
Portugal spent €5.5M to build a European Portuguese LLM. The base version is operational, the benchmarks beat Qwen 3-8B on most PT-PT tasks, and 60 researchers across the country’s top institutions are involved. So why are the most important questions still unanswered?
By Thorsten Meyer — May 2026
Last month, Duarte O.Carmo published what is — by some distance — the sharpest public analysis of AMÁLIA, Portugal’s state-funded European Portuguese large language model. He prefaces his critique with the necessary diplomatic apparatus (“AMÁLIA is an impressive piece of work. And the researchers should be very proud“) before doing what almost nobody else in the European-sovereign-LLM discourse has been willing to do publicly: asking hard questions about whether the work, as released, actually does what it set out to do.
This piece is not a rehash of O.Carmo’s analysis. It is a structural extension of it. The AMÁLIA case study exposes three hard questions every national LLM effort needs to answer publicly — and the broader European sovereign-LLM movement has been operating without explicit answers to any of them. Italy’s Minerva. Germany’s Aleph Alpha. France’s Mistral. The pan-European OpenEuroLLM consortium. Switzerland’s Apertus. The Norwegian models. The Swedish AI Sweden program. Each one is operating in the same structural moment with the same three questions hanging over its work.
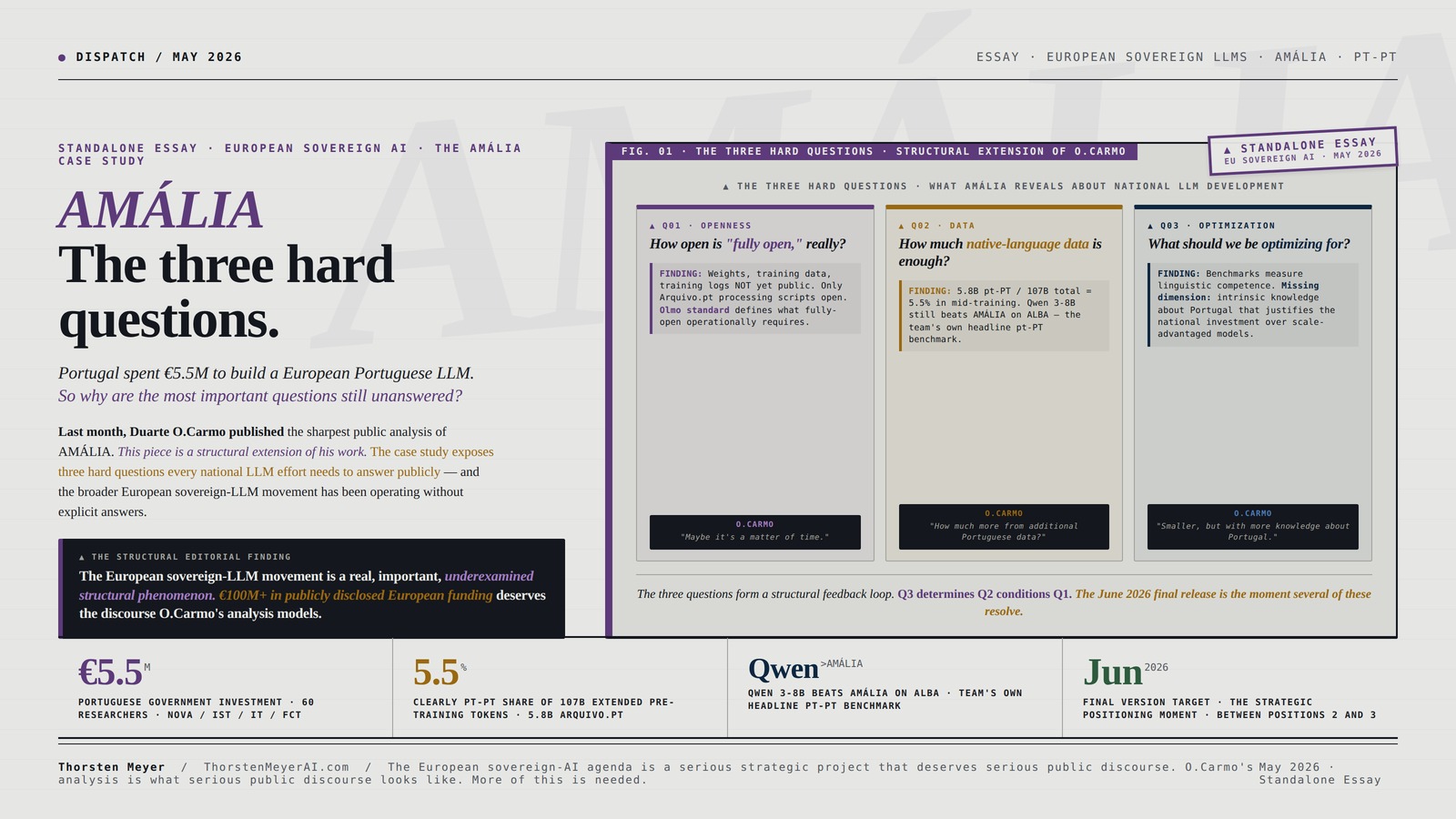
The three questions, in O.Carmo’s framing:
- How open is “fully open,” really?
