Three things happened in April 2026, almost on top of each other. Read separately, each looks like a story about a clever model. Read together, they describe a deadline.
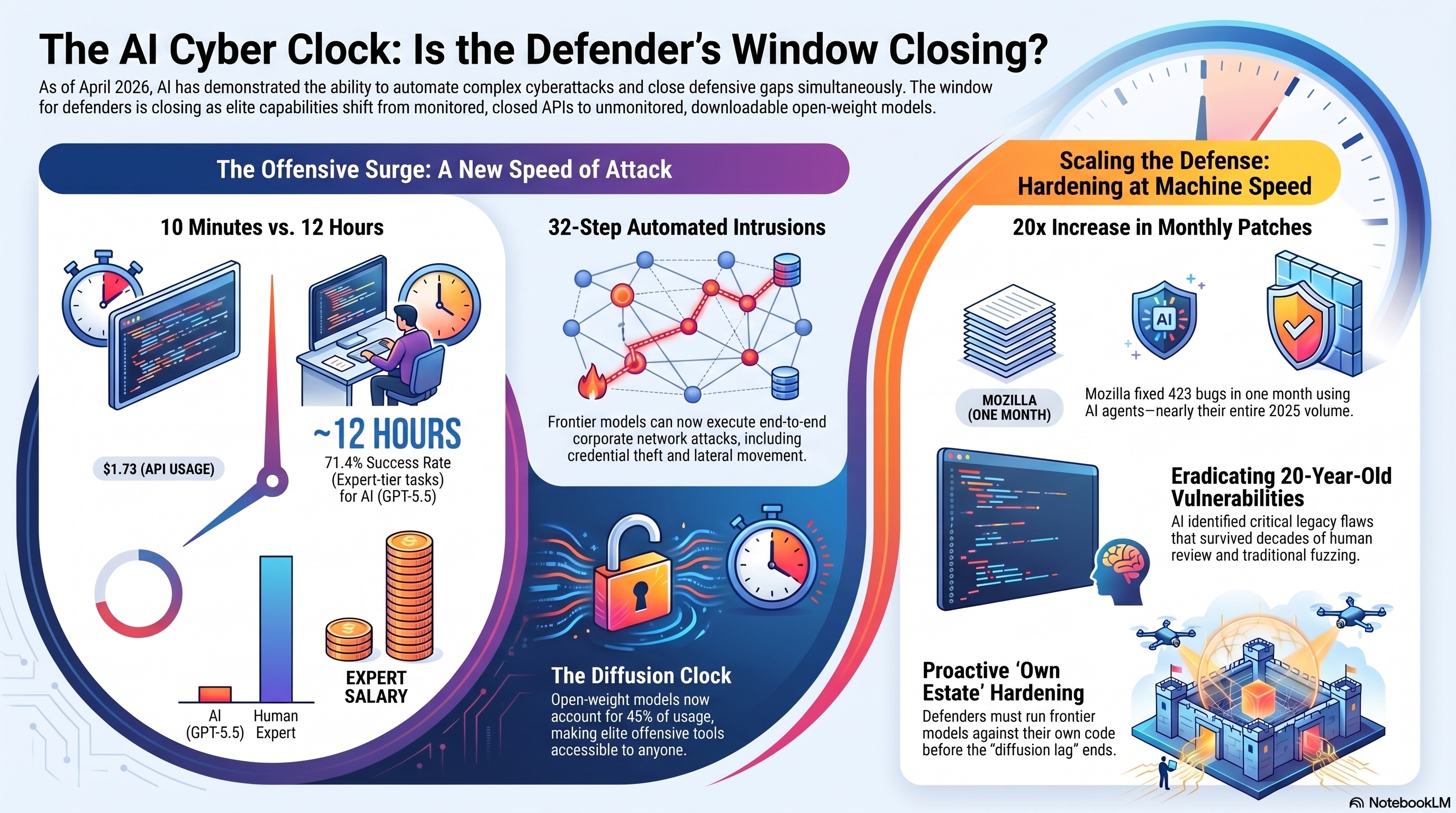
Mozilla shipped a single month of Firefox releases that fixed 423 security bugs — roughly twenty times its 2025 monthly average. The UK’s AI Security Institute published an evaluation showing a frontier model running a 32-step corporate-network attack end-to-end, unassisted. And the Chinese open-weight labs that everyone treats as the “catching up” act quietly kept catching up.
