Italy spent years building a European sovereign LLM from scratch. 2.5 trillion tokens, half Italian. 128 GPUs simultaneously on the Leonardo supercomputer. Truly-open weights and data. Then Minerva-3B scored 4.9% on the INVALSI Italian benchmark. The structural lesson is harder than either side of the European sovereign-LLM debate has been willing to surface.
By Thorsten Meyer — May 2026
In the first standalone essay of this track, I walked Duarte O.Carmo’s analysis of Portugal’s AMÁLIA model and extended his three hard questions into the broader European sovereign-LLM movement. The structural argument was that the AMÁLIA approach — continuation pre-training of EuroLLM with approximately 5.5% European Portuguese data in extended pre-training — leaves several important questions unanswered. This piece is the structural counter-case.
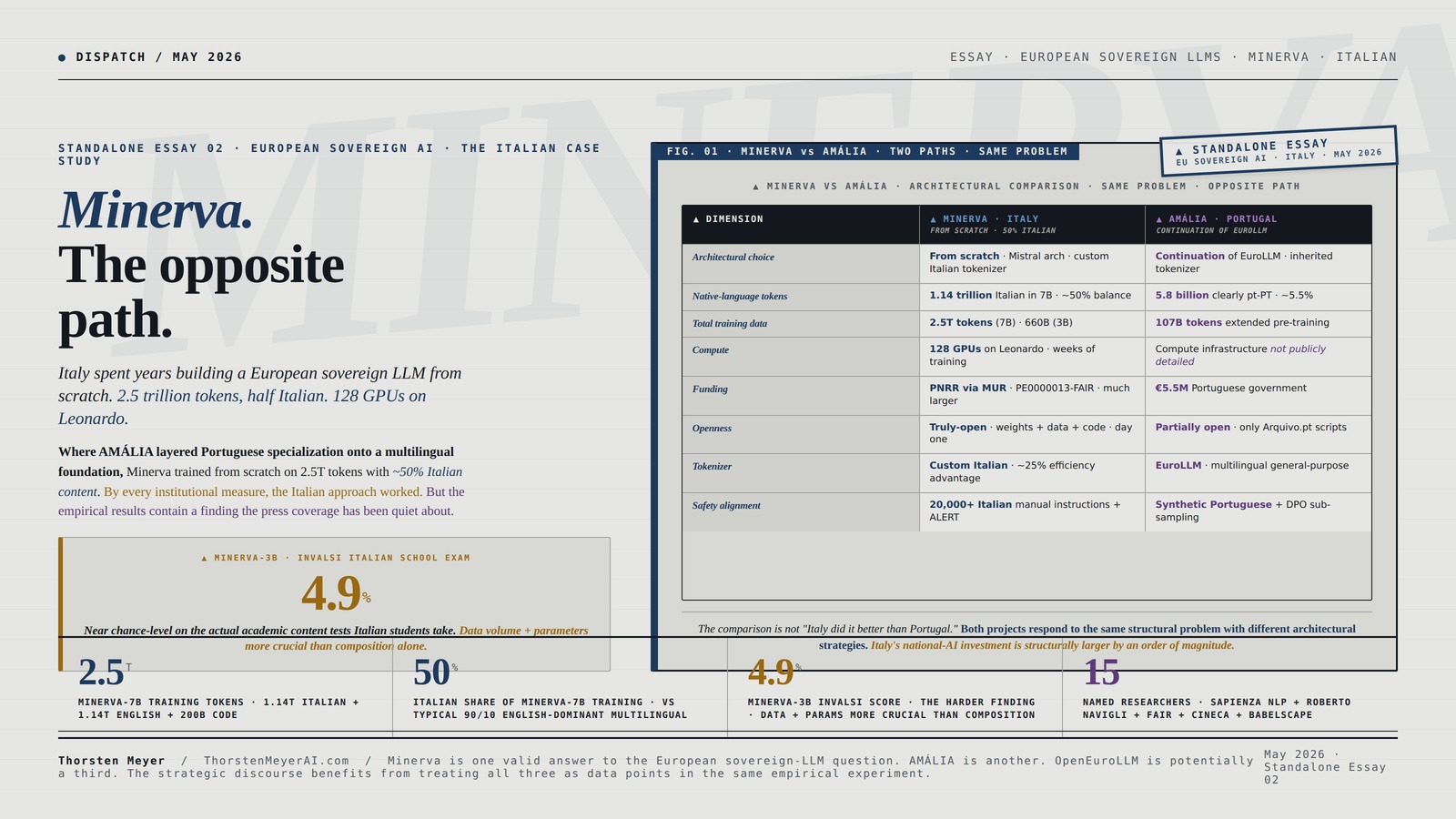
Italy’s Minerva is the European sovereign LLM project that chose the opposite architectural path. Where AMÁLIA layered Portuguese specialization onto a multilingual foundation, Minerva trained from scratch on 2.5 trillion tokens with approximately 50% Italian content. Where AMÁLIA’s weights are not yet public, Minerva published weights, training data, and code as truly-open from day one. Where AMÁLIA’s pt-PT share is structurally small in absolute terms, Minerva’s Italian token count is 1.14 trillion — three orders of magnitude larger than AMÁLIA’s pt-PT share. The Italian project went the long way around.
