in engineering, Claude can take an underspecified problem and find a method — humans supply the goal but no longer the method; in research, Claude can already match or outperform skilled humans at executing a well-specified experiment; but large gaps persist when it comes to choosing goals in either domain. That is the gap between AI today and a system that could autonomously design its successor, stated with unusual precision.
They make it concrete with a ladder familiar to anyone who has been promoted. A junior person executes a task someone else specified: the export button is broken, fix it. A more experienced one is handed a goal and designs the approach: investigate why the network slows under heavy load. The most senior decide which problems are worth working on at all: what should the team build next quarter? The internal data, they argue, shows Claude climbing this ladder — strong at the bottom rungs, improving in the middle, still weakest at the top. The rest of the evidence is best read as a tour up that ladder.
Part three: writing code — from single digits to four-fifths
Start at the bottom rung, where the evidence is strongest. As of May 2026, more than 80% of the code Anthropic merges into its codebase was authored by Claude. Before Claude Code launched in research preview in February 2025, that figure was in the low single digits. In roughly fifteen months, the authorship of a frontier lab’s own code inverted.
The productivity shape is just as striking, and the authors are scrupulous about it. Lines of code merged per engineer per day stayed flat across Anthropic’s first four years (2021–2024), then began climbing in 2025 when Claude started running code rather than just suggesting snippets to copy and paste, and steepened again in 2026 as models began working autonomously over longer horizons. Two inflection points, both tied to capability jumps. By the second quarter of 2026, the typical engineer was merging 8× as much code per day as in 2024 — because Claude writes much of it while the engineer directs and reviews.
Crucially, they don’t oversell it. Lines of code is an imperfect measure — it counts quantity, not quality — so 8×, they say plainly, is almost certainly an overstatement of the true productivity gain. And they note Anthropic doesn’t reward people for lines written, so the increase reflects people choosing to let AI write more, not gaming a metric. That self-correction matters, because it’s the difference between a marketing number and an honest one. The supporting evidence rounds it out: a March 2026 poll of 130 research-team employees put the median self-estimated uplift from Mythos Preview at about 4× — which the authors again caution is probably too high, citing research that developers overestimate AI’s help, while still finding the broad claim plausible. And there’s the kind of work that simply wouldn’t have happened otherwise: in April 2026, Claude shipped over 800 fixes that cut a class of API errors by a factor of a thousand, work the supervising engineer estimated would have taken a human four years, because holding that much unfamiliar context is something humans are bad at and a model is not.
Part four: is the code any good? The quality gap, closing
Quantity is the easy part to doubt, so the authors confront quality directly, defining “good code” as two things: it works, and another engineer can understand and build on it.
On the first, the evidence is clean. The rate at which Anthropic staff correct, redirect, or take over mid-task from Claude has fallen steadily for a year — including on the hardest, least-specified problems, the ones where the engineer isn’t even sure what the answer looks like. On the most open-ended tasks, Claude’s success rate hit 76% in May 2026, up fifty percentage points in six months. Their example has the texture of real incident response: a routine upgrade started crashing tens of thousands of training jobs; an engineer pointed Claude at the live incident with little more than some text and cluster access; Claude worked through running jobs, tested one environment setting at a time, isolated a single obscure debugging flag as the culprit, reproduced the crash, and confirmed a fix — about two hours for what would normally be two to three days of work.
On the second criterion — readability, the part that lets a team build on the code — the gap persists but is closing fast, and the authors quote their own internal view rather than smoothing it over: Claude-written code was somewhat worse than human-written code at Anthropic in late 2025, is roughly at parity today, and they expect it to be strictly better within the year. The most telling detail is what this has done to their process. Every proposed change is now read by an automated Claude reviewer hunting for bugs and security flaws before it can merge — and a retrospective found that such a review would have caught roughly a third of the bugs behind past production incidents on claude.ai, mistakes made by engineers who are among the best in the world at this. Claude is now catching what they missed. That is the rung-climbing made visible: not just producing work, but improving the work of experts.
Part five: running experiments — from helpful to superhuman
Now the harder half: research. The first research rung is executing a well-specified experiment, and here the authors describe a test they run at every model release. They hand Claude code that trains a small model and ask it to make that code run as fast as possible while still passing the same correctness checks — a miniature experimental loop of rewrite, run, time, repeat, with the goal and success metric fixed in advance.