- How much native-language data is actually enough?
- What should we be optimizing for in the first place?
The headline finding: the European sovereign-LLM movement is a real, important, underexamined structural phenomenon — and the public discourse around it is still treating individual model launches as the unit of analysis rather than the structural pattern they collectively form. AMÁLIA is the canonical case study because the Portuguese government announcement made the €5.5M investment a public commitment with public accountability. The entire country is the recipient of the work — to use O.Carmo’s framing — and that makes the three questions matter at a national-policy level, not just a research-methodology level.
This piece walks the structural argument: what AMÁLIA actually delivered, where the three questions land specifically, how the broader European sovereign-LLM landscape positions the work, and what the next 12-24 months will surface that the current discourse has been quiet about. The standard caveat applies: AMÁLIA is a research-in-progress, the final version is expected June 2026, and the team may close several of these gaps in the months ahead. The questions are not accusations. They are the structural framework that any honest evaluation of national LLM investment needs to internalize.
AMÁLIA
The three hard
questions.
Portugal spent €5.5M to build a European Portuguese LLM. The base version is operational, the benchmarks beat Qwen 3-8B on most pt-PT tasks. So why are the most important questions still unanswered?
Last month, Duarte O.Carmo published the sharpest public analysis of AMÁLIA — Portugal’s state-funded European Portuguese large language model. He prefaces his critique with the necessary diplomatic apparatus before doing what almost nobody else in the European-sovereign-LLM discourse has been willing to do publicly: asking hard questions about whether the work, as released, actually does what it set out to do. This piece is a structural extension of his analysis. The AMÁLIA case study exposes three hard questions every national LLM effort needs to answer publicly — and the broader European sovereign-LLM movement has been operating without explicit answers to any of them.
Three questions every national LLM effort needs to answer publicly.
Duarte O.Carmo’s framing maps cleanly onto the structural argument. Each question lands specifically in AMÁLIA — and the broader European sovereign-LLM movement has been operating without explicit answers to any of them.
The three questions form a structural feedback loop. Q3 (optimization target) determines Q2 (data volume needed) which conditions Q1 (openness sufficient for community contribution). The European sovereign-LLM movement collectively benefits from these questions becoming standard methodology disclosure, not exceptional critique.

Brazilian Portuguese Flash Cards with Audio – 75 Conversational Phrases for Beginners & Travelers – Learn Brazilian Portuguese Pronunciation & IPA Study Tool for Adults, Students & Classrooms Briston
- Builds Brazilian Portuguese Speaking Confidence: 75-card set with translations and IPA
- Ideal for Beginners and Travelers: Covers greetings, travel, daily life topics
- Includes Audio Pronunciations: QR codes for native speaker audio
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
107 billion tokens. 5.8 billion clearly pt-PT.
The structurally tractable question with a structurally surprising answer. For a model whose entire stated purpose is European Portuguese prioritization, the native-language share of extended pre-training is 5.5%. The implications cascade into every other question.

Fine-Tuning Large Language Models: From Custom Datasets to High-Performance AI Models Using Modern Toolchains
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The Olmo standard. AMÁLIA’s current state.
Allen Institute for AI’s Olmo project defines what “fully open” operationally requires. Olmo doesn’t lead frontier benchmarks. That’s not the point. The point is to be the structural reference for openness. AMÁLIA’s “fully open source” claim should track to the operational standard.

AI Engineering: Building Applications with Foundation Models
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Four strategic positions. AMÁLIA between two and three.