And it produced results that are simultaneously impressive and hard. The model family (350M to 7B parameters) outperforms comparable multilingual models on Italian benchmarks. The methodology has become a reference case for non-English LLM development. The institutional architecture — Sapienza NLP led by Roberto Navigli, FAIR consortium under Italy’s National Research Council, CINECA’s Leonardo supercomputer providing 128 GPUs simultaneously, PNRR funding through the national AI strategy — is a model of how European sovereign-AI infrastructure can actually function. By every institutional measure, the Italian approach worked.
But the empirical results contain a finding that complicates the simple narrative. Minerva-3B scored just 4.9% on the INVALSI Italian school-exam benchmark. This is not a marginal result. It is a structurally important data point: even an Italian model trained from scratch with 50% Italian data on 660 billion tokens performs near chance on the actual academic-content tests Italian students take. The researchers who ran that evaluation concluded that “while the pre-training dataset composition is important, the overall size of the dataset and the number of parameters are more crucial for handling complex language tasks.” This is the bitter lesson surfacing in sovereign-LLM context — and it has implications that extend well beyond Minerva.
The headline finding of this piece: Minerva and AMÁLIA together demonstrate that the European sovereign-LLM strategic question is not “from scratch or continuation” but “what scale of native-language investment is actually required to produce country-knowledge depth that justifies the national investment.” Italy made the larger investment and produced the more impressive technical artifact. The empirical results suggest the investment may still not be enough at the parameter scales these projects are operating at. The structural implication is that the European sovereign-LLM movement may need to internalize a harder scaling reality than either Minerva or AMÁLIA has publicly confronted.
This piece walks the Minerva project forensically, situates it as the structural counterpart to AMÁLIA, and surfaces the empirical finding that the press coverage has not foregrounded. The standard caveat applies: Minerva is an ongoing research project, the team continues iterating on the methodology (the 2025 continual-training case study is one example), and the structural critique is not directed at the work itself — it is directed at the level of public discourse around what the work actually demonstrates.
Minerva.
The opposite
path.
Italy spent years building a European sovereign LLM from scratch. Then Minerva-3B scored 4.9% on the INVALSI Italian school exam.
Where AMÁLIA layered Portuguese specialization onto a multilingual foundation, Minerva trained from scratch on 2.5 trillion tokens with approximately 50% Italian content. Where AMÁLIA’s weights are not yet public, Minerva published weights, training data, and code as truly-open from day one. By every institutional measure, the Italian approach worked. But the empirical results contain a finding the press coverage has been quiet about — and it has implications that extend well beyond Italy.
Same problem. Opposite path.
European sovereign-LLM development has two primary architectural approaches. Italy chose from scratch with substantial native-language foundation. Portugal chose continuation pre-training of a multilingual model. The structural comparison surfaces what each commitment actually requires operationally.
The comparison is not “Italy did it better than Portugal.” Both projects respond to the same structural problem with different architectural strategies under different institutional and economic constraints. Italy’s national-AI investment is structurally larger by an order of magnitude — and Minerva is the visible artifact of that scale.

ASRock Radeon AI PRO R9700 Creator 32GB Professional Graphics Card, 2920 MHz Boost Clock, GDDR6, AMD RDNA 4, AI-Accelerators, DisplayPort 2.1a, PCIe 5.0, Blower Cooler
Professional AI & Creator Workstation: AMD Radeon AI PRO R9700 GPU with 32GB GDDR6 is engineered for AI…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
4.9% on INVALSI. The bitter lesson surfaces.
In June 2024, researchers evaluated Minerva-3B on the Italian school-exam benchmark. The result was unambiguous. This is not a critique of Minerva — it is a critique of the public discourse around what Minerva’s empirical results actually demonstrate.

LARGE LANGUAGE MODELS SELBST PROGRAMMIEREN FÜR ENTWICKLER: Mit Python und PyTorch ein eigenes GPT-ähnliches Modell entwickeln, trainieren und … praxisnah und klar erklär (German Edition)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
350M to 7B. Four parameter scales, one architecture.
The Minerva model family covers four parameter tiers, each with specific training corpora. Each scale level reveals what the from-scratch path actually requires at different operating points.
Italian + English
100B English
~50% English
+ 200B code

High-Performance Computing and Artificial Intelligence in Process Engineering
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Three answers. Same question.
Minerva, AMÁLIA, and OpenEuroLLM represent the three operational answers to the European sovereign-LLM question. Each makes different architectural and institutional bets. The strategic discourse benefits from treating all three as data points in the same empirical experiment.

Large-Scale AI Engineering: Design, Train, and Optimize Foundation Models on NVIDIA GPU Clusters
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Three standards the movement should adopt.
