
Thorsten Meyer AI Foundations · 03 / 08
The shape of AI capability — and why “smart” is the wrong axis
A model drafts a passable legal brief. Asked how many words are in it, the model is off by 30%. The same model, same session, writes working production code in the middle of the brief.
This isn’t a bug. It’s the shape of the thing.
Almost everyone — optimists and skeptics — reaches for the same mental model when they think about AI: a dumb-to-smart line where each generation nudges forward and someday reaches or passes human. It’s a clean picture. It’s also wrong in a way that matters, because decisions built on it get a specific kind of surprised.

Capability isn’t graded. It’s jagged.

AI-Assisted Coding: A Practical Guide to Boosting Software Development with ChatGPT, GitHub Copilot, Ollama, Aider, and Beyond (Rheinwerk Computing)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The jagged frontier
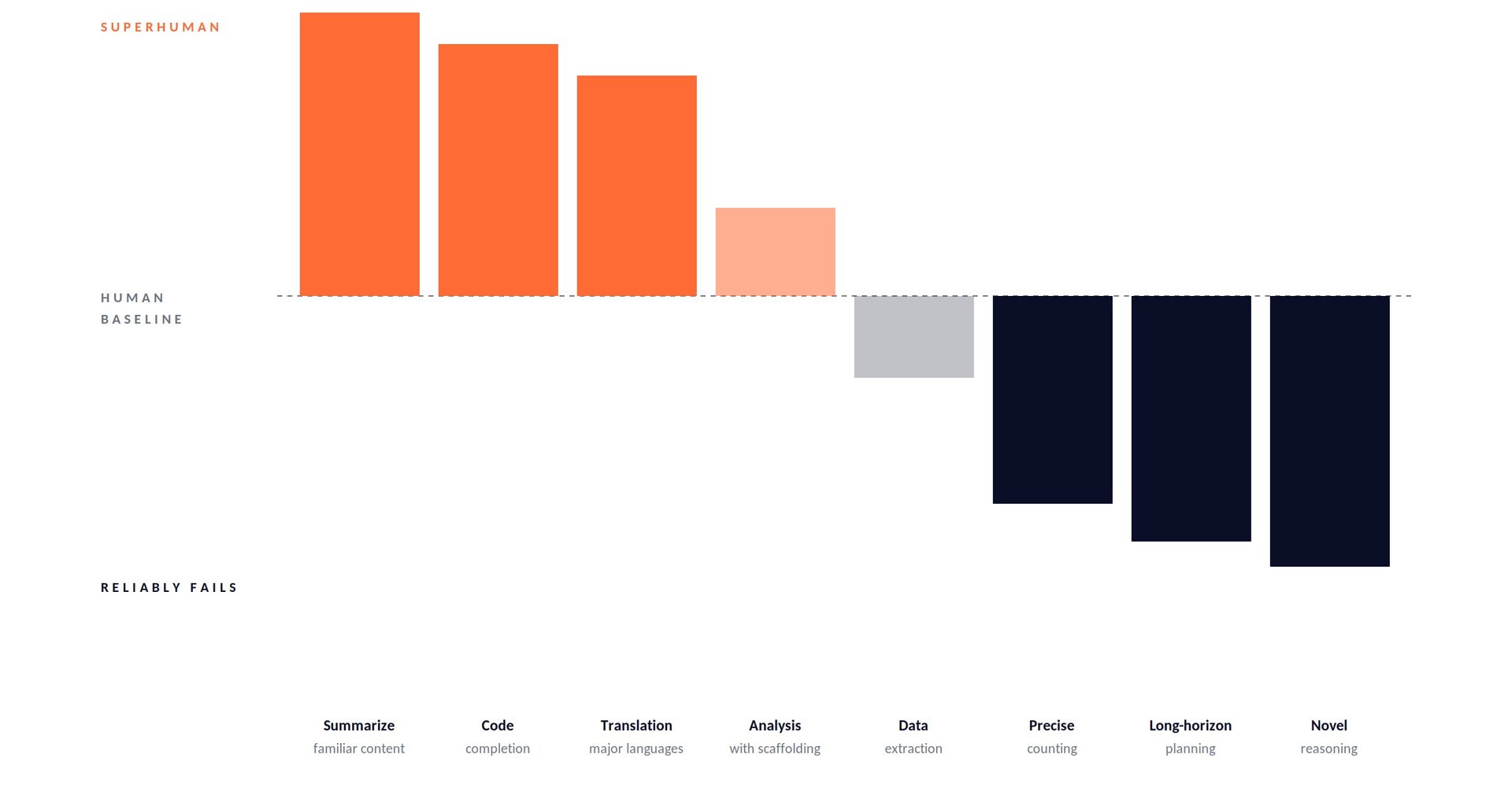
Picture a skyline instead of a line. Some peaks tower well above human baseline — synthesis, language generation, translation, code completion, summarization of familiar material. Some valleys sit well below — precise counting, long-horizon planning, novel mathematical reasoning, reliable arithmetic without tools, operating in genuinely out-of-distribution territory.
The peaks and valleys sit next to each other. They don’t move together. When a new model releases, some peaks rise dramatically while adjacent valleys barely budge. A model that writes a short story an editor would accept can fail at counting the paragraphs in it. A model that solves Olympiad-level math problems can stumble on a logic puzzle a ten-year-old would get.
The useful frame is: capability is a profile, not a score. Ask what a model is good at, not how smart it is.

