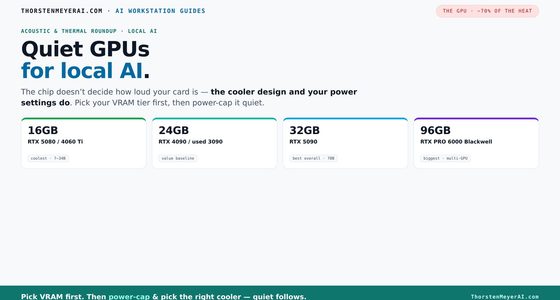
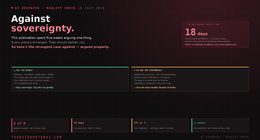
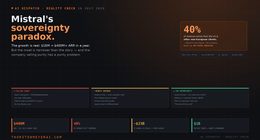
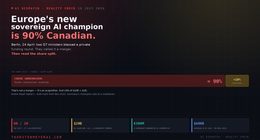
Claim under scrutiny. The paper makes a bold, plausible claim—that video generators are on a path to general‑purpose vision. This essay examines what’s missing, what levers matter, and what a principled roadmap might look like, based on the authors’ own cautions, failure cases, and prompting analyses. Video models are zero-shot lear…
Lower‑bound performance—and why it matters
The authors emphasize that the reported numbers are lower bounds: many tasks admit multiple visual formulations and prompts; the “right” visual + text prompt can unlock markedly better behavior (pp. 9–10). In practice, this means capability ≠ score: a weak prompt can hide real competence, and conversely, a cleverly staged prompt can inflate scores without robust generalization. The paper’s explicit split between best‑frame and last‑frame, and the consistent pass@k gains with more attempts, underline that evaluation protocols (frame selection, sampling budgets) can swing outcomes. For deployed systems, stable last‑frame metrics and standardized sampling budgets will be crucial for fair comparisons. Video models are zero-shot lear…
Prompting as control—and as confound
A key lever is visual + textual prompt engineering. The prompt sensitivity study (Table 2, p. 40) on symmetry shows pass@1 differences of 40–64 points across prompt variants—before any weight updates. Best practices the authors distilled include: remove ambiguity; explicitly state what must not change; provide a “motion outlet” to counter Veo’s bias to animate; allow the model to signal completion (e.g., a glowing dot); constrain camera motion; and tune speed (instant vs stepwise updates). Notably, a simple visual prior (green background) lifted segmentation mIoU (Figure 4, p. 6), hinting at learned production priors (e.g., green screens). This is power—but also a confound: when “prompt artistry” is a large fraction of performance, scientific claims must rigorously control for it. Video models are zero-shot lear…
Black‑box composition with an LLM rewriter
Because the Vertex pipeline includes an LLM-based prompt rewriter, some wins (like toy Sudoku) may owe more to language planning than visual reasoning (p. 2 & p. 3). The authors mitigate this by showing that a standalone LLM struggled to solve certain image‑only tasks (e.g., maze/symmetry/navigation), but clean ablations would isolate contributions more sharply (e.g., disabling the rewriter; comparing identical prompts across modes). For the field, this highlights a looming audit need: attribution (which subsystem did the work?) and control (can we deliberately route tasks to the most reliable subsystem?). Video models are zero-shot lear…
Systematic weaknesses and failure types
The failure gallery (pp. 42–46) is as instructive as the successes:
- Geometric/metric understanding. Depth and surface‑normal estimation are unreliable (Figures 62–63); reflections/rotations in analogies trend below chance (Figure 9, p. 8; Figure 61, p. 38), suggesting brittle coordinate‑frame reasoning.
- Controllability via annotations. “Force prompting” and prescribed motion trajectories often fail (Figure 64, p. 42), limiting precise planning/control use cases.
- Text and symbolic structure. Word search and equation solving lead to hallucinations (Figures 67 & 69, pp. 43–44), implying that tight symbolic constraints remain hard in a purely generative, vision‑first loop.
- Physics and contact. Collisions, breaking, bottlenecks, and knot‑tying are frequently implausible (Figures 72–75, pp. 44–45); cloth manipulation (folding a shirt) breaks (**Figure 76, p. 45**) and rigid‑body constraints are violated in “sofa through door” (Figure 77, p. 46). Video models are zero-shot lear…
These patterns suggest where data, objectives, and interfaces need to evolve: better metric supervision (3D, depth, normals), contact‑rich physics priors, and instruction channels that the generator reliably obeys.