The structural critique generalizes beyond Minerva. The European sovereign-LLM movement benefits from internalizing these lessons across every subsequent national project. Italy modeled the openness standard; the movement should adopt it as norm.
Minerva is one valid answer to the European sovereign-LLM question. AMÁLIA is another. OpenEuroLLM is potentially a third. The strategic discourse benefits from treating all three as data points in the same empirical experiment rather than as competing national-prestige projects. More analysis like this is needed. Not less.
I · What Minerva actually is · the institutional and technical foundation
The factual baseline before the structural argument. From the Minerva LLMs technical paper (Orlando et al., CLiC-it 2024), the Hugging Face model cards, the official Sapienza announcement, and the broader public record:
The institutional architecture
Minerva is led by Sapienza NLP, the Natural Language Processing research group at Sapienza University of Rome’s Antonio Ruberti Department of Computer, Control and Management Engineering (DIAG). The group is directed by Roberto Navigli, Full Professor and a globally significant figure in computational linguistics. The institutional umbrella is FAIR (Future Artificial Intelligence Research) — the project implementing Italy’s National Strategy for Artificial Intelligence, funded through the PNRR (Piano Nazionale di Ripresa e Resilienza, the post-pandemic recovery plan) under the MUR project PE0000013-FAIR. CINECA — Italy’s national supercomputing consortium — provided the compute infrastructure via the CINECA award “IscB_medit” under the ISCRA initiative.
The team that built Minerva 7B is specifically credited: 15 researchers and PhD students, alphabetically Edoardo Barba, Tommaso Bonomo, Simone Conia, Pere-Lluís Huguet Cabot, Federico Martelli, Luca Moroni, Roberto Navigli, Riccardo Orlando, Alessandro Scirè, Simone Tedeschi; with additional contributions from Stefan Bejgu, Fabrizio Brignone, Francesco Cecconi, Ciro Porcaro, and Simone Stirpe. Plus Giuseppe Fiameni (NVIDIA) and Sergio Orlandini (CINECA) for technical support. Babelscape provided additional research support. This is the named team — not a press-release abstraction, but the operational research group that did the work.
The release sequence
- April 23, 2024 · Initial preview release of Minerva 350M, 1B, and 3B base models to the FAIR scientific community
- November 26, 2024 · Minerva 7B base + instruct models publicly released — the “1.5 trillion words” milestone (which translates to roughly 2.5 trillion tokens in the actual training corpus)
- Late 2024 / early 2025 · Continued iteration on instruction tuning, safety alignment, and conversational capability
- 2025-ongoing · Continual training research extending Minerva-7B with additional Italian data recipes (per CLiC-it 2025 paper)
The model is publicly accessible at minerva-llm.org and minerva-ai.org. Weights are downloadable from Hugging Face under the sapienzanlp/ organization with model strings like Minerva-7B-base-v1.0, Minerva-7B-instruct-v1.0, Minerva-1B-base-v1.0, Minerva-3B-base-v1.0.
The technical specifications
The Minerva model family covers four parameter scales, each with specific training corpora:
- Minerva-350M · ~350 million parameters · base + instruct variants
- Minerva-1B-base-v1.0 · 1 billion parameters · trained on 200 billion tokens (100B Italian + 100B English) sampled from CulturaX
- Minerva-3B-base-v1.0 · 3 billion parameters · trained on 660 billion tokens with approximately 50% Italian data composition
- Minerva-7B-base-v1.0 · 7.4 billion parameters · trained on 2.5 trillion tokens (1.14T Italian + 1.14T English + 200 billion code tokens)
The architecture is based on Mistral 7B, with modifications to layer count, attention head structure, hidden size, intermediate size, key-value heads, sliding window length, and maximum context length scaled for each parameter tier. The tokenizer is custom — built for Italian text efficiency rather than retrofitted from an English-dominant base. This matters operationally: tokenizer fertility (the average number of tokens produced per tokenized word) is structurally lower for Italian text with Minerva’s tokenizer than with a Llama or generic multilingual tokenizer, which produces real efficiency gains during inference.
Training infrastructure: 128 GPUs simultaneously on CINECA’s Leonardo supercomputer, using llm-foundry 0.8.0 from MosaicML. The training process took several weeks. This is not abstract scale — it is real computational investment at the level required for frontier-adjacent model training.
The safety and alignment work
Minerva 7B’s instruct variant adds substantial post-training infrastructure:
- Supervised fine-tuning (SFT) on a mixed Italian-English instruction dataset, including manually curated Italian prompts, the everyday-conversations and Magpie datasets automatically translated to Italian using Unbabel/TowerInstruct-Mistral-7B-v0.2, and the HuggingFaceH4/ultrafeedback_binarized English data
- Direct Preference Optimization (DPO) with the Skywork/Skywork-Reward-Llama-3.1-8B-v0.2 model as the judge for Online DPO training. Prompts from ultrafeedback_binarized (English), efederici/evol-dpo-ita (Italian), and the Babelscape/ALERT Italian safety benchmark translated to Italian
- 20,000+ manually curated targeted instructions for Italian-specific safety alignment, addressing discriminatory or harmful response patterns specific to Italian language and cultural context
This is not token safety work. It is the kind of detailed alignment investment that requires deep Italian-language and Italian-culture expertise to do well. The Babelscape ALERT dataset specifically targets Italian safety scenarios that machine-translated English safety data would not surface. Italian safety alignment requires Italian researchers — and Minerva produced exactly that infrastructure.