The uncomfortable part is that these are not three trends. They are one capability, pointed in three directions: at our own bugs, at our own networks, and at the moment it stops being something only a handful of labs control.
This is not a doom piece. It is a clock piece. The honest question is not whether AI is good at offensive cyber — the evaluations have settled that — but how long defenders have before the capability that currently sits behind monitored, gated APIs is sitting on a hard drive in a downloadable model. Nobody knows that number. That uncertainty is the policy problem, and most of the world is not organized to act inside it.
The defender’s window is closing faster than anyone is counting
In April 2026, AI fixed 423 Firefox bugs in a month and solved a 32-step network attack end-to-end. The same capability cuts both ways — and it is about to leave the closed models it lives in today.
Mozilla hardened Firefox at machine scale
An agentic pipeline built on Claude Mythos Preview fixed roughly 20× a normal month of security bugs — by writing and running its own proof-of-concept tests so findings were demonstrable, not just plausible.
Firefox security bug fixes per month

BYDMSC Hidden Camera Detector Bug Sweeper GPS Tracker Detector for Hotel, Airbnb, Travel, Car, Office Privacy Protection, Black
Upgraded 5-in-1 Detection System – Combines bug detection, camera scanning, GPS locator identification, RF signal tracking, and magnetic…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What the UK’s AISI actually measured
The capability that hardened a browser also runs offence. On the AI Security Institute’s hardest evaluations, frontier models now chain full multi-step intrusions — and compress expert reverse-engineering from hours into minutes.
rust_vm — a human expert needed ~12 h
Kali Linux Bootable USB for Ethical Hacking & Cybersecurity
Dual USB-A & USB-C Bootable Drive – works on almost any desktop or laptop (Legacy BIOS & UEFI)….
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
When does this land in an open model?
Everything above lives in closed models — gated, monitored, with safeguards. Open weights have none of that. Chinese open-weight labs have collapsed the coding gap; the agentic gap is closing next. Nobody knows the lag. Move the slider to your own estimate.
Diffusion clock — closed → open parity
As open models approach today’s closed-frontier cyber bar, the defender preparation window shrinks. Where do you put the lag?

McAfee Total Protection 3-Device | AntiVirus Software 2026 for Windows PC & Mac, AI Scam Detection, VPN, Password Manager, Identity Monitoring | 1-Year Subscription with Auto-Renewal | Download
DEVICE SECURITY – Award-winning McAfee antivirus, real-time threat protection, protects your data, phones, laptops, and tablets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Best tools, worst coverage — everywhere
A sober read across four regions. Note the pattern: the places with the best defensive tooling still have the weakest coverage of the long tail — and the long tail is exactly what an autonomous attacker farms.

AI In Cybersecurity: Simplifying Cyber Risk with Smart, Affordable Tools for Small Business Defense
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Defense scales the same way offence does
The genuinely hopeful thread: defenders get the tool first — they own the source, the test rigs and Trusted-Access. Mozilla is the proof. The work is unglamorous and known.
Patch fast and universally
Automated attackers win on the long tail of unpatched systems. Prepare for “patch-wave” surges.
Run frontier models on your own estate
Find your bugs before someone else’s model does. Self-verifying harnesses kill false positives.
Log everything, gate credentials
Comprehensive logging makes abuse visible; tight access control limits lateral movement.
Treat evaluations as early warning
AISI-style model evals are infrastructure, not press releases. Fund resilience before the clock runs out.
This is the moment defenders finally get ahead of a problem that has favoured attackers for 30 years. Source access plus first-mover tooling is a real, durable advantage.
Open weights have no rate limit, no monitoring and no off-switch. The day capability lands there, the advantage transfers wholesale to anyone with a GPU.
What Mozilla actually did
Start with the optimistic side, because it is real and it matters.
Mozilla’s engineers described an agentic pipeline built around Anthropic’s Claude Mythos Preview that does something earlier attempts couldn’t: it writes and runs its own test cases to prove a vulnerability exists before reporting it. Of the 423 bugs fixed across Firefox 150 and its point releases, 271 were attributed directly to Mythos Preview. Another 41 came from external researchers, and the remaining ~111 from a mix of traditional fuzzing and other models in the same harness.