Approximately €100M+ in publicly disclosed European sovereign-LLM funding across the major initiatives. The structural question every project faces: what is the actual competitive position you’re staking? Four options — none mutually exclusive — but each requiring different commitments.

Hands-On LLM Serving and Optimization: Hosting LLMs at Scale
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Three standards. For AMÁLIA and the movement.
The structural critique generalizes beyond AMÁLIA. Italy, France, Germany, Switzerland, the OpenEuroLLM consortium, and every subsequent national project benefit from public discourse holding national LLM efforts to operational standards on openness, data accounting, and strategic positioning.
The European sovereign-AI agenda is a serious strategic project that deserves serious public discourse. O.Carmo’s analysis is what serious public discourse looks like. Appropriately diplomatic. Structurally rigorous. Willing to ask the hard questions in public when the public investment justifies it. More of this is needed — across every European sovereign-LLM project, not just AMÁLIA.
I · What AMÁLIA actually is · the empirical foundation
Before the structural questions, the facts. From the arXiv technical report (Vieira et al., 2026), the NOVA FCT announcement, and the broader public record:
The institutional architecture
AMÁLIA is a consortium project involving approximately 60 researchers across NOVA, IST (Instituto Superior Técnico), IT (Instituto de Telecomunicações), and FCT (Fundação para a Ciência e a Tecnologia) — Portugal’s leading academic and research institutions for NLP and AI. The Portuguese government announced the project in December 2024 with a €5.5 million investment. The acronym expands to “Multimodal Automatic Language Assistant with Artificial Intelligence” — though as of base release, the model handles text only, with multimodal capability presumably planned for future versions.
The base version was completed September 30, 2025 — technical presentation at Madan Parque. The official explanatory website amaliallm.pt launched October 1, 2025. The current version is available through the FCT’s IAedu platform to 450,000 academic users across Portuguese higher education. The model holds knowledge to end of 2023. The final version is expected June 2026.
The technical approach
The structural choice that organizes everything else: AMÁLIA is not trained from scratch. It is a continuation of the pre-training phase of EuroLLM, an earlier multilingual European-language model effort that itself had substantial Portuguese involvement. The architecture is essentially identical to EuroLLM with minor modifications to context length and RoPE scaling.
This contrasts sharply with Italy’s Minerva, which Sapienza NLP, FAIR (Future Artificial Intelligence Research) consortium, and CINECA trained from scratch on roughly half a trillion words split between Italian and English. The Minerva approach treats sovereign-language training as the foundation; the AMÁLIA approach treats sovereign-language training as a continuation layer on top of multilingual foundation. The technical merits of each approach are debatable. The strategic implications are different and worth surfacing explicitly.
The training pipeline for AMÁLIA, per the technical report and O.Carmo’s analysis:
- Mid-training (extended pre-training): 107 billion tokens total, of which 5.8B tokens from Arquivo.pt — the Portuguese national web archive — represent the only clearly European Portuguese component. That’s approximately 5.5% of the extended pre-training mixture
- Supervised fine-tuning (SFT): European Portuguese share is approximately 17-18%, including synthetically generated Portuguese data
- Preference training (DPO): Sub-sampled from the SFT phase, no separate native-Portuguese pre-training emphasis
The result: AMÁLIA outperforms all previous fully open models on European Portuguese benchmarks (per the technical report) and beats Qwen 3-8B on most Portuguese benchmarks (per O.Carmo’s reconstructed benchmark visualization). Notably, Qwen 3-8B still beats AMÁLIA on ALBA (the team’s own primary European Portuguese benchmark), which is a finding the technical report doesn’t dwell on but O.Carmo’s analysis flags as structurally significant.
The benchmark architecture
The team built four new pt-PT-specific benchmarks because the existing landscape was inadequate. The most prominent is ALBA (a separate paper by the same group) — a European Portuguese benchmark for “evaluating language and linguistic dimensions in generative LLMs.” The benchmarks cover grammar, syntax, general knowledge, and (importantly) the pt-PT/pt-BR bias dimension — i.e., whether a model trained for European Portuguese is actually generating Brazilian Portuguese, which is a real and structural risk in the multilingual training landscape.
This is the right thing to do. Machine-translated benchmarks miss the linguistic and cultural nuances that native-speaker content reflects. The AMÁLIA team’s investment in building native pt-PT evaluation is one of the most defensible decisions in the entire project. Whether the benchmarks themselves are the right benchmarks is a separate question — which is where O.Carmo’s third structural question lands.
