In June 2026, the US government switched off the most capable AI model on the market — twice, in different ways, inside three weeks.
Anthropic’s Fable 5 went dark worldwide in about 90 minutes on a Commerce directive. OpenAI’s GPT-5.6 shipped to only ~20 government-vetted partners and stayed there. If your product was standardized on either, you found out the hard way that model access is no longer something you control.
You can’t stop a government from gating a model. That decision is made in Washington, over disputes you’re not party to, on timelines you don’t set. But you can decide whether that decision takes you down. The difference between an outage and a shrug is entirely architectural — and it’s buildable. Here’s the playbook.
Kill-switch-proof: build so Washington can’t take your AI stack down
In June, the US government switched off the market’s most capable model — twice, in three weeks. You can’t stop the gate. You can decide whether it takes you down. The difference is entirely architectural — and buildable.
You can’t control the gate — Washington will keep deciding which frontier models ship, and both labs are pushing to make review permanent. What you control is your exposure to it. Kill-switch-proofing isn’t predicting the next directive — it’s making the next one a config change instead of an outage, a routing rule that fails over to a model no one can pull while your users notice nothing. The question stops being “will they take my model away?” and becomes the boring one you can answer: “which one do I route to next?”
The threat model, stated plainly
For a decade, “provider risk” meant an outage: the API is down for two hours, you retry, it comes back. That’s a solved problem. What June introduced is a different category: an indefinite, government-ordered removal of a specific model, with no SLA, no ETA, and no appeal you can file.
It gets more pointed for anyone outside the US. Export rules treat serving a model to a foreign national — even one sitting in your own office — as a “deemed export,” which is precisely why the June directive forced a global shutdown rather than a US-only one. If you run a mixed-nationality team, an EU entity, or offshore contractors, you can be structurally excluded even when the model is nominally “back.” This isn’t paranoia; it’s the plain reading of what already happened. And it rhymes with the other big story of the summer — the memory crunch — which points at the same conclusion from the hardware side: the more of your stack you actually own, the less anyone else’s decision can hurt you.
AI model redundancy server setup
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
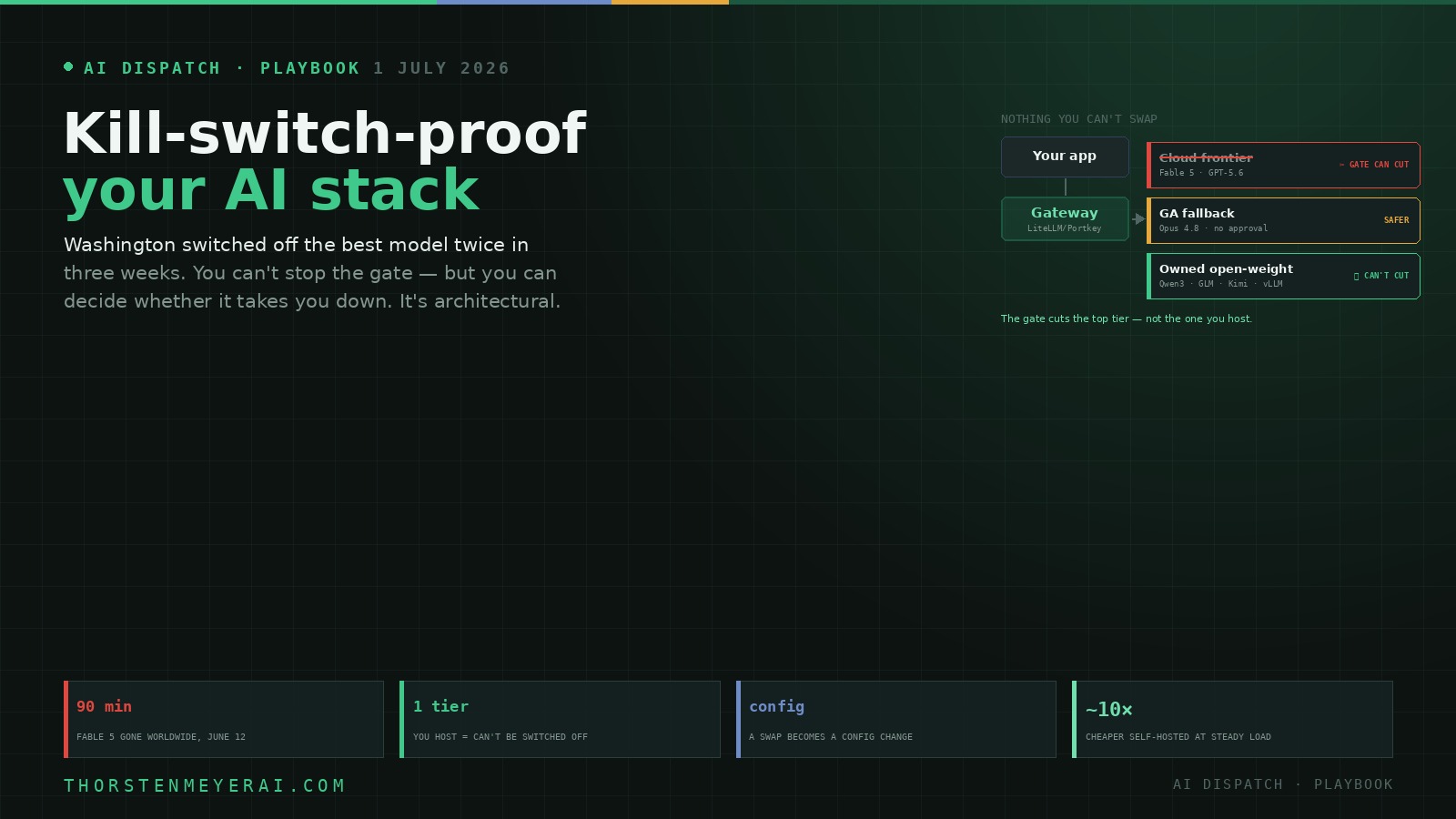
The principle: nothing you can’t swap
Everything below reduces to one rule. No model is allowed to be a code dependency; every model is a configuration value. If swapping your primary model requires an engineering sprint, you don’t have a stack — you have a hostage situation with a vendor and a government you didn’t choose. The goal is to make “which model am I using?” a line in a config file that anyone can change in minutes, under pressure, at 2 a.m.