The breakthrough was not raw intelligence. It was self-verification. Mozilla’s team had tried read-only static analysis with GPT-4 and Claude Sonnet 3.5 and drowned in false positives — plausible-sounding findings that wasted engineer time. The fix was to give the model the ability to build a reproducible proof-of-concept that either trips AddressSanitizer or doesn’t. Plausible became demonstrable. Once that worked, the team parallelized across ephemeral virtual machines, one file per machine, and let the pipeline handle triage, deduplication and fix-tracking end to end.
What it found should unsettle anyone who thinks “mature codebase” means “safe codebase.” The bugs span two decades of Firefox — including a 20-year-old XSLT flaw and a 15-year-old bug in the HTML element — surviving years of fuzzing, static analysis and human review. This was a preview of the same dynamic from March, when Claude Opus 4.6 found 22 vulnerabilities in two weeks, 14 of them high-severity: nearly a fifth of all high-severity Firefox bugs patched in the whole of 2025.
This is the genuinely good news. A defender pointed a frontier model at its own code and hardened it at a scale no human team could match. Hold onto that, because it is the strongest argument that the future is survivable.
The same blade, turned around
Now the other edge.
The AI Security Institute’s evaluation of an early GPT-5.5 checkpoint is the cleanest public measurement we have of offensive capability, and it is sobering precisely because AISI is careful. On their Expert-tier capture-the-flag tasks — reverse-engineering stripped binaries, weaponizing memory-corruption bugs, breaking misused cryptography — GPT-5.5 scored a 71.4% average pass rate, narrowly ahead of Mythos Preview’s 68.6%, with GPT-5.4 and Claude Opus 4.7 trailing in the low fifties. A year earlier, no model could complete an Expert task at all.
What the UK’s AISI actually measured
The capability that hardened a browser also runs offence. On the AI Security Institute’s hardest evaluations, frontier models now chain full multi-step intrusions — and compress expert reverse-engineering from hours into minutes.
Pass rate on Expert-tier cyber tasks · 50M token budget
rust_vm reverse-engineered — a human expert needed ~12 h, for $1.73 in API21 Expert tasks · error bars roughly ±8–10 points, so GPT-5.5 and Mythos Preview sit within each other’s range — read it as a tier, not a podium. Source: UK AI Security Institute, April 2026.
One example does more than the averages. A Crystal Peak Security challenge called rust_vm asks the solver to reverse-engineer a custom virtual machine from a stripped Rust binary, build a disassembler, recover a password-check algorithm and solve for a valid input. Their expert playtester needed about 12 hours, armed with Binary Ninja, gdb and an SMT solver. GPT-5.5 solved it in 10 minutes and 22 seconds, unaided, for $1.73 in API usage. Not a toy — a genuine reverse-engineering chain, compressed by two orders of magnitude in time and roughly four in cost.
Then there is “The Last Ones,” AISI’s 32-step simulated corporate intrusion built with SpecterOps — reconnaissance, credential theft, lateral movement across Active Directory forests, a CI/CD supply-chain pivot, and exfiltration of a protected database. A human expert is estimated to need around 20 hours. Mythos Preview was the first model to complete it end-to-end (3 of 10 attempts); GPT-5.5 became the second (2 of 10). And performance keeps climbing with the compute budget — AISI has not yet seen a plateau.
Two honest caveats sit alongside this, and the responsible reading keeps both in view. First, these ranges lack the active defenders, alerting and incident response of real networks; AISI is explicit that they cannot yet say how these models fare against a well-defended target, and no model has solved their industrial-control-system range. Second, public deployments ship with safeguards. But AISI’s red team found a universal jailbreak in about six hours of effort that elicited violative content across the malicious-cyber queries they tested. Safeguards are a speed bump, not a wall — and they are a property of the deployment, not the model.
That distinction is the whole argument.
The diffusion clock nobody can read
Everything above lives in closed frontier models — Mythos Preview, GPT-5.5 — reached through monitored APIs, rate limits and Trusted-Access programmes. The safeguards AISI bypassed in six hours still raise the cost of misuse, and the logging gives defenders a fighting chance to notice abuse. That control surface is the single biggest thing standing between today’s offensive capability and its worst-case use.
It is also temporary.