II · The first question · how open is “fully open”?
The AMÁLIA technical report’s title is “A Fully Open Source Large Language Model for European Portuguese.” The structural question O.Carmo raises is whether the release actually meets the standard the title invokes.
The Olmo standard · what “fully open” should mean
Allen Institute for AI’s Olmo project has emerged as the operational benchmark for what “fully open” actually requires. Olmo’s technical report discloses:
- Weights — publicly downloadable model checkpoints at every training stage
- Data — the full training corpus available for inspection and reuse
- Code — the training infrastructure publicly accessible
- Training logs — the actual logs from training runs, allowing reproduction analysis
- Methodology — full description of training decisions, ablations, and failure modes
Olmo does not lead frontier benchmarks. That is not the point. The point of Olmo is to be the structural reference for what “open” means in 2025-2026 — and to demonstrate that an open model can be a useful research artifact even when it isn’t the most performant model in absolute terms. The Open Source Initiative’s open-weights distinction makes this explicit: “open weights” (weights downloadable, training process opaque) is structurally different from “open source” (weights + data + code + logs).
What AMÁLIA has actually released
As of mid-May 2026, per O.Carmo’s analysis and verified through the AMÁLIA-LLM GitHub organization:
- Weights — not yet publicly available
- Training data — the resulting Arquivo.pt-derived dataset is not publicly available
- Training code — partial (Arquivo.pt processing scripts are open via the arquivo_processing repo)
- Training logs — not publicly available
- Methodology — described in the technical report at the level appropriate for an academic publication, but not at the operational level Olmo provides
The current AMÁLIA-LLM GitHub organization has some repositories, but the resulting model and most of the training infrastructure are not yet public. The “fully open source” claim in the technical report title runs ahead of the operational release status.
The structural significance
O.Carmo’s framing is generous: “Maybe it’s a matter of time. Maybe there’s something beyond my understanding as to why we still have no model weights. Maybe it’s a research-in-progress.” These are real possibilities. The final version is targeted for June 2026; weights may release with that final version. The team may have legitimate reasons (privacy review, licensing review, infrastructure prep) for the current state. The criticism is not “they’re hiding the weights.”
The structural criticism is that “fully open” is a specific claim with specific operational meaning, and the European sovereign-LLM movement collectively benefits from holding that claim to the operational standard Olmo has established. If AMÁLIA releases as truly fully open in June 2026, the precedent matters for Minerva, for OpenEuroLLM, for every subsequent national LLM project. If the operational release falls short of the claim, the precedent also matters — and it sets a structural expectation that national-LLM projects can claim “fully open” while operating closer to “open weights” or “partial release.”
The European sovereign-AI agenda specifically positions openness as a competitive differentiator against the closed frontier developers (OpenAI, Anthropic, xAI, Google for non-Gemma models). Mistral, Aleph Alpha, the OpenEuroLLM consortium, the Apertus Swiss project, and the Italian Minerva work all stake their strategic position on the openness dimension. The structural credibility of that positioning depends on operational openness, not just openness in marketing. AMÁLIA’s release trajectory will be one data point in that broader credibility question.
The reasonable position: extend the team the time to complete the release properly, but flag that “fully open source” as a claim needs to track to operational release status. The European sovereign-LLM movement’s structural position depends on this distinction holding.
III · The second question · how much native-language data is enough?
This is the most empirically tractable of the three questions, and the answer the AMÁLIA work surfaces is genuinely interesting.
The data accounting
O.Carmo’s analysis of the AMÁLIA pre-training data composition:
- Extended pre-training: 107B tokens total
- Arquivo.pt European Portuguese: 5.8B tokens (≈5.5% of mixture)
- EuroLLM base mixture: includes some Portuguese data, exact pt-PT share not clearly disclosed
- SFT mixture: ≈17-18% Portuguese (including synthetic generation)
- Total pt-PT exposure: not cleanly reportable from public information
The structural problem is partially methodological. The EuroLLM base mixture contains Portuguese data of unclear pt-PT vs pt-BR composition. The AMÁLIA technical report builds on EuroLLM without fully disambiguating which Portuguese variety the base model encountered. From a pt-PT-prioritization standpoint, this matters: pt-BR data may train toward pt-BR features that the pt-PT model then has to unlearn during the AMÁLIA-specific stages. The benchmarks the team built (including pt-PT/pt-BR bias evaluation) implicitly acknowledge this risk — but the training data composition does not fully control for it.