AI Workstation for Beginners: A Practical Step-by-Step Guide to Choosing Hardware, Configuring Software, and Running Local Models Privately
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The playbook
1. Map every dependency before you need to
You cannot hot-swap what you never inventoried. The organizations that came through June intact shared one trait: a current, honest map of every model, provider, cloud, and integration they relied on, with each workload classified by how critical it is and how much downtime it can tolerate. Build that map first. It tells you where your single points of failure are — and it’s the document you’ll be grateful for the next time a directive lands on a Saturday.
2. Put a gateway in front of everything
The load-bearing move is a model-abstraction layer — an LLM gateway that exposes one OpenAI-compatible endpoint, so swapping the model behind it is a base-URL-and-model-string change, not a rewrite. A good gateway owns six things: provider abstraction, routing, retries and fallback, caching, observability, and rate limits.
The real options, honestly differentiated:
- LiteLLM — the most-adopted open-source choice (MIT, self-hosted proxy, 100+ providers, zero markup, keeps your prompt data inside your own infrastructure). The default for teams that want control.
- Portkey — open-sourced its gateway under Apache-2.0 in 2026; adds production guardrails (PII redaction, jailbreak detection) and compliance features. Best for regulated or customer-facing work.
- TrueFoundry — runs in your own VPC and unifies public providers and self-hosted vLLM/SGLang endpoints under one API. Best when governance and self-hosting matter equally.
- OpenRouter — managed, zero-ops, hundreds of models instantly — but it’s US-hosted, so it’s a poor fit for EU user data with residency obligations.
For almost every team, the right move is to use a gateway, not build one. Building your own is justified only by unusual latency or compliance needs.
3. Define fallback tiers — and actually test them
Behind the gateway, define an explicit chain: primary → secondary → last resort, routed by task type (coding, reasoning, long-context). The non-negotiable element the June episode revealed is a tier that requires no one’s approval to run — a generally available model (Claude Opus 4.8 was the real-world fallback when Fable vanished) or a self-hosted open-weight model that no export directive can touch. Then exercise it: a fallback you have never actually failed over to is not a fallback, it’s a hope. Run the drill on a normal Tuesday so it’s muscle memory on the bad day.
4. Keep an open-weight tier you truly control
This is the rung no government can switch off, and it’s the heart of kill-switch-proofing. Modern open-weight models have closed much of the gap: Qwen3-Coder-480B scores around 69.6% on SWE-bench Verified, Kimi K2 reaches roughly 71.6% on agentic coding, and GLM reports parity with strong closed models on several coding leaderboards. The honest caveat is that closed frontier models still lead on the hardest reasoning and broadest knowledge — so treat the open tier as your resilient floor, not necessarily your daily driver.