The evaluation infrastructure · ITA-Bench
Minerva’s evaluation strategy is anchored on ITA-Bench, a suite of 18 benchmarks specifically created or curated by the Sapienza NLP team for Italian-language model evaluation. ITA-Bench covers scientific knowledge, commonsense reasoning, mathematical problem-solving, and Italian linguistic competence. The investment in building Italian-specific evaluation infrastructure is one of the structurally most important contributions of the Minerva project — it produces a public benchmark resource that subsequent Italian LLM efforts can use, regardless of whether they adopt Minerva’s architectural choices.
The team also tracks performance on translated standard benchmarks and Italian school-curriculum-style evaluations. This evaluation infrastructure is partially open — ITA-Bench results are reported in the technical paper, individual benchmark components are accessible through standard evaluation harnesses, and the methodology is reproducible.
II · The from-scratch strategic bet · what Italy actually committed to
The Minerva architectural choice deserves explicit articulation as a strategic bet, because it organizes everything else about the project.
The two paths · structurally articulated
European sovereign-LLM development has two primary architectural approaches, each with real trade-offs:
The continuation approach (AMÁLIA, partially EuroLLM’s own approach): Take an existing multilingual foundation model. Continue pre-training with additional native-language data. Apply specialized fine-tuning and preference training with native-language emphasis. The bet: native-language specialization can be layered on top of multilingual foundation without paying the full from-scratch training cost. Lower compute cost. Faster deployment. Benefits from multilingual foundation’s general capability.
The from-scratch approach (Minerva, partially OpenEuroLLM consortium): Train a new model from random initialization on native-language-heavy data. Build the tokenizer for the target language specifically. Treat native-language exposure as foundational rather than additive. The bet: native-language specialization requires native-language foundation, not native-language finetuning. Higher compute cost. Slower deployment. Deeper specialization potential.
Neither approach is wrong in principle. Both are valid strategies for national LLM development. They have different cost structures and different risk profiles. The continuation approach risks not producing sufficient specialization at the layered-on level. The from-scratch approach risks producing a specialized model that is competitive on native-language benchmarks but lacks the scale-derived general capability that frontier models achieve. Minerva and AMÁLIA represent the two paths in operational form.
What Minerva committed to operationally
Minerva’s commitment to the from-scratch path is not nominal — it shows up in every architectural choice:
Tokenizer: Custom-built for Italian, not retrofitted. The structural efficiency advantage shows up in real inference cost. Per third-party analysis, Italian text processes with approximately 25% token efficiency advantage compared to English-centric tokenizers. This is operationally meaningful — Italian-language deployment costs are structurally lower with Minerva than with a Llama-derived model.
Data composition: Approximately 50/50 Italian-English balance in the 7B model’s 2.5 trillion training tokens. Compare to typical multilingual models at 90% English / 10% everything else. This is not “Italian-aware multilingual” — it is Italian-coequal bilingual. The structural implication: Minerva models internal representations that treat Italian as a first-class linguistic citizen, not a fine-tuning afterthought.
Compute investment: 128 GPUs simultaneously on Leonardo for weeks to train Minerva-7B. This is not marginal compute. It is real scale that wouldn’t have been accessible without CINECA’s institutional commitment and FAIR’s PNRR funding. The Italian state effectively underwrote frontier-adjacent LLM training infrastructure to make Minerva possible.
Openness commitment: Weights, training data, code, and methodology are publicly accessible from day one. This is not the partial-openness situation AMÁLIA currently sits in. Minerva is “truly-open” in the operational sense O.Carmo argues “fully open source” should mean. Researchers can audit. Regulators can verify compliance. Organizations can reproduce. This is the openness standard the European sovereign-LLM movement collectively benefits from establishing.
The funding and institutional choice
The structural significance of FAIR + CINECA + PNRR cannot be overstated. Italy treated sovereign LLM development as a national infrastructure investment comparable to other strategic-technology projects. PNRR is post-pandemic recovery funding — it could have gone to many places. The MUR project PE0000013-FAIR specifically allocated substantial budget to Future Artificial Intelligence Research, which then allocated substantial budget to Minerva. This is the kind of multi-year institutional commitment that national LLM development requires and that few European nations have made at the same level.
By comparison: Portugal’s AMÁLIA at €5.5M is approximately one-fifteenth the scale of FAIR’s overall AI commitment, and a much smaller fraction once compute and infrastructure costs are amortized. Italy’s national-AI investment is structurally larger than Portugal’s by an order of magnitude, and Minerva is the visible artifact of that scale. The comparison is not about whether Portugal should match Italian investment levels — Portugal is a smaller country with a smaller language community. It is about whether the European sovereign-LLM movement’s strategic discourse has internalized what national-LLM development actually costs at the level required for the from-scratch path.