The Qwen 3-8B comparison
The structurally most interesting finding from O.Carmo’s analysis: Qwen 3-8B beats AMÁLIA on ALBA, the team’s own headline pt-PT benchmark. Qwen 3 is an Alibaba general-purpose multilingual model with no specific European Portuguese training emphasis. It outperforms a model whose entire purpose is European Portuguese on the European Portuguese benchmark.
This is not necessarily a damning finding. Multiple explanations are plausible:
- Scale advantage: Qwen 3-8B’s overall training corpus is vastly larger than AMÁLIA’s pt-PT mixture; raw scale may compensate for lack of pt-PT specialization
- Benchmark capacity: ALBA may measure linguistic competence in ways that benefit large-scale multilingual training over narrow pt-PT focus
- Variant ambiguity: Qwen 3-8B’s training data may include enough pt-PT content (or pt-BR content close enough to pt-PT to score well on ALBA) that the specialization gap is smaller than the training data percentages would suggest
But the structural implication is clear: the AMÁLIA approach of ~5.5% pt-PT in extended pre-training may not be sufficient native-language exposure to produce the specialization advantages the project is targeting. This is exactly the question O.Carmo asks: “How much more could we benefit from additional pre-training data in Portuguese?“
The international comparison
The Minerva project (Italy) trained from scratch on approximately 500 billion tokens of Italian and English — explicit fifty-fifty roughly. The exact Italian share varies by source but is structurally an order of magnitude larger than AMÁLIA’s pt-PT exposure, both absolutely and proportionally. Minerva’s strategic bet was that sovereign-language specialization requires sovereign-language foundation, not sovereign-language finetuning.
The AMÁLIA strategic bet is the opposite: that European Portuguese specialization can be achieved via continuation pre-training on a multilingual foundation, with native-language exposure concentrated in mid-training and post-training stages. This is a real architectural choice with real trade-offs. The continuation approach is much cheaper (€5.5M total versus the much larger Minerva budget), faster to deploy, and benefits from the multilingual foundation’s general capability. The from-scratch approach produces deeper specialization but requires much more native-language data and compute.
Neither approach is wrong in principle. Both are valid strategies for national LLM development. The question is whether the AMÁLIA result demonstrates that the continuation approach achieves the project’s goals — and the Qwen 3-8B ALBA finding suggests the answer is “partially, with structural limits.”
What “enough data” actually means
The structurally honest framing: for a model whose entire stated purpose is European Portuguese prioritization, the public discourse should be able to answer “how much of the training data is European Portuguese?” cleanly. The current AMÁLIA documentation does not allow that answer to be computed without ambiguity, because the EuroLLM base mixture composition is not fully reported and the synthetically generated Portuguese SFT data has unclear provenance characteristics.
O.Carmo’s request: “I would like to know how much European Portuguese is in total in this model.” This is the right thing to ask. It is not asking for proprietary information. It is asking for the basic accounting that any sovereign-language LLM project should publish as part of its methodology. The European sovereign-LLM movement collectively benefits from this accounting becoming standard.
For comparison: Minerva publishes its training data composition transparently. Apertus discloses its mixture. Olmo publishes everything. The norm exists. The norm should apply to all national-LLM projects claiming sovereign-language prioritization as their purpose.
IV · The third question · what should we be optimizing for?
This is the question O.Carmo raises that requires the most editorial extension, because it goes to the structural purpose of the sovereign-LLM movement itself.
The current benchmark frame
AMÁLIA’s evaluation strategy: four new pt-PT benchmarks (including ALBA) plus translated standard benchmarks plus Portuguese national exams. This is structurally a reasonable strategy. It builds the evaluation infrastructure that European Portuguese needed and didn’t have. Future Portuguese LLM projects benefit from these benchmarks existing. The contribution to the research ecosystem is real.