Two things matter more than the benchmark. First, license over label: favor genuinely permissive terms — Qwen3 and gpt-oss (Apache-2.0), DeepSeek and GLM (MIT), Kimi K2 (modified MIT) — and read custom licenses carefully for geography, user-cap, and commercial-use clauses (some, like certain Cohere releases, bar commercial use outright). Second, serve it on infrastructure you hold: vLLM or SGLang for production throughput, Ollama or llama.cpp for local and edge. This is exactly the local-inference posture the memory series argued for — and it carries a sovereignty bonus: self-hosting open weights in-region sidesteps the deemed-export trap that froze mixed-nationality teams, which is why it’s the natural answer for European and other non-US builders.
5. Decouple your prompts and evals from the model
The reason teams couldn’t swap quickly in June wasn’t only plumbing — it was that they had no fast way to trust a replacement. Keep prompt formatting abstracted rather than hand-tuned to one model’s quirks, and maintain a portable evaluation suite that scores any candidate on your real tasks. Done well, validating a swap-in becomes an afternoon, not a fortnight. The eval harness is the difference between “we could switch” and “we did switch, before lunch.”
6. Pin versions and own your data path
Never pull a silent “latest” — pin an explicit model version (a weights hash for self-hosted) in config, so nothing changes underneath you without a deliberate act. Keep your data path portable and explicit: residency, retention, RAG stores, and logs in-region and under your control (note that these “covered” frontier models now carry mandatory 30-day data retention, which may conflict with prior zero-retention agreements). And push it into procurement — an RFP that standardizes on a single frontier model now needs a written contingency tier that requires no government approval to invoke.
7. Let cost discipline pay for the insurance
Here’s the part that makes this an easy sell internally: the same architecture that survives a kill-switch also cuts your bill. Right-size, quantize (the memory-series lever), and self-host your steady, high-utilization workloads. At roughly 10 million output tokens a month, a frontier-priced API can run about $500 while the equivalent self-hosted inference lands nearer $50–150 in amortized GPU and power. Resilience and cost-efficiency turn out to be the same building.

AI ART ARCHITECTURE III
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The honest tradeoffs
None of this is free, and pretending otherwise would be its own failure mode. A gateway is another dependency — make it highly available, or you’ve just moved your single point of failure. Open-weight models still trail the closed frontier on the hardest tasks (the SWE-Bench Pro gap sits near 80% closed versus ~62% open), so a pure open-weight stack means accepting a capability ceiling on your most demanding work. Self-hosting is real operational burden and upfront capital, not a checkbox. And abstraction layers add a little latency, though the good ones cost only single-digit milliseconds.
The fair counter-argument: if you’re not running anything production-critical, can absorb occasional downtime, and genuinely need frontier-grade output on every call, the simplicity of just using the best available model may be worth the exposure. That’s a legitimate bet — but June repriced it. You now know the downside isn’t a two-hour outage; it’s an indefinite one you can’t appeal.

Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI Deployments
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The take
You cannot control the gate. Washington will keep deciding which frontier models ship, to whom, and when — and both leading labs are actively pushing to make that review process permanent, so the gate isn’t going away. What you can control is your exposure to it.
Kill-switch-proofing isn’t about predicting the next directive. It’s about making the next one a config change instead of an outage — a routing rule that fails over to a model no one can pull, while your users notice nothing. Build the abstraction layer, keep a tier you own outright, and the operative question stops being the frightening one — “will they take my model away?” — and becomes the boring one you can actually answer: “which one do I route to next?”
That shift, from watching your stack go dark to not even noticing, is the whole game. The frontier will keep getting gated. Your product doesn’t have to go down with it.
Sources: gateway and routing landscape from TrueFoundry, PkgPulse, TECHSY, Pinggy, and Klymentiev (LiteLLM, Portkey, OpenRouter, TrueFoundry comparisons, the six gateway concerns, EU data-residency caveats); open-weight model capability and licensing from Hugging Face, MorphLLM, and Z.ai/model cards (Qwen3, DeepSeek, GLM, Kimi K2, gpt-oss benchmarks and licenses); the June export-control events from CNBC, Axios, Semafor, and 9to5Mac; deemed-export and self-hosting economics from enterprise analyses of the Fable/Mythos suspension. Benchmark figures are point-in-time and vendor-reported unless noted. Analysis and recommendations are the author’s and not investment advice.