III · The harder finding · the INVALSI result and what it implies
Now the part of the Minerva story that the press coverage has been quiet about. This is not a critique of Minerva. It is a critique of the public discourse around what Minerva’s empirical results actually demonstrate.
The INVALSI benchmark and what happened
In June 2024, researchers published Disce aut Deficere: Evaluating LLMs Proficiency on the INVALSI Italian Benchmark (arXiv 2406.17535). INVALSI is the standardized assessment system that Italian students take in school — a real, content-rich, culturally-grounded evaluation specific to the Italian educational context. It is the kind of benchmark that measures exactly what European sovereign LLMs should be optimizing for: country-specific knowledge depth, Italian-language reasoning on Italian-curriculum content.
Minerva-3B was included in the evaluation. The result was unambiguous: Minerva-3B scored 4.9% on the INVALSI benchmark. This is approximately chance-level performance on a multiple-choice assessment with substantial guessing baseline. The researchers’ conclusion is worth quoting at length:
“Our tests revealed that Minerva-3B achieved a modest score of 4.9% on the benchmark, emphasising that while the pre-training dataset composition is important, the overall size of the dataset and the number of parameters are more crucial for handling complex language tasks.”
This is structurally important. The INVALSI researchers are not making a casual observation. They are pointing at one of the central scaling-law findings of modern LLM development: data composition is necessary but not sufficient; data volume and parameter count are the dominant variables for complex-task performance. A 3B-parameter model trained on 660B tokens — even 50% Italian — is structurally below the parameter and data-volume scale at which complex reasoning emerges reliably.
The bitter lesson · in sovereign-LLM context
Rich Sutton’s “Bitter Lesson” (March 2019) is the canonical articulation of this finding: methods that scale with computation and data tend to win over methods that incorporate human knowledge into model architecture. Decades of AI research have produced versions of this finding across multiple domains. The European sovereign-LLM movement is now producing its own version of the bitter lesson — and Minerva-3B’s INVALSI result is one of the cleanest empirical demonstrations.
The implication for sovereign LLM strategy: if the goal is country-specific knowledge depth at a level that competes with frontier models on actual content evaluations, the required investment is not just “more native-language data.” It is substantially larger parameter counts AND substantially larger training corpora AND substantially more native-language data within those larger corpora. The from-scratch path Italy took is structurally correct — and it may still not be sufficient at the parameter scales (3B-7B) most accessible to academic-consortium projects.
This generalizes uncomfortably. The continuation approach AMÁLIA took has the same problem at a different level. If 660B tokens with 50% Italian produces 4.9% on INVALSI, what does 107B tokens with 5.5% pt-PT produce on equivalent Portuguese-curriculum benchmarks? The AMÁLIA team has built pt-PT benchmarks, but a Portuguese-school-curriculum evaluation specifically would likely show similar structural results. The benchmark architecture itself becomes the structural question — and few sovereign-LLM projects have published results on national-curriculum benchmarks at the level INVALSI represents.
What Minerva-7B does and doesn’t change
Minerva-7B’s expanded parameter count (7B vs 3B) and training corpus (2.5T vs 660B tokens) should improve complex-task performance materially compared to Minerva-3B. And per the publicly reported benchmarks, it does. Minerva 7B is meaningfully more capable than the 3B variant on ITA-Bench and standard evaluations. Third-party reporting (which I treat with appropriate skepticism given the lack of primary peer-reviewed sources for some specific numbers) suggests MMLU scores around 82.4 and GSM8K around 89.2 — though Index.dev’s analysis that produces these numbers may be presenting aspirational or marketing-derived figures rather than peer-reviewed primary results.
The structural question is whether scaling from 3B to 7B closes the gap with frontier models on Italian-content evaluations. The Sapienza NLP team’s own framing on the official Minerva page is cautious and appropriate: “Minerva is primarily a language model and, while we worked on its conversational aspect, any comparisons with commercial chatbots, such as ChatGPT or Claude, should be taken with caution.” This is the honest framing. Minerva 7B is a substantial advance over Minerva 3B; it is not in the same capability class as GPT-5, Claude, or Gemini for general capability — and the team explicitly does not claim that it is.
The discourse gap
What the press coverage has been quiet about: the INVALSI finding for Minerva-3B has not been incorporated into the public narrative about Minerva’s success. Most coverage treats the project as a national triumph without engaging with the empirical finding that the smaller variants demonstrate structural scaling limits. Some coverage reports benchmark numbers for Minerva 7B without citing primary peer-reviewed sources for those numbers.
This is the same discourse pattern I flagged in the AMÁLIA piece. The European sovereign-LLM movement is operating with insufficient public discourse about what empirical results actually demonstrate. Press coverage emphasizes the institutional achievements (real and important) without surfacing the technical findings that complicate the simple narrative. The Sapienza NLP team themselves are appropriately careful about claims; the press coverage around their work is not.