The numbers are the most dramatic in the piece. In May 2025, Claude Opus 4 averaged a ~3× speedup over the starting code. By April 2026, Claude Mythos Preview was hitting ~52×. For calibration, a skilled human researcher needs four to eight hours to reach 4×. The authors are careful — the absolute multiple depends heavily on how much slack the starting code left, so it isn’t a real-world training speedup and shouldn’t be anchored on as one; what’s informative is the like-for-like comparison, both across models (~3× to ~52× in a year) and against a human (~4× in 4–8 hours on the identical task). With that caveat in place, the verdict stands: on optimizing steps within a clearly defined experiment, Claude went from super-helpful to superhuman in under a year.
Part six: proposing experiments — the first real climb toward taste
The rung above execution is proposing the experiment — designing the investigation, not just running it. This is where the piece offers its single most consequential result, and also where it is most careful about the caveats.
In April 2026, Anthropic published what it calls the first demonstration of Claude running an open-ended research project end to end. Claude-powered agents were handed a genuine open problem in AI safety — roughly, can a weaker model reliably supervise a stronger one? — and left to solve it: proposing hypotheses, testing them, sharing findings across parallel agents, iterating. The problem has a measurable floor (how the weak supervisor does alone) and ceiling (how the strong model does trained on correct answers). Two human researchers, over about a week, recovered roughly 23% of that gap. The agents recovered 97%, over 800 cumulative hours and about $18,000 in compute. Within the bounds of the task, the agents designed every experiment themselves; direction-setting was the only meaningful human role.
That last sentence is the headline, but the caveats are doing essential work and the authors don’t bury them: the result didn’t transfer cleanly to production-scale models, and humans still chose the problem and wrote the scoring rubric. So this is not yet a machine doing research from a blank page — it’s a machine doing extraordinarily well at research once a human has framed it and defined what winning means. That is exactly the boundary the whole piece is mapping. The agents are superb inside the frame; the frame is still human.
A second result probes the same rung from another angle. The authors looked at real Claude Code sessions from early 2026 where a researcher, working an open-ended problem, took a wrong turn that sent the session sideways before recovering. They showed various Claude models only the work from before the detour and asked what to do next; a separate Claude that could see how things actually turned out judged whether the model or the human had picked the better next step. Their best model in November 2025 (Opus 4.5) beat the human choice 51% of the time; by April 2026, Mythos Preview reached 64%.
This is where reading carefully matters most, because the authors are the ones insisting on the asterisk: these moments (n=129) were deliberately chosen because the human’s choice had room for improvement, so it is not a like-for-like comparison of model versus human judgment. As a sanity check, they ran the same test on a separate set of moments where the human’s move was already strong, and there the models’ suggestions were judged better only about 20% of the time. Read honestly, the result is not “AI out-judges humans.” It is “in the specific situations where a human stumbled, AI is increasingly likely to have offered the better recovery — and that likelihood is rising.” A narrow, early signal, presented as exactly that.
Part seven: the narrowing role, and the honest “what if we’re wrong?”
Step back and the through-line is clear: the human role narrows at each rung. Once AI- and human-authored code reach parity, humans stop writing code and shift to reviewing it — at which point, by Amdahl’s law, review becomes the bottleneck, because overall pace is capped by whatever hasn’t sped up. Once Claude can run any experiment, the question becomes which experiment is worth running. The doing now costs almost nothing in human time, even if it still costs compute. What’s left in human hands, for now, is research taste: choosing which problems matter, which results to trust, when an approach is dead.
The piece’s intellectual honesty peaks in a section titled, simply, What if we’re wrong? — and it steelmans the strongest objection against its own thesis. That objection: the work still in human hands, choosing what to work on, is the part that matters most, so without it Claude is a brilliant assistant but not an engine of AI progress. The authors’ answer is genuinely interesting. AI, they argue, is rarely advanced by eureka moments; the Transformer and mixture-of-experts were real paradigm shifts, but those arrive years apart. In between, progress is mostly perspiration — scale something up, see what breaks, fix it, repeat — and that is exactly the workflow Claude now excels at. Edison’s line was that genius is 1% inspiration and 99% perspiration; the claim here is that the perspiration is becoming automated, and that large-scale research progress is mostly a function of tools and resources, of how fast and how many experiments you can run. Even granting that Claude never develops good taste, they argue, a conservative reading still implies compounding acceleration, because humans spending their time only on the single-digit fraction that is direction-setting are each now steering vastly more work.
The three futures, held honestly
The piece refuses a single prediction and lays out three scenarios, which is the right move for a question this uncertain.