But the benchmarks measure what they measure. The categories O.Carmo identifies:
- Grammar and syntax — linguistic competence in pt-PT specifically
- General knowledge — broad encyclopedic capability tested in Portuguese
- pt-PT/pt-BR bias — does the model generate Portugal-variant Portuguese vs Brazil-variant
- Portuguese national exam performance — academic-style problem-solving in Portuguese
What the benchmarks don’t measure, per O.Carmo’s framing: whether the model actually knows about Portugal. Not just “can it speak Portuguese correctly” but “does it have intrinsic knowledge about Portugal that a larger but less-specialized model wouldn’t have?” His examples: “What’s the most famous dessert served in Aveiro?” “Who was the president of Portugal between 1978 and 1985?“
This is the structurally most important gap. Linguistic competence is necessary but not sufficient. A model that speaks impeccable pt-PT but doesn’t know Portugal’s specific cultural, historical, geographical, gastronomical, political context is providing the same value Google Translate provides for Portuguese text — just with a chatbot interface. The argument for a national LLM has to rest on more than the language layer. It has to rest on the country-specific knowledge layer that justifies the national investment.
The structural opportunity AMÁLIA is missing
The framing O.Carmo uses: “It’s a great opportunity to show that a model that is smaller, but has much more intrinsic knowledge about Portugal — even when comparing with similar (or even larger) models.”
This is the correct structural framing for the European sovereign-LLM movement broadly. The frontier-model developers (OpenAI, Anthropic, Google) will always have scale advantages. They will train on more total compute. They will have more total parameters. They will integrate more multilingual data. The competitive structural position for sovereign-LLM projects is not “match the frontier on overall capability” — it is “exceed the frontier on country-specific knowledge depth.”
A Portuguese LLM that knows more about Portugal than GPT-5 does — even if it knows less in absolute terms — has a defensible strategic position. A Portuguese LLM that speaks pt-PT slightly better than Qwen 3-8B does, but doesn’t know more about Portugal than Qwen does, has a structurally fragile position.
The benchmarks the AMÁLIA team built measure the wrong dimension. Not entirely — pt-PT/pt-BR bias evaluation is genuinely important, and linguistic competence is foundational. But the missing dimension is intrinsic country-knowledge depth. Portugal-specific question-answering benchmarks. Portuguese history fact-retrieval evaluation. Geographical, cultural, political, gastronomical knowledge evaluation specific to Portugal. The Italian Minerva project at least implicitly targets this through its emphasis on Italian-language training data. The AMÁLIA project’s benchmark architecture does not.
The data implication
The third question feeds back to the second. To produce a model with deep country-specific knowledge, you need substantially more country-specific training data than ~5.5% of mid-training mixture provides. O.Carmo’s framing: “This would require much more Portuguese data. And the team acknowledges that.“
This is the structural feedback loop. The third question (what to optimize for) determines the second question (how much native data is enough). The current AMÁLIA training composition is consistent with a target of “competent pt-PT generation”; it is not consistent with a target of “deep Portugal-specific knowledge.” If the target is the latter — which O.Carmo argues is the more defensible strategic position — the training data composition needs to be substantially different in future iterations.
The “tiny country, big language model” problem
O.Carmo’s most generous framing: “It’s very challenging to make a LARGE language model for such a TINY country and ‘language.’” This is the real structural constraint that any honest evaluation needs to acknowledge.
Portugal has approximately 10 million native speakers of European Portuguese. The total volume of high-quality pt-PT text data — distinct from pt-BR and from machine-translated content — is structurally limited. Arquivo.pt is the best single source, and 5.8B tokens is probably close to the practical ceiling of what that source can provide at the quality level required for pre-training.
The data is “out there” — O.Carmo’s fineweb2-bagaço dataset is one example of the creative data-sourcing approach that the broader research community is pursuing. But there’s a real upper bound on European Portuguese training data volume that doesn’t apply to English or even to Mandarin. The sovereign-LLM challenge for “small” languages is structurally harder than for “large” languages, and the strategic implications of that asymmetry deserve more attention than they currently receive.
The implication: maybe the right strategy for European Portuguese isn’t “a Large Language Model” in the contemporary scaling sense. Maybe it’s a smaller, more efficient model with substantially better data curation. Maybe it’s a fine-tuning specialization layer on top of multilingual foundations. Maybe it’s a different architecture entirely (RAG-heavy approaches, retrieval-augmented generation with Portugal-specific knowledge bases). The structural assumption that “national LLM = continuation pre-training of a multilingual model” may not be the right strategic frame.