IV · Minerva and AMÁLIA · the structural pairing
The two European sovereign-LLM projects deserve explicit comparative treatment, because together they bracket the strategic option space.
The institutional comparison
| Minerva (Italy) | AMÁLIA (Portugal) | |
|---|---|---|
| Lead institution | Sapienza NLP / FAIR consortium | NOVA / IST / IT / FCT consortium |
| Funding | PNRR via MUR project PE0000013-FAIR | €5.5M Portuguese government |
| Compute infrastructure | CINECA Leonardo (128 GPUs) | Compute infrastructure not publicly detailed |
| Team scale | 15 named researchers + PhD students + CINECA + NVIDIA + Babelscape | ~60 researchers across consortium |
| Architectural choice | From scratch on Mistral architecture | Continuation of EuroLLM |
| Native-language data | 1.14T Italian tokens (50% of 7B model) | 5.8B clearly pt-PT (5.5% of mid-training) |
| Total training data | 2.5T tokens (Minerva-7B) | 107B tokens (AMÁLIA extended pre-training) |
| Openness status | Truly-open (weights + data + code public) | Partially open as of mid-May 2026 (research-in-progress) |
| Tokenizer | Custom-built for Italian | EuroLLM tokenizer (not Italian-specific) |
| Evaluation infrastructure | ITA-Bench (18 Italian benchmarks) | Four new pt-PT benchmarks including ALBA |
| Safety alignment | 20,000+ Italian-specific instructions | Synthetic Portuguese data + DPO |
| Public release | April 2024 (preview), November 2024 (7B) | September 2025 (base), June 2026 (final target) |
The comparison is not “Italy did it better than Portugal.” Both projects are responding to the same structural problem with different architectural strategies under different institutional and economic constraints. Italy had access to PNRR funding at a scale Portugal did not. Italy had CINECA’s Leonardo infrastructure already operational. Italy had a longer institutional runway through FAIR. Each project optimized for what was actually feasible in its context.
The strategic positioning comparison
In my framework from the AMÁLIA piece, the four strategic positions for European sovereign LLMs were:
- Match the frontier on general capability (scale-investment dependent)
- Exceed on sovereignty/openness/compliance (regulatory-readiness dependent)
- Exceed on country-specific knowledge depth (data-investment dependent)
- Application specialization in regulated industries (vertical-integration dependent)
Minerva stakes a clear Position 2 + 3 combination. Truly-open data and model (Position 2 sovereignty/openness) plus substantial Italian-data investment with from-scratch training (Position 3 country-knowledge depth). The strategic commitment is operational — every architectural choice supports the dual positioning.
AMÁLIA sits between Positions 2 and 3 without clearly committing to either in current form. The June 2026 final release will determine which structural position AMÁLIA ultimately stakes.
The honest empirical comparison
But Position 3 — “exceed on country-specific knowledge depth” — has the harder empirical test, and the INVALSI finding for Minerva-3B is the first publicly documented evidence that even Italy’s substantial investment may not have been sufficient at the parameter scales the project is operating at. This is not a Minerva-specific finding. It is a sovereign-LLM-specific finding. It implies that Position 3 may require parameter and data scales that few European national projects can access individually — which is one of the structural arguments for the pan-European OpenEuroLLM consortium approach.
The structural lesson: the European sovereign-LLM movement may need to internalize that the country-knowledge-depth path requires either substantially more investment than individual national projects can sustain, or pan-European pooling of resources at the OpenEuroLLM scale, or both. Italy’s investment is closer to the threshold than Portugal’s — but both may be below the threshold at which the strategic positioning produces empirical results that justify the public investment.
V · What Minerva demonstrates that the press coverage misses
Beyond the INVALSI finding, several structural lessons emerge from a careful read of the Minerva project that the public discourse has been quiet about.
The institutional architecture is reproducible
FAIR + CINECA + Sapienza NLP is a template. The Italian institutional model — academic research group with deep linguistic expertise, paired with a national supercomputing consortium, funded through a national strategic-technology program — is structurally reproducible in other European nations. Germany has Max Planck Institutes and the Jülich Supercomputing Centre. France has Inria and the CINES/IDRIS infrastructure. Spain has BSC-CNS (Barcelona Supercomputing Center). The institutional pattern works. It produced Minerva. It can produce equivalent projects in other linguistic-cultural contexts where the political will and funding exist.
The structural recommendation: European sovereign-LLM strategy should learn from Italy’s institutional architecture, not just from Italy’s model outputs. The funding mechanism (PNRR), the compute access pattern (national supercomputing consortium with academic research priority), and the team composition (15 named researchers with deep linguistic and computational expertise) are the operational ingredients that produce sovereign LLMs at scale. Without these ingredients, sovereign-LLM ambitions remain rhetorical.