What the quantitative trends imply
Two consistent findings matter for roadmap planning:
- Scale and recency help. Veo 3 outperforms Veo 2 widely (e.g., mazes, symmetry, editing), echoing the “bigger/ newer is better” curve that carried LLMs into general‑purpose territory.
- Test‑time compute buys quality. pass@10 ≫ pass@1 in many plots (e.g., edges, segmentation, mazes; Figures 3–7, pp. 5–7), inviting classical “sample‑and‑select” strategies, self‑consistency, and verifier‑guided reranking to lift reliability without retraining. Video models are zero-shot lear…
A practical research agenda
Grounded in the paper’s insights, a near‑term agenda could include:
- Evaluation protocols: Standardize last‑frame scoring, fix seeds and sampling budgets, and include “prompt‑ablations” (vary camera wording, speed, and “what not to change”) to measure robustness to prompt drift. (The symmetry study on p. 40 is a great template.) Video models are zero-shot lear…
- Interfaces for control: Improve adherence to force/trajectory overlays (Figure 64, p. 42) by adding explicit control channels or cross‑modal loss terms that penalize deviations. Video models are zero-shot lear…
- Physics & contact curricula: Incorporate contact‑rich scenes with verifiable outcomes (breakage, friction cones, incompressibility) to reduce violations seen in Figures 72–77. Video models are zero-shot lear…
- Attribution & ablation: Run with/without the prompt rewriter; log rewriter edits; report performance under “no prompt rewrite” and “LLM‑only planning” to quantify each part’s contribution. (Method notes on p. 2 acknowledge this composition.) Video models are zero-shot lear…
- Verifier‑in‑the‑loop: For tasks with crisp constraints (mazes, symmetry, analogies), integrate lightweight visual verifiers to select the best sample among multiple attempts, converting the clear pass@k headroom into reliable one‑shot success. (The paper’s best‑vs‑last framing already motivates this.) Video models are zero-shot lear…
- Visual prompt engineering: Systematically study visual prompt priors (e.g., backgrounds, lighting, gridlines) just as LLMs benefited from textual prompt taxonomies. The green‑screen advantage in segmentation (p. 6) is a concrete empirical clue. Video models are zero-shot lear…
Economics and adoption
The authors note that video generation is currently costly, but argue that inference costs tend to fall rapidly—invoking the LLM trajectory where generalist models eventually displaced many bespoke systems (pp. 9–10). If costs keep dropping while breadth and controllability rise, it becomes rational to prefer one well‑steered generalist over a zoo of specialists—especially for edge‑case coverage and maintenance simplicity. Video models are zero-shot lear…
Bottom line. The paper is persuasive that something new is happening: a single video model, prompted well, already covers surprising ground. Yet the path to “foundation model for vision” runs through control, physics, metrics, and evaluation discipline. With those levers tightened, the paper’s “chain‑of‑frames” intuition—reasoning by acting across space and time—could become not just a clever metaphor but a reliable operating principle. Video models are zero-shot lear…

Mastering Prompt Engineering for AI Success: How to Communicate with AI Models Like ChatGPT, Claude & Gemini to Multiply Productivity, Creativity & Business Impact
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.

Visual Perception Training Flash Card ‡@ Visual Reasoning Card Animal Destined
- Shipping Origin: Ships from Tokyo, Japan
- Delivery Time: Arrives in 10-17 business days
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.

AI and Machine Learning for Coders: A Programmer's Guide to Artificial Intelligence
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.

Spreadsheet Modeling & Decision Analysis: A Practical Introduction to Management Science
- Condition: Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.