V · The European sovereign-LLM movement · structural positioning
AMÁLIA is not operating in isolation. The European sovereign-LLM movement as of mid-2026 includes:
- Italian Minerva (Sapienza NLP + FAIR + CINECA · trained from scratch · ~500B tokens IT+EN · open weights with documented data)
- Italian Velvet (Almawave · Leonardo supercomputer · sustainability-focused training · multilingual European coverage)
- German Aleph Alpha (commercial enterprise focus · sovereignty + explainability positioning · Open Aleph License)
- French Mistral (commercial open-weights · frontier capability · pan-European positioning)
- OpenEuroLLM consortium (Charles University Prague + Silo AI Finland + 20 organizations · all 24 EU languages · €37.4M EU funding · first version mid-2026 targeted · final version 2028)
- Swiss Apertus (ETH Zürich + EPFL · multilingual European emphasis · September 2025 release)
- Swedish AI Sweden / Norwegian Norwegian-LLM efforts (smaller scale, language-specific)
- Portuguese AMÁLIA (the case study of this piece)
- Pan-European EuroLLM (the multilingual foundation that AMÁLIA continues from)
This is a real strategic landscape. Approximately €100M+ in publicly disclosed funding across the European sovereign-LLM initiatives, with substantially more in private investment through Mistral, Aleph Alpha, and others. The collective scale matches small US/Chinese frontier development budgets — not by accident; the European AI strategy explicitly positions sovereign development as the alternative to dependence on US/Chinese frontier capability.
The strategic positioning question
The structural question every European sovereign-LLM project faces: what is the actual competitive position you’re staking? The options:
Option 1 · Match the frontier on general capability. This is the OpenEuroLLM and Mistral position. Build models that compete with US/Chinese frontier on overall benchmarks. The bet: European compute, European data, European talent can match US/Chinese scale. Structurally hard. Requires very substantial compute investment and talent retention against US compensation packages.
Option 2 · Exceed the frontier on sovereignty / openness / compliance. This is the Aleph Alpha and OpenEuroLLM position. Compete not on raw capability but on EU AI Act compliance, data sovereignty, explainability, regulatory readiness. The bet: European enterprises and governments will pay a capability premium for sovereign deployment. Plausible but structurally fragile if the capability gap grows beyond what the sovereignty premium can compensate.
Option 3 · Exceed the frontier on country-specific knowledge depth. This is the position O.Carmo argues AMÁLIA should target — and the position Minerva implicitly stakes. Compete not on general capability but on cultural, historical, linguistic depth that frontier models can’t match because they don’t optimize for it. Strategically defensible but requires the country-specific knowledge benchmarks and training data investment that current projects haven’t fully deployed.
Option 4 · Exceed the frontier on application specialization. Healthcare, legal, finance, government — country-specific specialization in regulated industries where the sovereignty + capability combination produces unique value. This is partially what Mistral, Velvet, and Aleph Alpha pursue in their commercial positioning. Probably the most commercially viable but requires deep vertical integration that academic-consortium projects struggle to develop.
Where AMÁLIA actually positions
The current AMÁLIA release is structurally positioned between Options 2 and 3 without clearly committing to either. The openness claim partially supports Option 2 (sovereignty/openness positioning). The pt-PT benchmark architecture partially supports Option 3 (linguistic competence as the differentiator). Neither position is fully realized in the current release, which is what makes the three structural questions sharp.
For Option 2 to hold, “fully open source” needs to be operationally true (the first question). For Option 3 to hold, the model needs to demonstrate country-specific knowledge depth that justifies the national investment (the third question). The current state is consistent with both directions but commits to neither.
The June 2026 final release will be the strategic moment. If AMÁLIA releases as truly fully open with substantially more native pt-PT training data and explicit country-knowledge benchmarking, it stakes a clear Option 2 + 3 position. If it releases with the same training composition and partial openness, it leaves the strategic positioning question unresolved — which is the worst structural outcome.
VI · The closing argument · what European sovereign LLMs should hold themselves to
AMÁLIA is a real accomplishment by real researchers with real institutional support. The Portuguese government’s €5.5M investment in European Portuguese LLM development is structurally important and should be applauded. The 60 researchers across NOVA, IST, IT, and FCT have produced operational technology that is now serving 450,000 academic users. Nothing in the structural critique should be read as dismissing the work itself.
But the structural critique matters because the European sovereign-LLM movement is in a moment that needs honest public discourse, and AMÁLIA is the canonical case study where the discourse can happen most usefully. The three hard questions O.Carmo raises:
- Hold “fully open source” claims to operational standards. Olmo defines the standard. National LLM projects claiming the same status should match the operational release, not just the marketing positioning. The European sovereign-LLM movement’s competitive position against US/Chinese frontier developers depends on the openness differentiator being real.