The tokenizer matters operationally
Minerva’s custom Italian tokenizer produces real efficiency gains — approximately 25% token efficiency advantage on Italian text per third-party analysis. This is not a benchmark-table number; it is an operational cost reduction that compounds over deployment. Sovereign-LLM projects that retrofit existing tokenizers leave structural efficiency on the table. The tokenizer decision is one of the earliest architectural choices in LLM development, and it has long-term implications for deployment economics. Minerva’s choice to build a tokenizer specifically for Italian is one of the most overlooked but operationally important decisions in the project.
For AMÁLIA, the structural implication: continuing from EuroLLM means inheriting EuroLLM’s tokenizer, which was designed for multilingual coverage rather than European Portuguese specifically. The token efficiency advantage Minerva achieves through custom tokenization is not available to AMÁLIA without significant additional work. This is one of the operational trade-offs of the continuation approach that the strategic discourse has not fully surfaced.
The safety alignment work is irreplaceable
The 20,000+ manually curated Italian-specific safety instructions Minerva developed cannot be machine-translated from English safety datasets without losing structural coverage. Italian discriminatory speech patterns, Italian cultural context, Italian-language jailbreak attempts — these require Italian researchers with Italian-language and Italian-culture expertise to identify and address. The Babelscape ALERT dataset and Minerva’s safety alignment work together represent a substantial Italian-language safety infrastructure investment that benefits every subsequent Italian LLM project.
This is the kind of work that justifies national LLM investment independently of model performance. Even if Minerva’s parameter scale produces empirical results that don’t compete with frontier models on Italian-curriculum benchmarks, the safety-alignment infrastructure produces public-goods value that doesn’t exist in any other form for Italian language. The European sovereign-LLM movement collectively benefits from national projects building this kind of infrastructure — and Italian researchers’ contribution to that infrastructure deserves recognition independent of capability-benchmark comparisons.
The continual training research is structurally important
The 2025 CLiC-it paper on continual training of Minerva — “What we Learned from Continually Training Minerva: a Case Study on Italian” — extends the project’s empirical contribution beyond the initial release. The team published three distinct data recipes for continual training, with detailed analysis of what works and what doesn’t. This is the kind of methodological transparency that advances the field, independent of the specific performance numbers.
Most sovereign-LLM projects do not publish continual-training methodology at this level of detail. Minerva’s commitment to ongoing methodology publication is a structural contribution that benefits every subsequent Italian and non-English LLM project. The Sapienza NLP team is treating Minerva as research infrastructure, not as a one-time deliverable — and this framing produces durable value.
VI · The closing argument · what Minerva should teach the European sovereign-LLM movement
Minerva is structurally important because it is what the from-scratch sovereign-LLM path actually looks like in operational form. By every institutional measure, the Italian approach worked. The team produced truly-open models with deep Italian-language specialization, custom tokenization, substantial safety alignment, and reproducible methodology. The institutional architecture (FAIR + CINECA + Sapienza NLP + PNRR funding) is a template that other European nations can adapt. The technical artifact is a public-goods contribution that benefits the broader research community independent of capability comparisons.
But Minerva also surfaces the harder lesson the European sovereign-LLM movement has been quiet about: even substantial investment in the from-scratch path may not produce country-knowledge-depth results that compete with frontier models at the parameter scales individual national projects can access. The INVALSI finding for Minerva-3B is structurally important. The implication for sovereign-LLM strategy is that Position 3 (exceed on country-specific knowledge depth) requires investment at scales that may exceed what individual European nations can sustain — pointing toward pan-European pooling through initiatives like OpenEuroLLM, or toward smaller specialized targets (Position 4 application specialization) rather than general country-knowledge depth.
Three structural recommendations emerge from the Minerva case study for the broader movement:
- Adopt Minerva’s openness standard as the operational norm. Truly-open weights + data + code from initial release. The European sovereign-LLM movement’s competitive position against US/Chinese frontier developers depends on operational openness being real, not just marketed.
- Publish national-curriculum benchmark results explicitly. INVALSI is the kind of evaluation the press coverage doesn’t engage with but that actually measures what sovereign LLMs should be optimizing for. Every European sovereign-LLM project should publish equivalent national-curriculum benchmark results. Sweden’s national exam. France’s baccalauréat. Spain’s selectividad. Portugal’s national exams. The benchmarks exist. The discourse needs to incorporate them.
- Be honest about scaling limits. Minerva-3B’s 4.9% on INVALSI is not a failure of the Minerva project — it is a structural finding about parameter and data scales that the entire European sovereign-LLM movement needs to internalize. The discourse around what individual national LLMs can and cannot achieve at currently-accessible scales should be substantially more rigorous than the press coverage has been.
For Italy specifically, Minerva’s trajectory deserves continued attention. The continual training research is ongoing. The team continues iterating on methodology. The June 2026 timeline that determines AMÁLIA’s strategic position has a parallel timeline for Minerva — the next-generation model that builds on what the team has learned. If Minerva-next produces materially stronger national-curriculum results at larger parameter scales, that is structurally important news. If it doesn’t, that is structurally important news too. Either way, the empirical results matter more than the institutional framing.