The first: the trend stalls, but today’s capabilities diffuse widely. The exponentials might be S-curves approaching their bend, where returns to scale diminish and the line flattens — perhaps taste really can’t be scaled into existence and needs a post-Transformer idea, or perhaps the binding constraint isn’t intelligence at all but the supply chain, the pace of chip fabrication and grid expansion and interconnect bandwidth. The authors include this for completeness but say they don’t find it likely — no curve they can measure has bent yet — while noting it would give the world the most time to adapt. Even here, they argue, the world changes: Project Glasswing, in its first weeks, had Mythos Preview find more than ten thousand high- and critical-severity vulnerabilities across critical systems, shifting the cyber-defense bottleneck from finding flaws to patching them fast enough, and a 100-person company increasingly does the work of a 1,000-person one because each employee sits atop a pyramid of agents.
The second, which they consider most likely: compounding efficiency gains, with development substantially automated but humans still setting direction and judging results. Hundred-person companies doing the work of tens of thousands — revolutionary for knowledge work and government, but also turnable to harm, from population-scale surveillance to individually tailored manipulation run at a scale no human team could match. And bound, again, by Amdahl’s law: speeding one part shifts the bottleneck elsewhere, which is precisely why human code review became Anthropic’s new chokepoint, and why the explosion of ideas and tools now outruns the company’s capacity to pursue them.
The third: full recursive self-improvement, AI systems designing and refining their own successors, with progress paced only by compute and algorithmic efficiency. Humans move mostly to oversight and verification of an expanding “virtual lab,” and the authors expect those same capabilities would transfer to the rest of science. This is the future they say they understand least — especially how the alignment problem gets solved or doesn’t. Models might prove aligned and wise enough to find solutions humans haven’t, even wise enough to halt development if needed; or the rare misalignments in today’s models could compound as systems build their successors, growing more frequent and less understood until control slips. They are candid that we may not be able to build and verify the tools needed to even know which trendline we’re on. And in a passage that is the piece’s most humane, they note that recursive intelligence still collides with a human world that sets its own pace: more intelligence can’t learn what a drug does over decades of use, can’t hold elections faster than a constitution allows, can’t turn a stranger into an old friend in a weekend. The lab upstream may run at the speed of compute; the felt pace of life downstream will still be set by its bottlenecks.
What they’re asking for
The piece ends not with a product but with a policy posture, and it’s worth taking seriously on its own terms. If development could be effectively slowed to buy time for safety and societal adjustment, the authors say, that would likely be good — but a slowdown that merely lets the least cautious actors catch up would leave everyone less safe. So what they argue for is the option: the systems that would let frontier developers verify that others have genuinely slowed or stopped, so that a credible, coordinated pause becomes possible rather than a unilateral act of self-sabotage. The Anthropic Institute commits to researching and building toward that verification capability, and says that if such systems existed and other frontier developers paused verifiably, Anthropic expects it would too.
They are clear-eyed about how hard that is. A real pause needs multiple well-resourced labs across multiple countries stopping under the same conditions, each able to verify the others — and AI makes even detection (a lower bar than verification) harder than for other technologies, because training runs are far easier to conceal than missile silos, the inputs are general-purpose, and the incentive to defect quietly is enormous, since whoever continues while others pause inherits the lead. The world has built verification regimes for complex technologies before — they cite the Intermediate-Range Nuclear Forces Treaty — but those took decades to build the infrastructure and the trust, and the authors say plainly: we don’t have that long.
Reading it straight
A few honest framings keep this in proportion. This is one lab’s account of its own internal data, much of it previously unreported and not independently audited — the authors are transparent about that, and about the soft spots (lines-of-code overstates; the self-reported 4× is probably high; the headline research result didn’t transfer to production scale; the next-step comparison used cherry-picked moments). Those caveats are in the original, stated by the people with the most incentive to omit them, which is itself a mark of the document’s seriousness. “More autonomous” is not “fully autonomous”; every standout result still had a human framing the problem and defining success.
With all of that in view, the core finding is hard to wave away and doesn’t depend on any single number: across every rung of AI development the authors can measure — writing code, running experiments, proposing them, and beginning to judge next steps — AI has been climbing the same curve, and that curve has not yet bent. The human role is narrowing toward a single redoubt, research taste, and the entire question of recursive self-improvement is whether that redoubt holds or is simply the next capability to fall. The authors don’t claim to know. What they claim, and substantiate, is that the question is no longer hypothetical, that it may arrive faster than our institutions are built to handle, and that the time to bring people outside the labs into the deliberation is now. On the evidence they present, that is not alarmism. It is a reasonable reading of a curve that keeps going up.
Based on “When AI builds itself” by Marina Favaro and Jack Clark (The Anthropic Institute), with the data, benchmarks, internal metrics, caveats, and scenarios drawn from that piece and its cited sources (METR, SWE-bench, CORE-Bench, and Anthropic’s own published research). This is independent commentary and analysis; all figures and quotations originate with the source.
© 2026 · Thorsten Meyer · Powered by Thorsten Meyer AI.