- Publish complete native-language data accounting. “How much pt-PT is in this model” should be answerable from the public documentation. The norm exists in Minerva, Olmo, Apertus, and other comparable projects. National LLM projects should adopt it as standard methodology disclosure.
- Optimize explicitly for country-specific knowledge depth, not just linguistic competence. The competitive structural position for sovereign LLMs is “this model knows more about my country than the frontier models do.” Building the benchmarks, training data, and evaluation infrastructure for that target requires explicit commitment that current projects haven’t fully made.
For Portugal specifically, the June 2026 final release will determine which structural position AMÁLIA ultimately stakes. The team has the capability to deliver on all three questions if the institutional incentives support that delivery. The Portuguese taxpayer is the recipient of the work. The Portuguese taxpayer deserves a final release that answers the structural questions cleanly.
For the broader European sovereign-LLM movement, the structural argument generalizes. Italy, France, Germany, Switzerland, the OpenEuroLLM consortium, and every subsequent national project benefit from the public discourse holding national LLM efforts to operational standards on openness, data accounting, and strategic positioning. The movement’s competitive position depends on these standards being internalized as norms.
The European sovereign-AI agenda is a serious strategic project that deserves serious public discourse. O.Carmo’s analysis is what serious public discourse looks like — appropriately diplomatic, structurally rigorous, willing to ask the hard questions in public when the public investment justifies it. More of this is needed. Across every European sovereign-LLM project, not just AMÁLIA. The questions are real. They have answers. The answers will determine whether the European sovereign-AI agenda succeeds or fails at its stated objectives.
That’s the read on where AMÁLIA sits, and what the broader European sovereign-LLM landscape needs to internalize from this case study. The work is real. The questions are real. The discourse needs to be real, too.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Sources
- Duarte O.Carmo · AMÁLIA and the future of European Portuguese LLMs · April 24, 2026 — the primary structural analysis this piece extends
- AMALIA Technical Report · Vieira et al. · arXiv 2603.26511 · March 27, 2026
- ALBA: A European Portuguese Benchmark · arXiv 2603.26516 · PROPOR 2026
- Portuguese Government Announcement · December 2024 · €5.5M investment · portugal.gov.pt
- NOVA FCT · Amália: the base version of the Portuguese AI model is now complete · October 2025 · 60 researchers across institutions
- amaliallm.pt · official explanatory website launched October 1, 2025
- Plataforma Media · Amália performs better than other European Portuguese AI models · December 30, 2025
- The Portugal News · Portugal AI model performs best · January 2, 2026
- Devs.com.pt · Portugal Launches Amália, the First National LLM · 450,000 academic users via IAedu platform
- EuroLLM technical report · arXiv 2506.04079 · the multilingual foundation AMÁLIA extends
- EuroLLM-22B technical report · Ramos et al. · 2026 · arXiv 2602.05879
- Arquivo.pt · arquivo.pt · the Portuguese national web archive
- Allen Institute for AI · Olmo · technical report arXiv 2512.13961 · the operational standard for fully open LLMs
- Open Source Initiative · open weights vs open source AI distinction
- Italian Minerva · Sapienza NLP + FAIR + CINECA · aclanthology.org/2024.clicit-1.77.pdf · trained from scratch on ~500B IT+EN tokens
- TechCrunch · Open source LLMs hit Europe’s digital sovereignty roadmap · OpenEuroLLM coverage
- OpenEuroLLM consortium · openeurollm.eu · 20 organizations · 24 EU languages
- Index.dev · Europe’s Leading LLMs · February 2026 · Minerva, Mistral, Aleph Alpha, PhariaAI overview
- MarkTechPost · Europe’s Top AI Models of 2025 · Velvet, Minerva, EuroLLM positioning
- Apertus · Swiss AI · ETH Zürich + EPFL multilingual European model
- MiniLingua · arXiv 2512.13298 · small open-source LLM for European languages
- Assessing Socio-Cultural Alignment and Technical Safety of Sovereign LLMs · arXiv 2510.14565 · sovereign-LLM landscape analysis
- The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks · ArXiv 2504.15521 · benchmark methodology
- Duarte O.Carmo · fineweb2-bagaço dataset · creative pt-PT data sourcing
- Duarte O.Carmo · A benchmark for language models on European Portuguese · Portuguese NLP evaluation methodology