For the European sovereign-LLM movement broadly, Minerva is the case study that makes the cost-benefit reality of the from-scratch path operational. Italy paid the larger cost and produced the more substantial artifact. The question for every other European nation considering sovereign-LLM development is whether the from-scratch path is feasible at their funding scale, whether the continuation path can produce sufficient results at smaller investment, and whether pan-European pooling through OpenEuroLLM is the structurally correct alternative to both.
Minerva is one valid answer to the European sovereign-LLM question. AMÁLIA is another. OpenEuroLLM is potentially a third. The strategic discourse benefits from treating all three as data points in the same empirical experiment rather than as competing national-prestige projects. The questions are real. The answers are still being determined. The Sapienza NLP team’s work on Minerva is one of the most substantial contributions to that empirical experiment that European AI research has produced. It deserves the careful, rigorous, structurally honest discourse that O.Carmo’s analysis of AMÁLIA modeled — and that this piece has attempted to extend to Italy’s case.
That’s the read on Minerva. The work is real. The institutional achievement is substantial. The empirical findings are harder than the press coverage suggests. The European sovereign-LLM movement is in a moment that needs more analysis like this, not less. More of this is needed.
About the Author
Thorsten Meyer is a Munich-based futurist, post-labor economist, and recipient of OpenAI’s 10 Billion Token Award. He spent two decades managing €1B+ portfolios in enterprise ICT before deciding that writing about the transition was more useful than managing quarterly slides through it. More at ThorstenMeyerAI.com.
Related Reading · the European sovereign-LLM essay track
- AMÁLIA · The Three Hard Questions — Standalone Essay 01, the Portuguese case study
- This piece — Standalone Essay 02, the Italian case study
Sources
- Orlando et al. · Minerva LLMs: The First Family of Large Language Models Pretrained from Scratch for the Italian Language · CLiC-it 2024 · the primary technical paper
- Sapienza NLP · Minerva-7B-base-v1.0 · Hugging Face model card · base model
- Sapienza NLP · Minerva-7B-instruct-v1.0 · Hugging Face model card · instruction-tuned variant
- Sapienza NLP · Minerva-1B-base-v1.0 · Hugging Face model card · 1B parameter variant
- Sapienza Università di Roma · The Italian way to future chatbots · November 2024 · Minerva 7B release announcement
- Sapienza Università di Roma · AI made in Italy: here is Minerva · April 2024 · initial release announcement
- Fondazione FAIR · AI made in Italy: Minerva arrives · April 2024
- Babelscape · Minerva: Italy’s First Family of Large Language Models trained on Italian texts · December 2024
- minerva-llm.org · official Minerva project page at Sapienza NLP
- minerva-ai.org · public-facing demo and information site
- Minerva blog · training infrastructure and methodology details · including 128 GPU training, Online DPO with Skywork judge, ITA-Bench evaluation methodology
- Continual training research · What we Learned from Continually Training Minerva: a Case Study on Italian · CLiC-it 2025
- INVALSI evaluation · Disce aut Deficere: Evaluating LLMs Proficiency on the INVALSI Italian Benchmark · arXiv 2406.17535 · the structurally important empirical finding
- Wikipedia · Minerva (model) · public reference summary
- ITA-Bench evaluation suite · 18 Italian benchmarks created by Sapienza NLP team
- Babelscape/ALERT · Italian safety benchmark used in Minerva DPO training
- HuggingFaceH4/ultrafeedback_binarized · English instruction data used in SFT
- efederici/evol-dpo-ita · Italian DPO prompt dataset
- Skywork/Skywork-Reward-Llama-3.1-8B-v0.2 · DPO judge model
- Index.dev · Europe’s Leading LLMs · February 2026 · third-party benchmark numbers (treated with appropriate skepticism for unsourced specific values)
- Procmatech · Minerva 7B: Italy Challenges AI Giants · November 2024 · 20,000+ safety instructions detail
- MyNextDeveloper · Minerva 7B: Italy’s Answer to ChatGPT · August 2025
- Sutton, R. · The Bitter Lesson · March 2019 · canonical articulation of the scaling-vs-knowledge-encoding finding
- PNRR MUR project PE0000013-FAIR · Italian national AI strategy funding mechanism
- CINECA award “IscB_medit” under ISCRA initiative · compute allocation for Minerva
- Mistral architecture · base architectural template for Minerva models
- llm-foundry 0.8.0 from MosaicML · training framework used for Minerva-7B
- Roberto Navigli · Full Professor at Sapienza DIAG · CREATIVE PRIN project (PRIN 2020) additional funding
- Team credits · Edoardo Barba · Tommaso Bonomo · Simone Conia · Pere-Lluís Huguet Cabot · Federico Martelli · Luca Moroni · Roberto Navigli · Riccardo Orlando · Alessandro Scirè · Simone Tedeschi · Stefan Bejgu · Fabrizio Brignone · Francesco Cecconi · Ciro Porcaro · Simone Stirpe · Giuseppe Fiameni (NVIDIA) · Sergio Orlandini (CINECA)