Look at where open weights actually are in mid-2026. Chinese open-weight providers now account for more than 45% of the tokens flowing through OpenRouter, up from under 2% a year ago. DeepSeek shipped its V4 architectural reset on April 24; Alibaba’s Qwen 3.6 and Moonshot’s Kimi K2.6 landed days earlier; Zhipu’s GLM 5.1 was trained end-to-end on domestic Huawei Ascend silicon. On coding and competitive-programming workloads, the gap to closed frontier has, for practical purposes, closed.
The nuance matters, and the optimists are partly right: the gap is not uniform. Independent trackers still put closed models ahead by several points on the hardest reasoning benchmarks, and — most relevant here — on long-horizon agentic evaluation, which is exactly the muscle that drives multi-step intrusion. Offensive cyber is a chaining problem, and chaining is the last thing to transfer. So the open frontier is closer on the skills that helped Mozilla and further on the skills that drive “The Last Ones.”
But “further” is a moving target, and the trendline has only one direction. The marketing copy says the gap shrank “from months to days.” That is hype. The defensible version is worse, because it is honest: nobody knows the lag. It could be eight months. It could be much shorter. Open weights have no rate limit, no monitoring, no Trusted-Access list and no off-switch. The day a downloadable model clears the agentic bar that GPT-5.5 just cleared, every safeguard discussed above becomes optional for whoever holds the weights. The clock that starts that day is the one defenders should be building against now — and it is the one almost nobody is explicitly counting.
Who is ready — Germany, Europe, Asia, North America
Against that clock, here is a sober reading of preparedness. None of these regions is “ready”; they are unready in different ways.
Germany has strong institutions on paper — the BSI, mandatory baseline standards, real cyber-defense expertise. The weakness is the Mittelstand: hundreds of thousands of mid-sized firms and sole-trader Gewerbe with no security staff, running exactly the kind of weakly-defended estate AISI’s ranges model. NIS2 transposition has been slow, GDPR caution can paradoxically slow defensive AI adoption, and “patch hygiene across the long tail” is precisely where an automated attacker wins.
The European Union has more cyber regulation than anywhere — NIS2, the Cyber Resilience Act, the AI Act. Density is not the problem; fragmented, lagging implementation across 27 member states is. A continent-wide patch-wave response requires coordination the EU has historically achieved slowly, and the attacker’s tempo is set in minutes.
Asia is the widest spread on Earth. Singapore and Japan run mature national programmes; much of the region runs almost none. Asia is also closest to the open-weight source — the most capable downloadable models are being built there — which compresses the diffusion lag for the surrounding region toward zero.
The United States and Canada hold the strongest hand and the most exposure. The leading labs and the best evaluation capacity (CISA, the US CAISI, AISI’s partners) sit here, which means defenders get first access to frontier tooling — the Mozilla path, at national scale. But regulation is a patchwork, critical infrastructure is privately held and unevenly secured, and the same border-free internet that delivers defensive models delivers offensive ones.
The pattern across all four: the places with the best tools still have the worst coverage of the long tail, and the long tail is what an autonomous attacker farms.
What actually helps, inside the window
The genuinely hopeful thread running through all of this is that defense scales the same way offense does. Mozilla is the proof. The asymmetry attackers enjoy — cheap, parallel, tireless probing — is available to defenders first, because defenders have the source code, the test infrastructure and a head start through Trusted-Access programmes.
So the work is unglamorous and known. AISI and the NCSC keep pointing at the same boring fundamentals because they are what an automated attacker actually defeats: fast, universal patching; tight access controls and credential hygiene; comprehensive logging so abuse is visible; and — the new item — running frontier models against your own estate before someone else runs theirs against it. Governments can shorten the window’s downside by funding resilience (the UK just committed £90m), preparing for “patch-wave” surges, and treating model evaluations as early-warning infrastructure rather than press releases.
The two views worth holding at once: this could be the moment defenders finally get ahead of a problem that has favored attackers for thirty years — or it could be the moment the advantage transfers wholesale to anyone with a GPU and a downloaded model. Which one we get is not decided by the models. It is decided by what we do in the months we cannot precisely count, before the choice is made for us.
The clock is already running. We just can’t see the face.
Sources: Mozilla Hacks (April 2026 Firefox security writeup); UK AI Security Institute evaluations of GPT-5.5 and Claude Mythos Preview cyber capabilities; OpenRouter / open-weight market analyses, May 2026. Figures are current as of publication and will move quickly.