AI Wearable Translator English Spanish Voice Translation Device,Black
- Real-Time Voice Translation: English-Spanish with 165 language support
- AI Language Learning: Practice conversations and pronunciation
- Compact & Portable: Fits easily in pocket or bag
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why jagged, not smooth
Three forces make the frontier jagged and keep it that way.
Training distribution. Models learn from the statistical structure of what they’re trained on. Tasks that are well-represented in training data — writing emails, summarizing articles, completing code that looks like GitHub — become peaks. Tasks that are rare or structurally different from the training distribution — reasoning about genuinely novel situations, doing arithmetic that requires step-by-step manipulation of digits — stay valleys. This isn’t a temporary artifact. It’s what next-token prediction does.
Task structure. Some tasks tolerate approximation; others don’t. “Write a plausible paragraph about X” has a wide space of acceptable answers, and models excel at producing plausible text. “Count the r’s in strawberry” has exactly one correct answer and no room for plausibility. Models trained to produce likely-looking output are well-matched to fuzzy tasks and badly matched to precise ones. Adding tools (calculators, code interpreters, search) can move specific valleys — but the underlying mechanism that creates the jaggedness doesn’t disappear.
Error compounding. For single-step tasks, a model that’s right 95% of the time is useful. For ten-step tasks, 95% per step compounds to about 60% end-to-end. For hundred-step tasks, it collapses entirely. This is why you’ll see models that feel brilliant in single-turn demos and frustrating in long agentic workflows — the capability didn’t change, but the number of steps did, and jaggedness shows up as error compounding across a chain.

Updated ChatGPT Made Simple for Beginners and Seniors: A Step-by-Step Guide to Writing Better, Finding Answers, Creating Images, Organizing Tasks, … … Productivity (REVISED AND UPDATED GUIDES)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
The capability bands
Within the jaggedness, there are useful regularities. Three bands are worth naming.
Peaks: the model is reliably superhuman or near-superhuman. Drafting, translation, summarization of familiar material, generating plausible text in a register you specify, code completion for well-known patterns. These are tasks you delegate. You still review, but the default is ship-it-then-check.
Workable: the model is useful with scaffolding. Most analysis tasks, most structured reasoning, most domain-specific work. Raw, the output is inconsistent. Scaffolded with examples, tool access, retrieval, or explicit step-by-step structure, the model becomes reliably useful. These are tasks you build systems around, not tasks you delegate blind.
Valleys: the model reliably fails without external help. Precise counting. Arithmetic that requires step-by-step manipulation. Long-horizon planning across many interdependent steps. Novel reasoning in unfamiliar domains. Tasks that require ground truth the model doesn’t have. These aren’t prompt-engineering problems. They’re architectural problems — either give the model tools (code, search, calculators) or don’t use a model at all.
A useful habit: before committing to using AI for a task, ask which band you think the task sits in. Then test it. The answer matters more than whether the task feels “like the kind of thing AI should be good at.”

Mathematical Logic and AI Reasoning Foundations Formal Methods & Automated Theorem Proving VOL-2
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Benchmarks lie — specifically
Benchmarks compress the whole skyline into a single number. That compression is always lossy, and often misleading.
A model can score 90% on a broad benchmark by crushing the peaks and partly failing on the valleys. A different model can score 88% by being more uniform across the profile. On the benchmark, model A looks better. On your workload, if your tasks happen to land in the areas where model A’s valleys are, model B will feel like a different generation of technology.
The problem isn’t that benchmarks are dishonest. It’s that they answer a question you probably aren’t asking. They answer: averaged across this task distribution, how did the model do? You usually want to know: on the tasks I actually care about, how will it do? These are different questions with different answers.
Probing your own frontier
The fix is almost embarrassingly simple: build a private benchmark from tasks that matter to you, and run it against every model you’re considering.
Five or six tasks is enough. Drawn from real work, not synthetic. Each task should have a clear definition of success — not just “did it give a plausible answer” but “did it give the right answer, or close enough to be useful.” Each should be runnable in under a minute. The whole suite should take under an hour to run end-to-end.
Then, run it every time you evaluate a new model. Log the results. Over time you’ll build something more valuable than any public leaderboard — a map of how different models perform on the tasks that actually pay your bills.
The suite doesn’t need to be fancy. Mine includes things like: summarize this dense technical document (peak), extract structured data from this messy email thread (workable), write a regex that matches these ten strings but not these ten (valley for most models, good proxy for precise tasks), plan a multi-step workflow and predict where it’ll go wrong (valley, excellent proxy for long-horizon reasoning).
You’ll be surprised how fast the frontier stops being abstract and starts being concrete.
What this changes operationally
Three things change once you accept jaggedness.
Strategy. Don’t plan on monotonic improvement. The common failure mode is building a workflow whose critical path sits in a valley and assuming the next model release will lift it into the peaks. Sometimes it does. Often it doesn’t. Plan for jaggedness by designing workflows where the AI sits on peaks and the scaffolding covers the valleys — human review, tool calls, retrieval, hard-coded logic.
Procurement. “Which model is best” is the wrong question. “Which model is best for which tasks” is the useful one. Many serious AI stacks now route different task types to different models. The cost of that routing complexity is less than the cost of forcing every task through the same model’s profile.
Communication. When someone asks “is AI good at X,” the answer is almost never yes or no. It’s “peak, workable, or valley — and here’s what moves it.” This sounds like hedging. It isn’t. It’s being honest about the shape of the technology instead of flattening it into a headline.
Next in Thorsten Meyer AI Foundations: capability tells you what a model can do. How you ask still shapes the output enormously. Prompting, beyond the tricks.